There is a board deck arguing that the data team should focus on AI readiness, while the operations team argues data quality is more important, while the analytics team wants real-time pipelines. The data team is being pulled in three directions and the leadership conversation has not been framed.
This is more than a prioritization gap. It is a failure of data engineering definition.
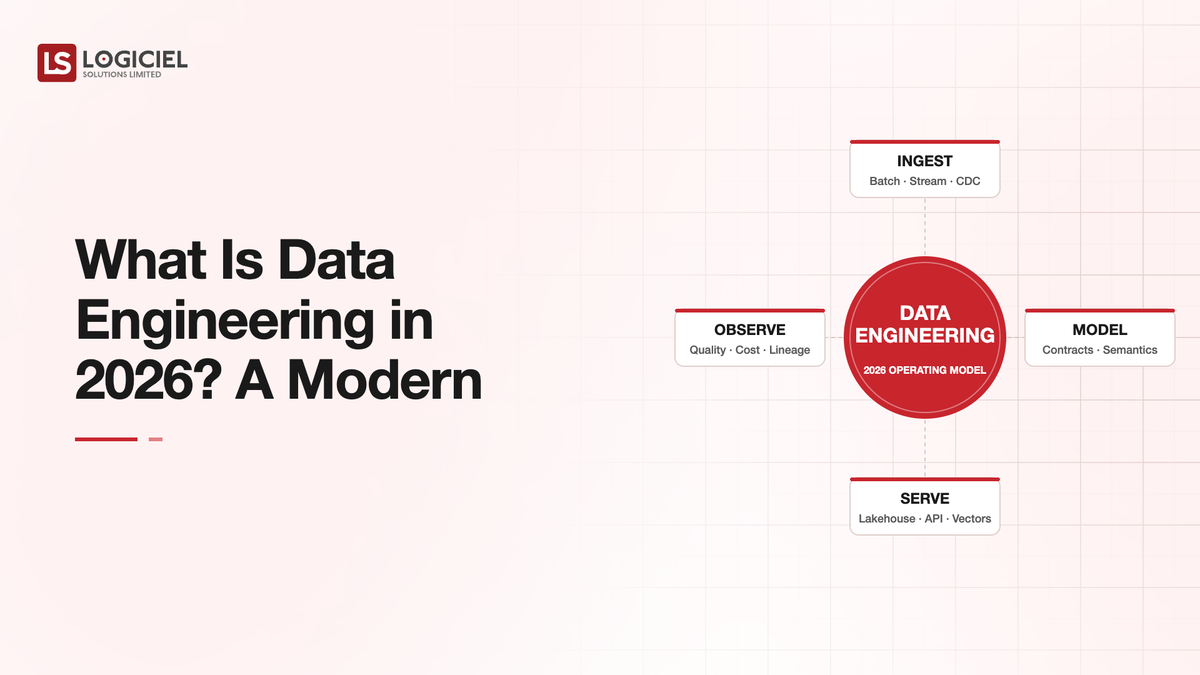
A modern data engineering function does pipelines, contracts, observability, and platform engineering as a single discipline aimed at producing trustworthy data at the speed the business needs.
However, many organizations still treat data engineering as a service desk and discover the gap when AI, analytics, or operations need data that does not yet exist.
If you are a VP Data and are responsible for building or scaling your data engineering organization, the intent of this article is:
- Define what data engineering actually is in 2026
- Walk through the layers that make up the modern discipline
- Lay out the operating model that turns data engineering into a platform
To do that, let's start with the basics.
What Is Data Engineering? The Basic Definition
At a high level, data engineering in 2026 is the discipline of building, operating, and governing the systems that produce trustworthy data at the speed the business needs.
To compare:
If software engineering builds products, data engineering builds the rivers that products and analytics flow through. Both require engineering discipline; the discipline is different.
Why Is Data Engineering Necessary?
