

There is a disaster recovery plan in your organization, documented, approved, and never tested. The runbook exists, the backups run, the failover is designed, and whether any of it actually works is unknown, because the drill that would prove it is the one task that always gets deferred for something more urgent. The plan is a hypothesis, and the first real test of it will be a real disaster, the worst possible time to discover that the failover does not work, the runbook is stale, or recovery takes far longer than assumed.
This is more than a deferred task. It is a DR plan that is untested because the drill is the work most teams skip.
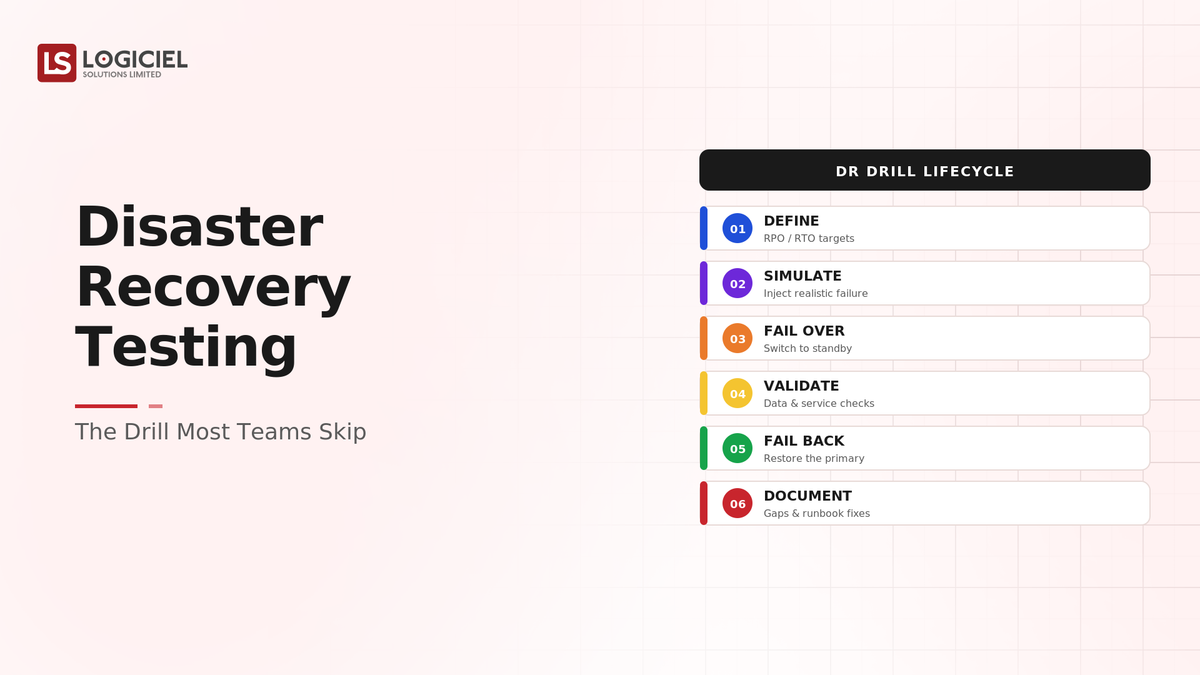
Disaster recovery testing is the drill that turns a DR plan from a hypothesis into a proven capability: regularly exercising the failover and recovery procedure to confirm it works, measure how long it takes, and surface the gaps, before a real disaster does. An untested DR plan is a plan you do not know works, and the only way to know is to drill it.
However, many teams document a DR plan and skip the testing, and discover during a real disaster that the untested plan does not work as assumed.
If you are a reliability or infrastructure leader responsible for DR, the intent of this article is:
- Define why DR testing is essential and why it is skipped
- Walk through regular drills and what they reveal
- Lay out how to make DR testing a routine
To do that, let's start with the basics.
Last-Touch Attribution Is Hurting Your Pipeline
A single attribution mistake led to a 22% pipeline drop. Here’s how real estate teams fix it with full-funnel visibility.
What Is Disaster Recovery Testing? The Basic Definition
At a high level, disaster recovery testing is regularly exercising the failover and recovery procedure to confirm it works, measure recovery time against objectives, and surface gaps, turning a documented DR plan into a proven capability.
