

Two Architectures, One Marketing Conflation
Data mesh and data hub get presented as opposing philosophies. The marketing positions them as a binary choice: decentralize through mesh, or centralize through hub. The framing is misleading because the architectures answer different questions and the right answer for most organizations is some combination.
A head of data platform at a multi-business-unit enterprise told me her team had spent eighteen months relitigating mesh-versus-hub before recognizing that the question was wrong. "We kept arguing about which philosophy to adopt," she said. "Once we asked what organizational problem each one solved, we realized we had two different problems and needed two different answers."
The framing she landed on works for most large organizations. Mesh and hub answer different questions. Knowing which question your organization is actually asking is upstream of the architecture choice.

What Mesh Actually Answers
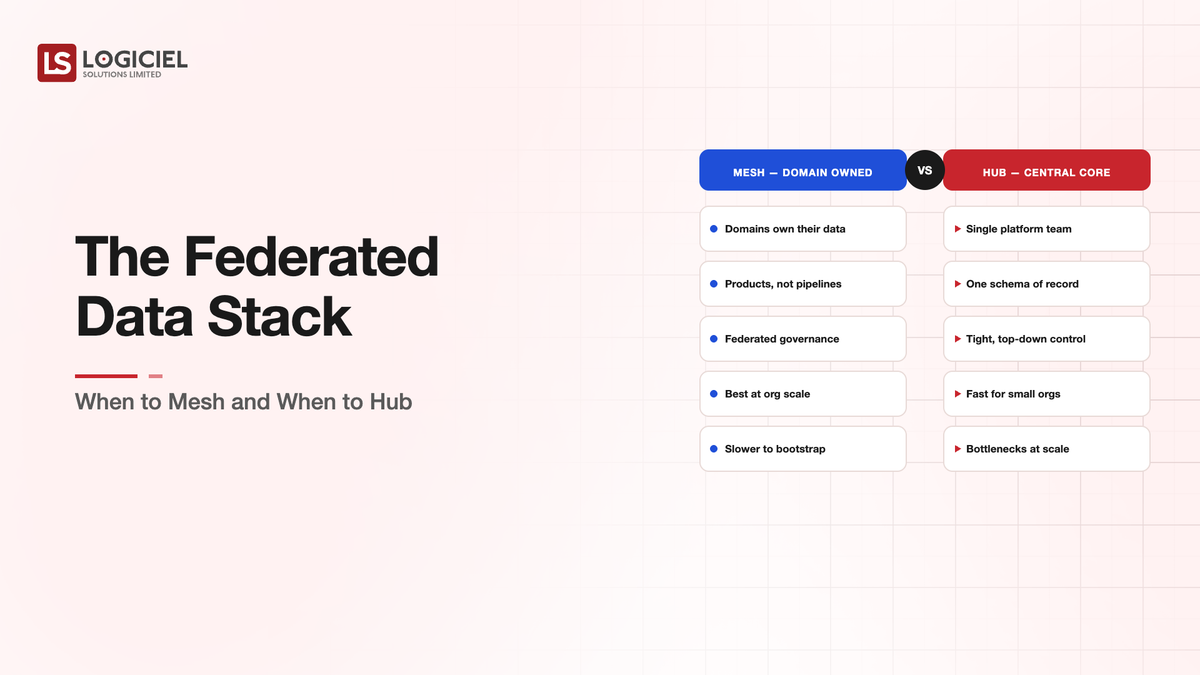
Data mesh as articulated in Zhamak Dehghani's work answers a specific organizational question: how do you scale data engineering when one central team cannot keep up with the demand from many product teams?
The mesh answer is to decentralize ownership. Product teams own their data as products. The central platform team provides infrastructure and standards. The product teams ship data products that other teams consume.
Mesh works when the underlying conditions support it. Product teams have engineering depth to operate data products. The number of consuming teams is large enough that central bottlenecks are real. The governance framework can enforce standards across decentralized ownership.
Mesh struggles when these conditions are absent. Product teams without data engineering skills produce poor-quality data products. Small organizations do not have enough consumer teams to justify the coordination overhead. Governance that depends on cross-team coordination tends to weaken over time without dedicated capacity.
The mesh question is whether your organization has central-team bottleneck pain and the conditions to absorb decentralized ownership. Many organizations have the bottleneck and lack the conditions. Adopting mesh in that state produces fragmented data with the same central bottleneck plus added coordination complexity.
What Hub Actually Answers
Data hub as an architectural pattern answers a different question: how do you provide a consistent view of organizational data when many source systems produce overlapping data?
The hub answer is to centralize the integration layer. Source systems publish to the hub. Consumer applications read from the hub. The hub handles the identifier resolution, the schema normalization, the data quality enforcement that consistency requires.
Hub works when consumer applications need consistent views that source systems cannot provide independently. Customer 360 use cases. Cross-domain analytics. Operational systems that depend on unified data.
Hub struggles when consumer applications can work from source systems directly. Workloads that need only one domain's data. Workloads that tolerate the source system's view. Workloads that are not impacted by the inconsistencies the hub would resolve.
The hub question is whether your organization has consumer applications that need consistent cross-source views. Most large organizations have these workloads; they may not need a hub for them if the workloads are isolated enough.
EHR Integration Reality
The three gaps between Epic's FHIR R4 documentation and production behavior.