Issues that Data Engineering addresses or resolves:
- Producing trustworthy data for AI, analytics, and operations
- Bounding latency and freshness for real-time use cases
- Building the platform that compounds across data products
Resolved Issues by Data Engineering
- Translates business questions into pipeline contracts
- Surfaces data quality and freshness as production metrics
- Establishes the operating model for data systems
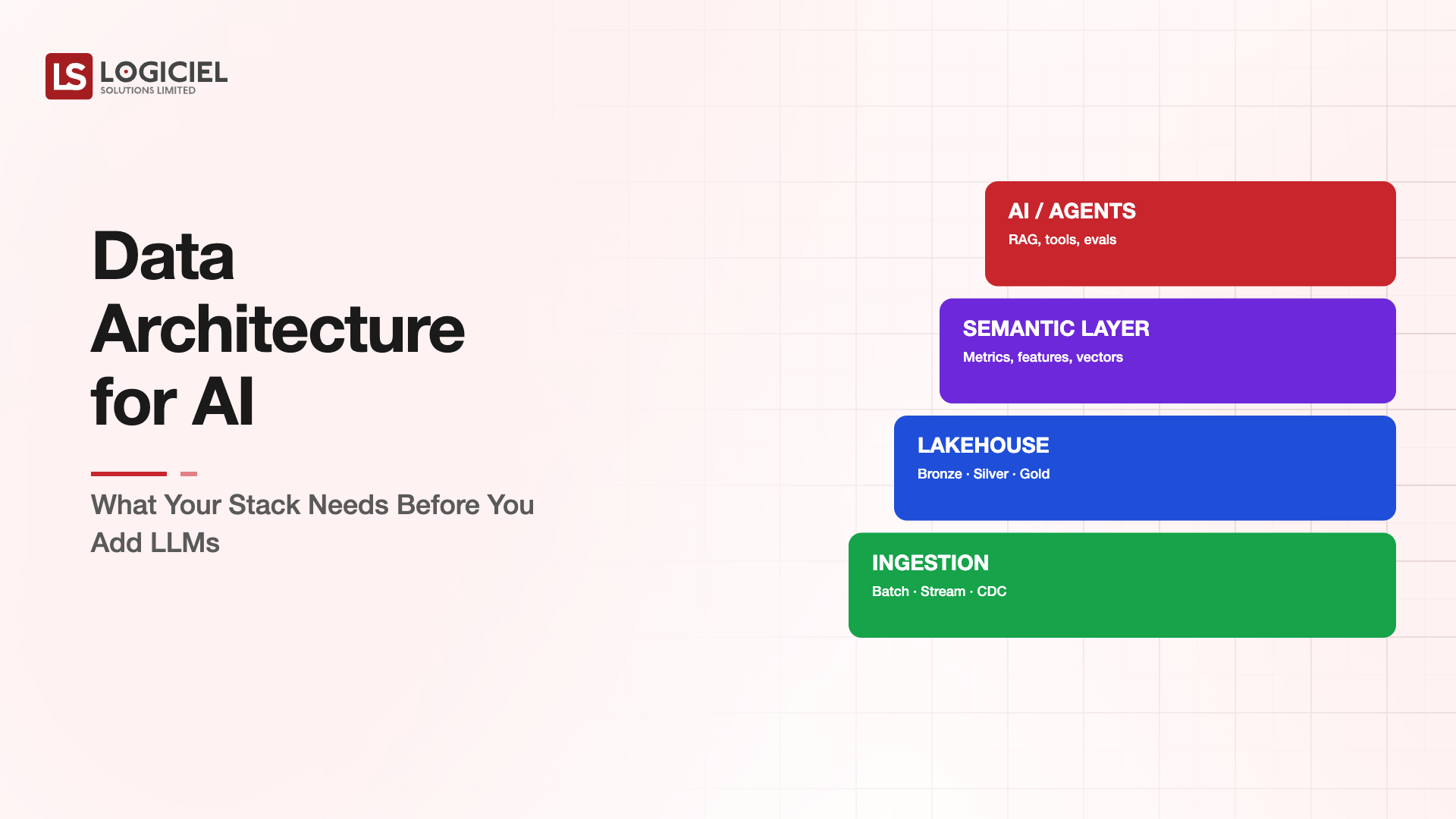
Core Components of Data Engineering
- Ingestion pipelines from operational sources
- Storage and modeling (warehouse, lakehouse, lake)
- Transformation and ELT patterns
- Data contracts between producers and consumers
- Observability and quality monitoring

Modern Data Engineering Tools
- Snowflake, BigQuery, Databricks for storage and compute
- dbt, Spark, Flink for transformation
- Airflow, Dagster, Prefect for orchestration
- Monte Carlo, Acceldata, Soda for observability
- Schema registries and contract testing platforms
Tooling has matured significantly; the operating discipline is the differentiator.
