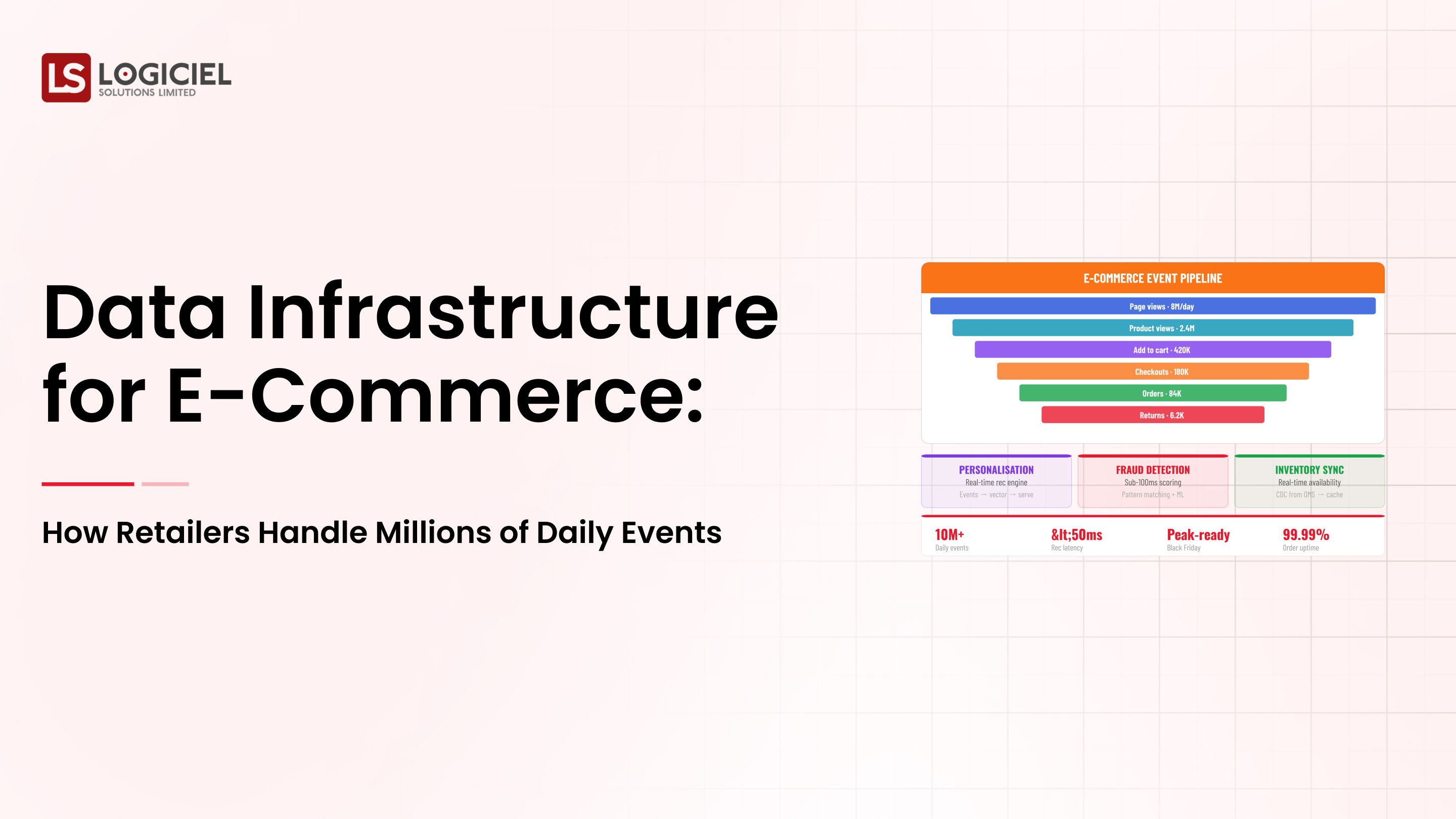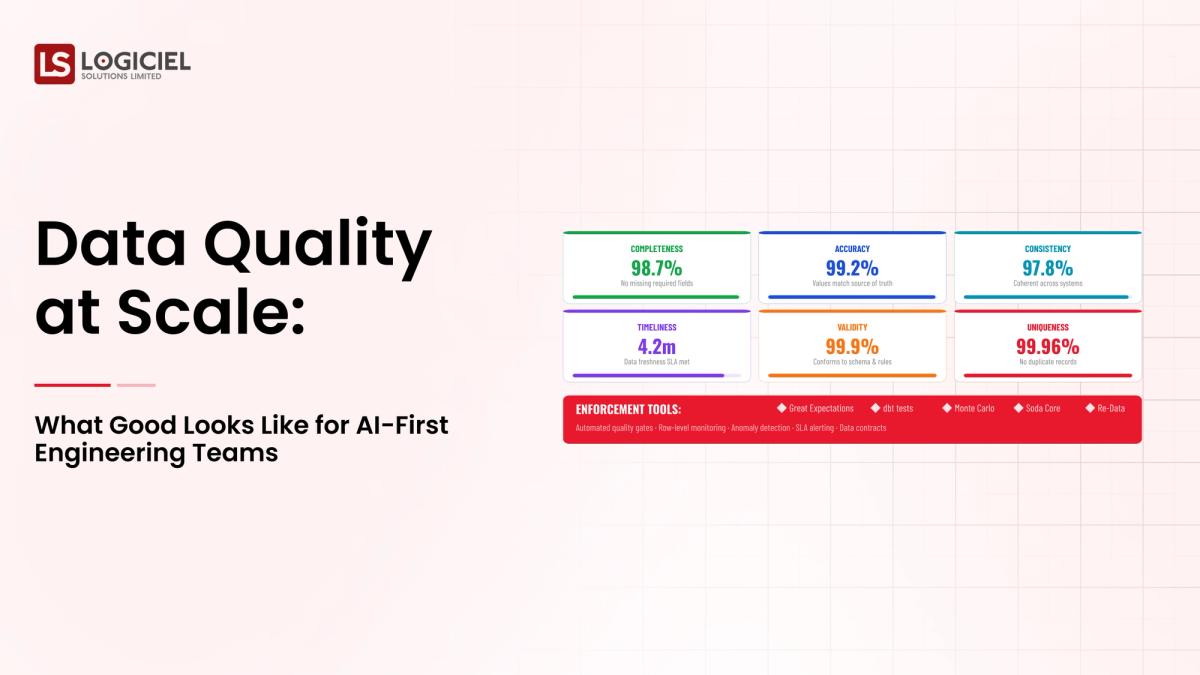
Quality Data Large Scale: An Overview For AI-First Engineering Teams
- Your data pipelines are operational.
- Your dashboards are automatically updated.
- Your models are implemented.
Yet, there is still something wrong.
Your stakeholders have doubts about the quality of your data. Your engineers spend a lot of time debugging rather than building. Over time, the models are slowly degrading with no defined cause.
This is not an issue related to the pipelines.
This is a data quality issue.
And as your data grows in size, the data quality will not be a downstream thing, the data quality becomes a fundamental responsibility of the overall data infrastructure.
For CTOs or VPs of Engineering who are tasked with growing their data infrastructure, ensuring quality data is one of the biggest challenges faced by a data engineer.
The overall success of any AI system and the speed at which decisions are made rely upon having good quality data to work from.
Once you lose data integrity from false data records, the trust level of the organisation diminishes.
Agent-to-Agent Future Report
Understand how autonomous AI agents are reshaping engineering and DevOps workflows.
In this guide, you will learn:
The real definition of data quality in today’s modern systems Why big data will create additional challenges in maintaining data quality How the top performing teams implement infrastructures to retain quality consistently
Now that we have provided you with the introduction background on Data Quality, we would like to explore some of the basic ideas behind the concept of Data Quality.
Section One: The Real Definition of Data Quality in Today’s Modern Day Systems
The definition of Data Quality is a very complex one.
There is more to Data Quality than just having “clean data”.
The Four Dimensions of Data Quality
Current data infrastructures assess Data Quality through Four Dimensions.Completely Data-Complete
All data must be accounted for No missing records or fields
Consistent Data
Consistency Across Systems
Timely Availability of Data
When You're Ready for Your Data
No Delayed Data Or Redundant Records
Simple Example
- Accurate Revenue Dashboard
- Consistency
- Complete Revenue Dashboard
- No Delayed Updates
Lose Trust If Any One Of These Areas Is Compromised.
