


There is an anomaly detection system in your organization firing alerts that the team has learned to ignore. It flags every minor fluctuation, most of which are normal variation, so the real anomalies are buried in noise the team has tuned out. The detection was built to catch problems, and by crying wolf it has trained the team to ignore exactly the alerts it exists to raise. The system detects anomalies; it does not distinguish the ones that matter.
This is more than a noisy alert. It is anomaly detection that cries wolf and trains the team to ignore it.
Anomaly detection that does not cry wolf is tuned for signal over noise: it distinguishes the anomalies that matter from normal variation, so its alerts are rare enough and meaningful enough to be trusted and acted on. A detector that flags everything is no better than one that flags nothing, because both leave the real anomalies unhandled. The value is in precision, catching the real anomalies without the noise that drowns them.
However, many teams build anomaly detection that flags every fluctuation and discover the team ignores it, so the real anomalies go unhandled.
If you are a data or platform leader building anomaly detection, the intent of this article is:
- Define what tuning anomaly detection for signal means
- Walk through precision, context, and severity
- Lay out the controls trusted detection needs
To do that, let's start with the basics.
Why CFOs Reject Technical Infrastructure Cases
Inside a 5-step framework that won $500K of infrastructure budget in 14 days.
What Is Signal-Tuned Anomaly Detection? The Basic Definition
At a high level, signal-tuned anomaly detection distinguishes the anomalies that matter from normal variation, tuned so its alerts are rare and meaningful enough to be trusted and acted on, rather than flagging every fluctuation and being ignored.
To compare:
If a noisy detector is a car alarm that goes off in the wind, a signal-tuned one is one that goes off only on a real break-in. The first is ignored by everyone including its owner; the second is heeded because it means something.
Why Is Tuning for Signal Necessary?
Issues that tuning for signal addresses or resolves:
- Distinguishing real anomalies from normal variation
- Keeping alerts trusted and acted on
- Preventing real anomalies from being buried in noise
Resolved Issues by Tuning for Signal
- Surfaces the anomalies that matter
- Keeps alerts rare and meaningful
- Restores trust so alerts are heeded
Core Components of Signal-Tuned Detection
- Precision over recall where appropriate
- Context distinguishing anomaly from normal variation
- Severity and prioritization
- Feedback to tune the detector
- Monitoring of alert quality
Modern Anomaly Detection Tooling
- Statistical and ML anomaly detection
- Contextual and seasonal baselines
- Severity scoring
- Feedback loops for tuning
- Alert quality monitoring
These tools support detection; the discipline is tuning for signal so alerts are trusted, not flagging everything.
Other Core Issues They Will Solve
- Keep teams responsive to real anomalies
- Reduce alert fatigue from noise
- Catch the anomalies that matter
Importance of Tuning for Signal in 2026
Tuning for signal matters more as anomaly detection proliferates. Four reasons explain why it matters now.
1. Noisy detection trains teams to ignore it.
A detector that flags everything trains the team to ignore it, so the real anomalies go unhandled. Crying wolf defeats the purpose.
2. Real anomalies hide in noise.
When everything is flagged, the real anomalies are buried in normal-variation alerts. Precision surfaces them.
3. Trust determines whether alerts are heeded.
Alerts are acted on only if trusted. Noise erodes trust; signal preserves it.
4. Flagging everything equals flagging nothing.
A detector that flags everything is no more useful than one that flags nothing, because both leave real anomalies unhandled.
Traditional vs. Signal-Tuned Detection
- Flag every fluctuation vs. flag the anomalies that matter
- Noise burying signal vs. precision surfacing it
- Ignored alerts vs. trusted, heeded alerts
- Recall at all costs vs. precision where it matters
In summary: Signal-tuned anomaly detection distinguishes real anomalies from normal variation so alerts are rare, meaningful, trusted, and acted on.
Details About the Components of Signal-Tuned Detection: What Are You Tuning?
Let's go through each element.
1. Precision Layer
Real anomalies, not noise.
Precision decisions:
- Precision favored where false positives erode trust
- False positives reduced
- The anomalies that matter flagged
2. Context Layer
Anomaly versus variation.
Context decisions:
- Seasonal and contextual baselines
- Normal variation distinguished from anomaly
- Context-aware detection
3. Severity Layer
Prioritizing.
Severity decisions:
- Severity scored
- High-severity prioritized
- Low-severity handled differently
4. Feedback Layer
Tuning over time.
Feedback decisions:
- Feedback on alert quality
- False positives tuned out
- Detector improved
5. Quality Layer
Monitoring alerts.