Other Core Issues They Will Solve
- Provides defensible data lineage for audit and regulator review
- Reduces incident severity through observability
- Builds reusable platform for the next data product
In Summary: Data engineering in 2026 is the discipline that produces trustworthy data at the speed the business needs.
Importance of Data Engineering in 2026
Data engineering matters more in 2026 than ever before. Four reasons.
1. AI demands trustworthy data.
AI models trained or grounded on unreliable data produce unreliable outputs. Data engineering is the foundation.
2. Real-time use cases are mainstream.
Streaming pipelines and event-driven architectures have moved from niche to standard. The skill set has expanded.
3. Regulatory expectations require lineage.
Audit and regulator reviews now require defensible data lineage. Without engineering discipline, the lineage does not exist.
4. Data products are now treated as products.
The shift from data tickets to data products changes how teams scope, build, and operate data work.
Traditional vs. Modern Data Engineering Concepts
- Service desk for data tickets vs. platform team building data products
- Manual quality checks vs. observability streaming
- Implicit contracts between teams vs. explicit data contracts
- Annual review cadence vs. continuous engineering practices
In summary: Data engineering in 2026 is the discipline that lets AI, analytics, and operations build on data that the business can trust.
Details About the Core Components of Data Engineering: What Are You Designing?
Let's go through each layer.
1. Ingestion Layer
Where data enters the platform.
Ingestion concerns:
- Source connectors and CDC
- Schema validation at ingest
- Latency and freshness budgets per source
2. Storage and Modeling Layer
Where data lives and how it is shaped.
Storage concerns:
- Warehouse, lakehouse, lake choices
- Modeling patterns: dimensional, normalized, denormalized
- Partitioning, clustering, and cost optimization
3. Transformation Layer
Where raw data becomes usable.
Transformation concerns:
- ELT patterns with dbt or Spark
- Quality checks on transform output
- Lineage capture across transformations
4. Contracts Layer
Explicit agreements between producers and consumers.
Contract concerns:
- Schema, semantics, freshness commitments
- Versioning and deprecation
- Contract testing in CI/CD
5. Observability Layer
Knowing what the platform is doing.
Observability concerns:
- Quality and freshness signals
- Pipeline health and latency
- Cost attribution per data product
Benefits Gained from Contracts and Observability
- Trustworthy data for downstream consumers
- Faster incident detection and recovery
- Reusable platform for the next data product
How It All Works Together
Ingestion captures source data with contracts. Storage and modeling shape it for use. Transformation produces usable datasets. Contracts protect downstream consumers. Observability surfaces what the platform is doing. Together, the layers turn data engineering into a platform that produces trustworthy data at speed.
Common Misconception
Data engineering is the team that runs SQL and Airflow.
Data engineering is platform engineering for data systems. Pipelines are one part of a larger discipline.
Key Takeaway: Each layer requires its own engineering investment. Programs that under-invest in any layer have predictable gaps.
Real-World Data Engineering in Action
Let's take a look at how data engineering operates with a real-world example.