To compare:
If a DR plan is a fire escape plan posted on the wall, DR testing is the fire drill that proves people can actually get out in time. The posted plan is a hypothesis; the drill is the proof, and the time to find a blocked exit is the drill, not the fire.
Why Is DR Testing Necessary?
Issues that DR testing addresses or resolves:
- Confirming the DR plan actually works
- Measuring recovery time against objectives
- Surfacing gaps before a real disaster does
Resolved Issues by DR Testing
- Turns an untested plan into a proven capability
- Measures real recovery time
- Surfaces gaps in drills, not disasters
Core Components of DR Testing
- Regular drills of failover and recovery
- Measurement of recovery time against RTO
- Gap identification and remediation
- Realistic test conditions
- Documentation updated from drills
Modern DR Testing Approaches
- Scheduled DR drills
- Failover testing
- Chaos and game-day exercises
- Recovery time measurement
- Post-drill review and remediation
These approaches make DR testing routine; the discipline is actually drilling, not deferring.
Other Core Issues They Will Solve
- Provide confidence the plan works
- Keep the runbook current
- Meet recovery objectives in practice
Importance of DR Testing in 2026
DR testing matters more as systems grow and recovery is expected to work. Four reasons explain why it matters now.
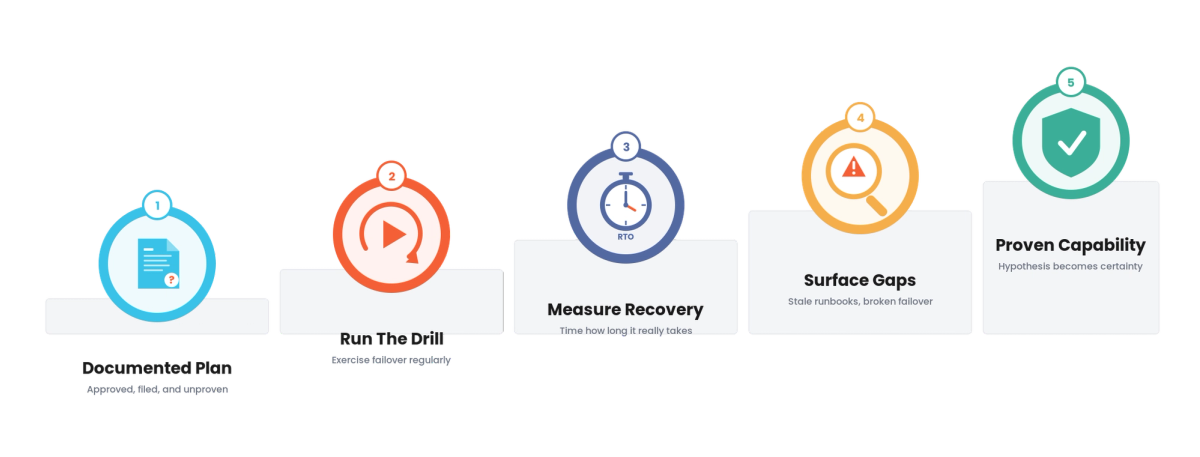
1. An untested plan is a hypothesis.
A DR plan never drilled is unproven. Whether it works is unknown until tested, and the first test should not be a real disaster.
2. The drill is what gets skipped.
DR testing is deferred for more urgent work, so it is the discipline most teams skip, leaving the plan untested.
3. Gaps hide until tested.
Stale runbooks, broken failover, and underestimated recovery time hide until a drill surfaces them. The drill is cheap; the disaster is not.
4. Recovery objectives must be proven.
RTO and RPO are commitments. Drills measure whether they are actually met, not just stated.
Traditional vs. Tested DR
- Documented plan vs. proven capability
- Untested hypothesis vs. drilled and confirmed
- Gaps found in a disaster vs. found in a drill
- RTO stated vs. RTO measured
In summary: DR testing turns a documented plan into a proven capability through regular drills that confirm it works, measure recovery time, and surface gaps.
Details About the Components of DR Testing: What Are You Doing?
Let's go through each element.
1. Drill Layer
Exercising recovery.
Drill decisions:
- Regular failover and recovery drills
- Scheduled, not deferred
- Realistic conditions
2. Measurement Layer
Time and objectives.
Measurement decisions:
- Recovery time measured
- Measured against RTO
- RPO data loss checked
3. Gap Layer
Finding the problems.