Quality decisions:
- Alert precision and dismissal monitored
- Noise tracked
- Trust maintained
Benefits Gained from Tuning for Signal
- Real anomalies surfaced and acted on
- Alerts trusted because they are meaningful
- Teams responsive instead of desensitized
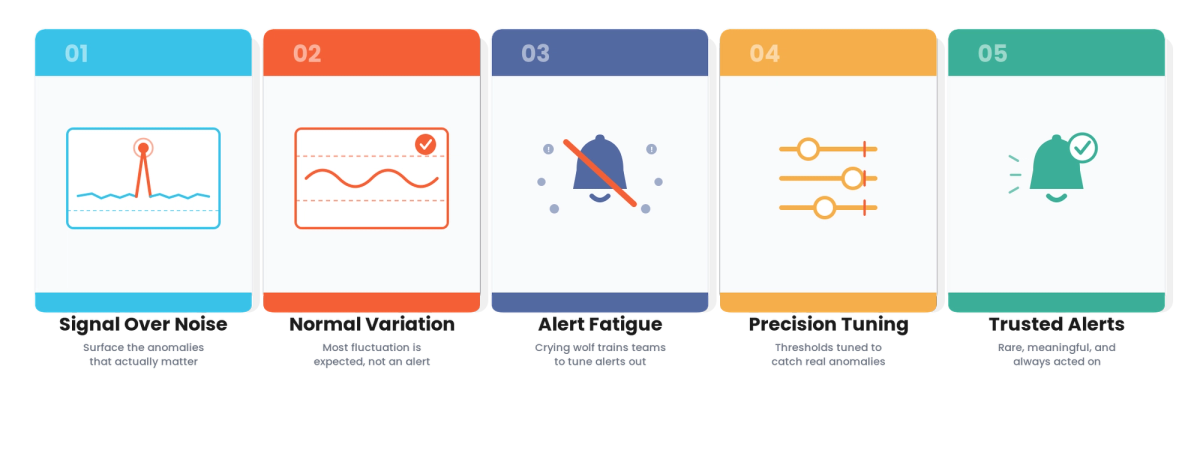
How It All Works Together
The detector is tuned to distinguish real anomalies from normal variation, favoring precision where false positives erode trust, and using seasonal and contextual baselines so expected variation is not flagged. Anomalies are scored by severity and prioritized, so high-severity ones get attention and low-severity ones are handled differently. Feedback on alert quality tunes out false positives over time, and alert precision and dismissal are monitored so noise is tracked and trust maintained. Alerts become rare and meaningful, so the team trusts and acts on them, and the real anomalies are surfaced rather than buried in noise the team has tuned out.
Common Misconception
More sensitive anomaly detection catches more problems.
More sensitive detection flags more fluctuations, most of them normal variation, training the team to ignore the alerts, so real anomalies go unhandled. A detector that flags everything is no better than one that flags nothing. Catching the problems that matter requires precision, not sensitivity.
Key Takeaway: Flagging everything is the same as flagging nothing, because both leave real anomalies unhandled. The value is precision, signal over noise.
Real-World Signal-Tuned Detection in Action
Let's take a look at how tuning for signal operates with a real-world example.
We worked with a team whose anomaly detection was being ignored, with these constraints:
- Distinguish real anomalies from normal variation
- Keep alerts trusted and acted on
- Surface the anomalies that matter
Step 1: Favor Precision
Real over noise.
- Precision favored
- False positives reduced
- Anomalies that matter flagged
Step 2: Add Context
Anomaly versus variation.
- Seasonal and contextual baselines
- Normal variation distinguished
- Context-aware
Step 3: Score Severity
Prioritize.
- Severity scored
- High-severity prioritized
- Low-severity handled differently
Step 4: Feed Back
Tune over time.
- Feedback on alert quality
- False positives tuned out
- Detector improved
Step 5: Monitor Quality
Track trust.
- Precision and dismissal monitored
- Noise tracked
- Trust maintained
Where It Works Well
- Precision and context distinguishing anomaly from variation
- Severity scoring and feedback tuning
- Alerts trusted, real anomalies surfaced
Where It Does Not Work Well
- Flagging every fluctuation
- Real anomalies buried in noise
- Alerts ignored, problems unhandled
Key Takeaway: The anomaly detection that catches the problems that matter is the one tuned for signal, precise, contextual, prioritized, so alerts are trusted, not the one that flags everything and is ignored.
Common Pitfalls
i) Flagging everything
A detector that flags every fluctuation trains the team to ignore it. Tune for precision so alerts are meaningful.
- Favor precision
- Use context
- Reduce false positives
ii) Ignoring context
Without seasonal and contextual baselines, normal variation is flagged as anomaly. Use context.
iii) No severity
Treating all anomalies equally floods the team. Score and prioritize by severity.
iv) No feedback
Without feedback, false positives persist. Tune the detector from alert-quality feedback.
Takeaway from these lessons: Most anomaly detection fails by crying wolf, not by missing anomalies. Tune for precision, use context, prioritize by severity, and feed back.
Signal-Tuned Detection Best Practices: What High-Performing Teams Do Differently
1. Tune for precision where trust matters
Favor precision over sensitivity where false positives erode trust, so alerts stay meaningful and heeded.