Why Many Organizations Need Both
Most large organizations have both questions in play simultaneously. The central team is bottlenecked on producing data for many consumer teams (mesh question). At the same time, some workloads require consistent cross-source integration that source systems cannot provide (hub question).
The architecture that addresses both is federated with a hub. Domain teams own their data products (mesh approach). A central hub integrates the products that need cross-domain consistency (hub approach). The architectures coexist because they serve different needs.
The combined pattern is more complex than either pure mesh or pure hub. The complexity is justified by the dual problem. Organizations that try to solve both with one architectural philosophy usually compromise on one.
The federated-with-hub pattern works when the central platform team has clear scope. The team owns hub infrastructure plus the standards that domain teams follow. The team does not own domain-specific data products. The boundary is explicit and respected.
Without boundary clarity, the central team gets pulled back into domain work, the mesh erodes, and the hub becomes another bottleneck. With boundary clarity, both patterns operate sustainably.
The Hybrid Pattern in Practice
The architecture that most large organizations end up with in 2026 has recognizable shape.
Domain teams operate their own data engineering with central tooling. Sales operates sales data products. Marketing operates marketing data products. Finance operates finance data products. Each team uses central infrastructure (dbt, the data warehouse, observability) but owns its specific transformations and data products.
A central hub integrates data products that downstream workloads need cross-domain. Customer data combined from sales, marketing, and support. Product analytics combined from web, mobile, and operational systems. Financial reporting combined from operational and accounting systems. The hub is narrow rather than universal; it covers what cross-domain workloads genuinely need.
Federated governance enforces standards. Schemas for shared concepts. Data quality SLAs. Access controls. The governance framework is operated by a small central team with representation from domain teams.
Self-service consumption flows from both domain products and hub views. Analytical teams consume domain data products for domain-specific work and hub views for cross-domain work. Both are accessible through the same query interface.
This pattern is more nuanced than the marketing description of either mesh or hub. It also actually works.
What Goes Wrong With Pure Mesh
The pattern of failure for pure mesh is consistent across organizations that have tried it.
Domain teams without data engineering depth ship data products at uneven quality. The variation breaks consumer trust. Consumer teams hesitate to depend on domain data products because they are unsure which ones meet quality bars.
Cross-domain workloads have no clear home. Customer 360 use cases sit between domains. Whichever domain is assigned ownership produces something incomplete; the others contribute reluctantly. The mesh's promise of decentralized ownership stops fitting workloads that genuinely cross domains.
Central governance erodes over time. Domain teams under delivery pressure deprioritize cross-domain governance work. The federation that mesh requires depends on coordination that nobody owns.
These failures are recoverable through adding hub patterns where they fit. The recovery is what produces the federated-with-hub architecture.
What Goes Wrong With Pure Hub
The pattern of failure for pure hub is also consistent.
The hub becomes a bottleneck. All cross-source data flows through one team. The team cannot keep up with demand. Backlogs grow. New workloads wait months for hub support.
The hub becomes brittle. Every source system change requires hub remediation. Hub engineering capacity goes to keeping existing flows working rather than to extending the hub.
The hub becomes opinionated in ways that constrain consumer applications. The hub's schema for customer or product or transaction becomes the only schema. Applications that need different views work around the hub.
These failures are recoverable through adding mesh patterns where they fit. The domain teams take ownership of their data products. The hub focuses on cross-domain integration rather than universal data ownership.
HIPAA and AI
Why 90% of healthcare organizations are unknowingly exposing patient data through AI tools.
What Logiciel Does Here
Logiciel works with data platform leadership clarifying whether mesh, hub, or hybrid fits their actual organizational needs. The work is typically structured around honest assessment of the organizational questions in play rather than around philosophical commitment to a pattern.
The Data Mesh Architecture: Lessons from 3 Years of Real Implementations framework covers the operational lessons from teams that have tried mesh at scale. The Unifying Data Across Systems framework covers the unification patterns that often inform hub design.
A 30-minute working session is enough to assess which organizational questions your current architecture is actually solving.
Frequently Asked Questions
Can a smaller organization benefit from mesh?
Usually not as much as the marketing suggests. Mesh's benefits compound at scale. Smaller organizations often get more value from a competent central team than from decentralized ownership. The threshold for mesh ROI usually sits around 100 data engineers across the organization.
How do I know if I need a hub?
Through your cross-source workloads. If your organization has Customer 360 needs, cross-domain analytics needs, or operational systems that depend on unified data, you have a hub question. If your workloads stay within source domains, you may not need a hub.
What about modern data products without mesh?
Data products as a concept work in any architecture. You can produce data products in a centralized team. The mesh-specific claim is about ownership distribution, not about the data product concept itself.
How does AI integration affect the choice?
AI workloads often need broader and fresher data than traditional analytics. The architecture has to support this. Pure mesh sometimes struggles with the cross-domain consistency that AI training and retrieval workflows need. Hybrid patterns usually fit AI workloads better.
What is the right team size for the central platform function?
Variable. Five to fifteen engineers for moderate enterprises. The team's role is enablement and shared infrastructure, not data product ownership. Sizing the team too small constrains the federation. Sizing it too large recreates the central bottleneck. Sources: - Data Mesh Learning, "State of Data Mesh 2024" - Forrester, "Data Architecture Trends 2024"