We worked with a data team transitioning from service desk to platform team, with these constraints:
- Multiple downstream teams (analytics, AI, operations)
- Existing pipelines built ad hoc over years
- Limited engineering headcount
Step 1: Inventory the Data Landscape
Sources, pipelines, consumers, contracts (explicit or implicit).
- Source inventory
- Pipeline inventory
- Consumer and use-case mapping
Step 2: Establish Data Contracts
Explicit producer-consumer agreements with versioning.
- Schema and semantics
- Freshness and quality SLOs
- Contract testing in CI/CD
Step 3: Build the Observability Layer
Quality, freshness, lineage, cost.
- Quality monitoring per dataset
- Freshness SLOs and alerts
- Lineage capture across transformations
Step 4: Refactor to Platform Patterns
Reusable transformation libraries; templated pipelines.
- Reusable transformation patterns
- Templated pipeline scaffolding
- Self-service onboarding for new sources
Step 5: Operate as a Platform
Quarterly review cadence; data product roadmap; named owners.
- Quarterly platform review
- Roadmap aligned with consumer needs
- Named owners per data product
Where It Works Well
- Explicit data contracts between producers and consumers
- Observability streaming quality and freshness
- Platform team treating data as products
Where It Does Not Work Well
- Service desk model for data work
- Implicit contracts between teams
- Annual review cadence
Key Takeaway: The data team that operates as a platform produces trustworthy data faster than the team that operates as a service desk.
Common Pitfalls
i) Service desk model
Service desks deliver tickets; platforms deliver products. The shift is structural, not cosmetic.
- Move to product model
- Define data products
- Roadmap aligned with consumers
ii) Implicit contracts
Implicit contracts break silently. Explicit contracts produce signal.
iii) No observability layer
Without observability, quality issues compound. Build the layer; surface signals.
iv) Quality as an afterthought
Quality designed in is cheaper than quality bolted on. Build it into ingest and transform.
Takeaway from these lessons: Most data engineering struggles are operating-model failures, not tooling failures. Tools are widely available; discipline is the work.
Data Engineering Best Practices: What High-Performing Teams Do Differently
1. Treat data as products
Each data product has owners, consumers, contracts, and a roadmap.
2. Establish explicit contracts
Schema, semantics, freshness commitments. Tested in CI/CD.
3. Build the observability layer
Quality, freshness, lineage, cost. Streaming, not periodic.
4. Refactor to platform patterns
Reusable transformations, templated pipelines, self-service onboarding.
5. Operate as a platform
Quarterly review cadence, named owners, roadmap aligned with consumers.
Logiciel's value add is helping data leaders build data engineering as a platform with contracts, observability, and operating model that produce trustworthy data at speed.
Takeaway for High-Performing Teams: High-performing data teams operate as platform organizations with explicit contracts and observability streaming.
Signals You Are Designing Data Engineering Correctly
How do you know this is working? Not in a board deck. In the daily evidence the team produces. The signals below are the ones that separate programs on the path from programs that just look like progress.
The team can name failure modes without flinching. People who actually run these systems will tell you the last three things that broke. People who only read about them won't.
Cost is observable. Today, the team can tell you how much they spent yesterday and what drove the change. Not at the end of the quarter. Today.
Change is boring. Deploys are routine, rollbacks are routine, model swaps are routine. Heroic deploys are a sign of an immature system, not a heroic team.
Eval runs daily, not quarterly. There's a live dashboard with numbers, not a slide with vibes.
Vendor lock-in is a number. The team can tell you the rip-and-replace cost in dollars and weeks. They've done the math. They haven't pretended the question doesn't exist.
Adjacent Capabilities and Connected Work
This work doesn't sit alone. It depends on, and pushes back into, several other capabilities your team is probably already running. Most teams notice this only when one of the adjacent surfaces breaks and the program inherits the cleanup.