2. Use contextual baselines
Distinguish normal, seasonal variation from real anomalies with context-aware baselines.
3. Score and prioritize by severity
Prioritize high-severity anomalies and handle low-severity differently, so the team is not flooded.
4. Feed back to tune
Use feedback on alert quality to tune out false positives and improve the detector over time.
5. Monitor alert quality
Track precision and dismissal so noise is caught and trust is maintained.
Logiciel's value add is helping teams tune anomaly detection for signal, precision, context, severity, and feedback, so alerts are trusted and the anomalies that matter are surfaced rather than buried.
Takeaway for High-Performing Teams: Focus on signal over noise. Anomaly detection that does not cry wolf is precise, contextual, and prioritized, so its alerts are trusted and acted on; flagging everything is the same as flagging nothing.
Signals You Are Detecting Anomalies Correctly
How do you know the detection works? Not in sensitivity, but in whether alerts are trusted. Below are the signals that distinguish signal-tuned detection from crying wolf.
Alerts are trusted. The team acts on alerts rather than ignoring them.
Real anomalies are caught. The anomalies that matter are surfaced, not buried in noise.
Context distinguishes variation. Normal, seasonal variation is not flagged as anomaly.
Severity prioritizes. High-severity anomalies get attention; low-severity are handled differently.
Quality is monitored. The team tracks precision and dismissal and tunes the detector.
Adjacent Capabilities and Connected Work
This work does not exist in isolation. Anomaly detection depends on, and feeds into, several adjacent capabilities. Building one without thinking about the others is the most common scoping mistake.
In most organizations, anomaly detection shares infrastructure with the monitoring and data platform, the alerting system, and the operations process. It shares capacity with data engineering, SRE, and the teams responding to alerts. And it shares leadership attention with whatever the next reliability or analytics initiative is on the roadmap. Naming these adjacencies upfront helps the program scope realistically and helps leadership see the work as a portfolio rather than a one-off project.
The most common mistake in adjacency-capability scoping is treating each adjacency as someone else's problem. The alerting that routes anomalies is your problem. The feedback from responders is your problem. The baselines that capture context are your problem. Pretending otherwise pushes work to teams that did not plan for it, and the work returns to you later as ignored alerts and unhandled anomalies. Own the adjacencies you depend on; partner with the teams that own them; share the timeline.
Conclusion
Anomaly detection that does not cry wolf is tuned for signal over noise, distinguishing the anomalies that matter from normal variation so its alerts are trusted and acted on. The discipline that delivers it is the same discipline behind any alerting: maximize precision and context so the signal is heeded and the noise does not drown it.
Key Takeaways:
- Flagging everything is the same as flagging nothing
- Tune for precision and use contextual baselines
- Prioritize by severity, feed back, and monitor alert quality
Tuning anomaly detection well requires precision, context, and feedback discipline. When done correctly, it produces:
- Real anomalies surfaced and acted on
- Alerts trusted because they are meaningful
- Teams responsive instead of desensitized
- Detection that catches the problems that matter
AI Products Fail Because of Infrastructure
They’re stuck because the data layer they need doesn’t exist yet
What Logiciel Does Here
If your anomaly detection is being ignored, tune it for signal: favor precision, use contextual baselines, prioritize by severity, and feed back to reduce noise.
Learn More Here:
- Clinical Decision Support: Avoiding Alert Fatigue by Design
- Data Quality and Anomaly Detection
- AI Model Monitoring in Production: Drift, Decay, and What to Do About It
At Logiciel Solutions, we work with data and platform leaders on anomaly detection tuning, alert quality, and signal-over-noise design. Our reference patterns come from production detection systems.
Explore how to build anomaly detection that doesn't cry wolf.
Frequently Asked Questions
What does tuning anomaly detection for signal mean?
Tuning the detector to distinguish the anomalies that matter from normal variation, so its alerts are rare and meaningful enough to be trusted and acted on, rather than flagging every fluctuation and being ignored. The value is precision, signal over noise.
Why is more sensitive detection not better?
Because more sensitivity flags more fluctuations, most of them normal variation, training the team to ignore the alerts so real anomalies go unhandled. A detector that flags everything is no better than one that flags nothing. Catching what matters requires precision, not sensitivity.
How do you distinguish anomalies from normal variation?
With contextual and seasonal baselines that capture expected variation, so the detector flags genuine deviations rather than normal fluctuations. Context-aware detection is what keeps normal variation from being alerted as anomaly.
Why does trust matter in anomaly detection?
Because alerts are acted on only if trusted. A noisy detector that cries wolf erodes trust, so the team ignores its alerts, including the real ones. Tuning for signal keeps alerts meaningful, which keeps them trusted and heeded.
What is the biggest mistake in anomaly detection?
Building it to flag every fluctuation, maximizing sensitivity, which trains the team to ignore it so real anomalies go unhandled. Flagging everything is the same as flagging nothing. Tune for precision, use context, prioritize by severity, and feed back to reduce noise.