Gap decisions:
- Gaps surfaced in the drill
- Stale runbooks, broken failover found
- Remediation tracked
4. Realism Layer
Meaningful tests.
Realism decisions:
- Realistic test conditions
- Not a trivial happy-path test
- Failure scenarios exercised
5. Update Layer
Keeping it current.
Update decisions:
- Runbook updated from drills
- Plan kept current
- Learnings incorporated
Benefits Gained from DR Testing
- Confidence the DR plan actually works
- Recovery time known and meeting objectives
- Gaps found in drills, not disasters
How It All Works Together
DR drills are scheduled regularly and actually run, rather than deferred. Each drill exercises the failover and recovery procedure under realistic conditions, not a trivial happy path, and measures the recovery time against the RTO and the data loss against the RPO. Gaps, stale runbooks, broken failover, underestimated recovery time, surface in the drill, and remediation is tracked. The runbook and plan are updated from what the drill reveals. The DR plan becomes a proven capability with a known recovery time, because it was drilled, and when a real disaster comes, the recovery is rehearsed rather than a hypothesis tested for the first time under maximum pressure.
Common Misconception
We have a documented DR plan, so we are prepared.
A documented DR plan that has never been tested is a hypothesis, not a proven capability. Whether the failover works, the runbook is current, and recovery meets objectives is unknown until drilled. The first real test of an untested plan is a real disaster, the worst time to find it does not work.
Key Takeaway: A documented DR plan is not a proven one. The drill is what turns the plan into a capability you can trust.
Real-World DR Testing in Action
Let's take a look at how DR testing operates with a real-world example.
We worked with a team whose DR plan had never been drilled, with these constraints:
- Confirm the plan actually works
- Measure recovery time against objectives
- Surface gaps before a real disaster
Step 1: Schedule Regular Drills
Actually run them.
- Regular failover and recovery drills
- Scheduled, not deferred
- Realistic conditions
Step 2: Measure Recovery
Time and objectives.
- Recovery time measured
- Against RTO
- RPO checked
Step 3: Surface Gaps
Find the problems.
- Gaps surfaced in the drill
- Stale runbooks, broken failover found
- Remediation tracked
Step 4: Make It Realistic
Meaningful tests.
- Realistic conditions
- Failure scenarios exercised
- Not a trivial test
Step 5: Update the Plan
Keep it current.
- Runbook updated
- Plan current
- Learnings incorporated
Where It Works Well
- Regular, realistic drills run, not deferred
- Recovery time measured against objectives
- Gaps surfaced and the plan updated
Where It Does Not Work Well
- A documented plan never tested
- Gaps found in a real disaster
- Recovery time unknown until it matters
Key Takeaway: The DR plan you can trust is the one drilled regularly, with recovery time measured and gaps surfaced, not the documented plan that has never been tested.
Common Pitfalls
i) Skipping the drill
DR testing is deferred for more urgent work, leaving the plan untested. Schedule and run drills regularly.
- Schedule drills
- Run them, do not defer
- Make them realistic
ii) Trivial happy-path tests
A drill that tests only the easy path does not prove recovery. Exercise realistic failure scenarios.
iii) Not measuring recovery time
A drill that does not measure time against RTO leaves the objective unproven. Measure it.
iv) Not updating the plan
Drills surface gaps; if the plan is not updated, the gaps persist. Incorporate learnings.
Takeaway from these lessons: Most DR failures trace to skipping the drill, not to the plan. Schedule realistic drills, measure recovery, surface gaps, and update the plan.
DR Testing Best Practices: What High-Performing Teams Do Differently
1. Drill regularly, do not defer
Schedule DR drills and actually run them, since the drill is the discipline most teams skip.
2. Make drills realistic
Exercise realistic failure scenarios, not a trivial happy path, so the drill proves real recovery.
3. Measure recovery against objectives
Measure recovery time against RTO and data loss against RPO, so the objectives are proven, not just stated.
4. Surface and remediate gaps
Use drills to find stale runbooks, broken failover, and underestimated recovery, and remediate them.
5. Update the plan from drills
Incorporate drill learnings so the runbook and plan stay current and proven.
Logiciel's value add is helping teams make DR testing routine, regular realistic drills, recovery measurement, gap remediation, and plan updates, so the DR plan is a proven capability rather than an untested hypothesis.