Data Quality Is NOT
A One-Time Data Cleaning Effort The Last Step In A Validation Process A Manual Task
Data Quality IS
An Ongoing Process Data Quality Automates The Accommodation Of Data Quality Embedded Within The Overall Infrastructure
Key Takeaway
- Data quality is NOT A FEATURE
- Data Quality IS A SYSTEM PROPERTY
Section 2: Reasons Why Data Quality Breaks Down As Data Grows
As Data Grows So Do The Challenges Associated With Data Quality
1. Too Many Sources Of Data
Modern Systems Recieve Their Data From:
- Applications
- APIs
- 3rd Party Systems
- IoT Devices
Each Source Introduces Variability Into The Data

2. Too Many Transformations Of The Same Data
Data Passes Through
- Multiple Pipelines
- Aggregates
- Enrichments
Every Transformation Adds Risk To The Data
3. Too Many Consumers Of The Same Data
Data Will Be Used By:
- Data Analytic Teams
- Product Development Teams
- Artificial Intelligence
Each Consumer Has Different Requirement For Their Data
4. Real-Time Systems Are Complicated
Real-Time Systems:
- LEave No Opportunity For Validation
- Require Speed Of Processing
- Have Additional Failure Opportunities
5. Imprecise Data Ownership Issues
No Clear Definition Of Ownership Will Result:
- No Resolution Of Data Quality Issues
- Lack Of Accountability
Example
1 Metric Defined Differently By Two Departments
Stored In Two Different Locations Will Result In:
- Conflicting Dashboards
- Loss Of Trust In The Company
Compounding Effect Of Poor Data Quality:
Examples Of Small Data Quality Problems:
1 Data Quality Problem Consistently Over Time Becomes A Systemic Problem
Key Takeaway
Data Quality Issues Don't Happen Over Night
Data Quality Issues Develop Gradually, Quietly Over Time Until Numbers Become Too Large For One Data Quality Issue To be RESOLVED.
Section 3: Where Data Quality Issues Originated
To correct poor quality requires an understanding of where it has broken down.
1. Data Collection
Errors at collection include:
- Absence of Field Values
- Incorrect Formatting
- Incomplete Records
2. Transformation Layer
Transformation errors arise from:
- Badly Formulated Logic
- Aggregation Errors
- Schema Mismatch
3. Connection Points
Connection points of disparate systems introduce:
- Variations in Data Interpretation
- Inconsistency into System
4. Real-time Pipelines
Errors that occur with real-time pipelines are:
- Late Arrival of Data
- Ordered Data Arrival
- Partial Processing
5. Manual Processes
With manual processes, human action:
- Creates Addition of Errors to System
- Delivers Inconsistency throughout System
Common Observations
Where Data Quality Issues Exist:
- Originated Upstream
- Reveal Themselves Downstream
Key Insight
Correcting Data Quality At Its Source Provides Greater Value than Rectifying After The Fact.
Section Four: Traditional Methods For Managing Data Quality Will Fail.
Organisations Approaching Data Quality By Treating The Cause Of Data Quality is Insufficient.
1. Reactive/Proactive
Organizations Fix Data Quality Issues After-The-Fact Rather Than Preventing
2. Manual Verification
Manual Methods Do Have Scale Limitations, and Will Contain Multiple Errors
3. Lack of Observability
Without observability, when organization experiences Data Quality Issues, those decisions will be unknown until:
Debugging Is: Time Consuming
4. Lacking Clear Ownership
When Data is Owned By Everyone, There Will Be No Accountability For Its Quality
5. Treating Data Validation As A Step
Data Quality Checks Are Added At End Of Processing Pipeline, Rather Than Embedded During Processing Pipeline
Example: If A Data Processing Pipeline Runs Successfully, Yet Produces Invalid Data, Alerts Will Not Be Issued To Notify Of Possible Data Quality Issue.
Key Insight
The Reason Traditional Data Quality Management Methods Fail Is Because Of The Understanding That Data Quality Is Something You Do After Happens.
Section Five: How To Build Data Quality Directly Into The Data Processing Infrastructure.