The usual neighbors are the data platform, the observability stack, and whatever security review process gets dragged into anything new. Then there's the team-shape question: platform engineering, applied ML, and SRE all share capacity here, and so does whatever AI initiative is next on the roadmap. Worth naming these upfront so leadership sees a portfolio, not a one-off.
The mistake I keep watching teams make is treating the neighbors as someone else's problem. They aren't. The integration with the data platform is yours. So is the security review of the runtime, and so is the on-call rotation that covers what you ship. The work shows up either way, just later and more expensive if you ducked it. Better to own those handoffs and pay the timeline cost upfront.
Stakeholder Considerations and Communication
Different rooms ask different questions, and the answers don't translate well between them.
The board wants to know about risk, ROI, and whether this puts you ahead of competitors. Your CFO wants unit economics and a forecast that holds up under sensitivity. The CISO wants the threat model and a defensible audit posture. Engineering wants to know what's in scope, what's bought, and what they're going to be on call for. The line of business wants a date the value lands on, and a description of what users will see.
Programs that prepare for these audiences move faster, full stop. A one-page brief per stakeholder, updated quarterly, costs almost nothing to produce. Not having those briefs is what turns a quarterly review into the meeting where sponsor confidence quietly leaks out.
Communication cadence also matters more than people think. Weekly during active delivery. Monthly during steady-state. Always after an incident or a meaningful change. Programs that go quiet between milestones end up surprising leadership in ways that are not flattering. Pick a cadence at kickoff and protect it.
Metrics That Tell You Data Engineering Is Working
Beyond the success signals above, these are the leading indicators worth watching week over week. They're not vanity numbers. They distinguish programs that are compounding from programs that are running in place.
Time from idea to production. How long does it take a new use case to get from concept to something a customer actually sees? Programs that are working see this number drop quarter over quarter. Programs that aren't see it grow.
Cost per unit of value. Are you spending less per unit of output each quarter, or more? This is the cleanest leading indicator that the platform layer is amortizing.
Incident severity over time. Severity drops as the operating model matures. Flat or rising severity says the operating model has gaps you haven't named yet.
Reuse rate across programs. What fraction of what you built for program one shows up in program two and program three? High reuse means the first investment is paying back. Low reuse means you're rebuilding.
Sponsor confidence trend. Hard to measure directly. Easier to read in approved budget, in strategic emphasis, and in whether your sponsor is asking for more or asking you to slow down.
Conclusion
Data engineering in 2026 is platform engineering for data systems. The layers are well known; the operating model is the work.
Key Takeaways:
- Data engineering is platform engineering, not service desk work
- Five layers: ingestion, storage, transformation, contracts, observability
- Operating model and cadence are the multipliers
When data engineering is run as a platform, the benefits compound:
- Trustworthy data for AI, analytics, and operations
- Faster incident detection and recovery
- Reusable platform for the next data product
- Defensible lineage for audit and regulator review
Call to Action
If your data team is operating as a service desk, the move this quarter is to define data products, establish contracts, and build the observability layer.
Call to Action
If your data team is operating as a service desk, the move this quarter is to define data products, establish contracts, and build the observability layer.
Learn More Here:
At Logiciel Solutions, we work with data leaders on the platform transformation: contracts, observability, and operating model that turn data engineering into a multiplier.
Explore how to modernize your data engineering function.
Frequently Asked Questions
What is data engineering?
The discipline of building, operating, and governing the systems that produce trustworthy data at the speed the business needs.
How is data engineering different from analytics engineering?
Data engineering builds the platform; analytics engineering builds the analytical models on top. Both are engineering disciplines; the boundary is the consumer-facing model layer.
What does the team look like?
Platform engineer, data engineer, analytics engineer, observability engineer, governance partner. Smaller teams compress roles; larger teams add specialists.
How do data contracts work?
Explicit producer-consumer agreements covering schema, semantics, freshness, and quality. Tested in CI/CD; versioned with deprecation paths.
What is the biggest mistake in data engineering?
Operating as a service desk instead of a platform team. The shift is structural, not cosmetic.