Takeaway for High-Performing Teams: Focus on actually drilling. A documented DR plan is a hypothesis; regular, realistic drills that measure recovery and surface gaps turn it into a capability you can trust before a real disaster tests it.
Signals You Are Testing DR Correctly
How do you know the plan is proven? Not in its documentation, but in the drills. Below are the signals that distinguish a tested capability from a documented hypothesis.
Drills are run regularly. The team actually runs DR drills, not defers them.
Drills are realistic. Drills exercise realistic failure scenarios, not a trivial path.
Recovery is measured. Recovery time is measured against RTO and data loss against RPO.
Gaps are found and fixed. Drills surface gaps that are remediated.
The plan is updated. Drill learnings keep the runbook and plan current.
Adjacent Capabilities and Connected Work
This work does not exist in isolation. DR testing depends on, and feeds into, several adjacent capabilities. Building one without thinking about the others is the most common scoping mistake.
In most organizations, DR testing shares infrastructure with the backup and DR systems, the infrastructure-as-code that recreates environments, and the incident process. It shares capacity with SRE, infrastructure, and the application teams. And it shares leadership attention with whatever the next reliability initiative is on the roadmap. Naming these adjacencies upfront helps the program scope realistically and helps leadership see the work as a portfolio rather than a one-off project.
The most common mistake in adjacency-capability scoping is treating each adjacency as someone else's problem. The backups the drill relies on are your problem. The infrastructure-as-code that recreates the environment is your problem. The runbook updates are your problem. Pretending otherwise pushes work to teams that did not plan for it, and the work returns to you later as a failed recovery. Own the adjacencies you depend on; partner with the teams that own them; share the timeline.
Conclusion
Disaster recovery testing is the drill that turns a documented DR plan into a proven capability, by regularly exercising failover and recovery, measuring against objectives, and surfacing gaps before a real disaster does. The discipline that delivers it is the same discipline behind any preparedness: rehearse before the real event, do not discover during it.
Key Takeaways:
- A documented DR plan is a hypothesis until tested
- Regular, realistic drills confirm it works and measure recovery
- Surface gaps in drills, not disasters, and update the plan
Testing DR well requires drill, measurement, and update discipline. When done correctly, it produces:
- Confidence the DR plan actually works
- Recovery time known and meeting objectives
- Gaps found in drills, not disasters
- A current, proven recovery capability
High-Intent Buyers Already Exist in Your CRM
Duplicate records are hiding your best leads. Identity resolution reveals true buyer intent and fixes your pipeline.
What Logiciel Does Here
If your DR plan has never been drilled, schedule regular realistic drills, measure recovery against objectives, surface and remediate gaps, and update the plan, before a real disaster tests it.
Learn More Here:
- AWS Backup and DR: Building a Recovery Plan That Actually Works
- Disaster Recovery Architectures: RPO/RTO in the Age of AI Workloads
- Chaos Engineering in Practice: Patterns for Enterprise Adoption
At Logiciel Solutions, we work with reliability and infrastructure leaders on DR testing, drills, and recovery validation. Our reference patterns come from production recovery programs.
Explore why DR testing is the drill most teams skip, and how to make it routine.
Frequently Asked Questions
What is disaster recovery testing?
Regularly exercising the failover and recovery procedure to confirm it works, measure recovery time against objectives, and surface gaps, turning a documented DR plan into a proven capability rather than an untested hypothesis.
Why is DR testing the drill most teams skip?
Because it is deferred for more urgent work, there is always something that feels more pressing than rehearsing a disaster that has not happened. So the plan stays documented but untested, and whether it actually works is unknown until a real disaster, the worst time to find out.
Why isn't a documented DR plan enough?
Because a plan never drilled is a hypothesis. Whether the failover works, the runbook is current, and recovery meets objectives is unknown until tested. Untested DR plans routinely fail in real disasters because gaps, stale runbooks, broken failover, underestimated time, hid until the worst moment.
What should a DR drill measure?
Recovery time against the RTO and data loss against the RPO, so the recovery objectives are proven in practice, not just stated. Drills should also surface gaps like stale runbooks and broken failover, under realistic failure conditions rather than a trivial happy path.
What is the biggest mistake in disaster recovery?
Documenting a DR plan and skipping the testing. An untested plan is a hypothesis that first gets tested by a real disaster, the worst time to discover it does not work. Drill regularly under realistic conditions, measure recovery, surface gaps, and update the plan.