OrganizationsWhat are Data Contracts
Data Contracts Set Expectations For
Schema - What the structure of your data will look like. Data Types - What the types of data in your dataset will be. Constraints - What the rules are for your data or the way data must be entered.
By defining your data contracts, you will be able to ensure there are no unexpected changes.
How Should I Validate My Data
To Validate Data, You Should Automate Validation And Validate Data. This Means You Will Need To Validate The Data You Are Ingesting, Validating The Transformation Of Data, And Validating The Data Before Serving It.
How Do I Implement Data Observability
When implementing data observability, you need to have a way to track the following:
Data Freshness - How current is the data. Data Completeness - Is the data complete. Anomalies - Anything unusual.
How Do I Assign Data Ownership
Data ownership should be assigned as follows:
Each Dataset Should Have A Clearly Defined Owner Each Dataset Should Have A Clearly Defined Set Of Responsibilities.
How Do I Standardize Metrics
When standardizing your metrics, you should have a standard definition and a common understanding to ensure.
How Do I Build Feedback Loops For Continuous Improvement
You will want to build feedback loops that will allow for continuous improvement and rapid resolution of issues.
An Example Workflow
- Data ingested is validated
- Transformations of the data have been validated
- Metrics have been standardized
- Data Observability is monitoring the quality of the data
- Alerts are set up on any quality issues.
Key Insight
Data quality is about building it into the system, not adding it to the system.
Section 6. What Are AI First Teams Doing Differently When It Comes To Data Quality
AI First Teams Are Raising The Bar For Data Quality.
1. Data As A Product
They Do This By Defining:
Service Level Agreements (SLA) Data Owners Data Consumers.
2. Align Data To Machine Learning Workflows
They Do This By:
Ensuring That The Data Used In Machine Learning Training And Inference Is Consistent. Ensuring That The Features Used In Machine Learning Are Standardized.
3. Invest In Data Observability
They Monitor:
Data Quality Pipeline Performance Data Used As Input In Machine Learning Models.
4. Automation Of Everything
They Automate:
Validation Monitoring Alerts.
5. Design For Scalability
They Design Their Systems To:
Be Able To Grow And Continue To Maintain Their Quality.
6. Trust
They Focus On:
Consistency Transparency Reliability.
An Example Of A High Performing Team Would Be Able To:
Detect Anomaly Early Keep Their Metrics Consistent Provide Reliable Machine Learning Model Inputs
Key Insight
The Top Performing Teams Don’t Fix Data Quality Issues They Prevent Issues From Happening In The First Place.
Logiciel POV
Data Quality Is Not A Technical Detail, But The Foundation For Every Decision, Every Model And Every System You Build.
If You Want To Be A Successful Team, You Should:
Build Quality Into Your Data Infrastructure Use Automation To Validate Your Data Prioritize Trust In The Data You Process.
At Logiciel, We Work With Organizations On Designing Data Systems To Maintain Quality At Scale That Enable Reliable Analytics And Outcomes Through AI Driven Analytics.
If Your Team Is Spending More Time Fixing Data Than You Are Using Data You Should Rethink Your Approach.
If Your Team Would Like To Learn More About How Logiciel’s Engineering Teams Can Help You Build An Infrastructure That Delivers High Quality, Reliable And Consistent Data At Scale, Please Reach Out To Us.
RAG & Vector Database Guide
Build the quiet infrastructure behind smarter, self-learning systems. A CTO’s guide to modern data engineering.
Frequently Asked Questions
What Is Data Quality In Data Infrastructure
Data Quality Is Defined As The Accuracy, Completeness, Consistency, And Timeliness Of Data In The system.
Why Is Data Quality Important To AI Systems?
The AI Systems Depend On High Quality Data. Low Quality Data Will Create Incorrect Predictions And Result In Decreased Model Performance.
How Will I Improve Data Quality At Scale?
Using Data Contracts, Automated Validation, Building Data Observability, And Assigning A Clear Owner To Each Dataset Will Help.
What Are The Challenges Of Maintaining Data Quality?
The Biggest Challenge With Maintaining Data Quality Is the Size Of The Data. As Data Grows Maintaining Reliability And Consistency In The Data Will Become More Complex.