Your dashboard appears to be running smoothly, your pipelines show a “green” status, and everybody involved is happy with the process being used to service their needs.
Then, all of a sudden, everything changes.
A business metric drops, and a report looks wrong, or your model seems to have drifted away from expected behaviour.
By the time anyone notices that there is an issue, the effect of that issue has already spread to other systems.
The modern reality for many organizations that position themselves as data-driven is that you have likely invested heavily in your data infrastructure. Yet still, the vast majority of organizations do not have true visibility into what is going on inside of the pipelines that comprise that data infrastructure.
If you are a data engineering lead and face challenges with data pipelines, this situation can become quite dangerous; because the issue with the pipeline is not necessarily that it broke, but that you broke it without knowing when - or even if - you broke it.
Evaluation Differnitator Framework
Why great CTOs don’t just build they evaluate. Use this framework to spot bottlenecks and benchmark performance.
Defining Data Pipeline Observability?
Data Pipeline Observability is defined as:
Observation of the flow of data across multiple systems Detection of anomalies in near real-time Identification of the root cause of failures Verification of the reliability of data from the beginning of ingestion until the end of the data processing pipeline
Observability Versus Traditional Monitoring
Whereas traditional monitoring focuses on the following:
- System uptime
- Whether jobs have succeeded or failed
Observability, on the other hand, focuses on:
Whether the data is correct Whether the data is still fresh Whether the data is complete
Defining Data Infrastructure Management as Related to Observability
Data infrastructure management refers to the systems and processes that are used to:
Manage data pipelines Monitor performance of data pipelines Ensure that data still meets desired levels of reliability
Observability is one of these critical layers of data infrastructure management.
Key Takeaways
Monitoring will only tell you that something is broken; observability will provide you insight into how and when something broke and, in some cases, how to fix it.Observability allows you to know what, why.
Why Pipelines Break, But You Can't Tell.
1. Pipelines Can Drive Data that is Wrong, Yet Still be Successful
Most systems are tracking things like:
- Job Completion
- Execution Status
However, they are not tracking:
- Data Accuracy
- Data Consistency
For example,
The pipeline can run successfully, but "success" can mean that:
- 20% of records were dropped
- Key column formatted incorrectly
This success report states "successful" for the system, while the actual business will see a failure.
2. No End-to-End Visibility
Modern Pipelines...
- Have multiple tools
- Have multiple teams
- Have multiple environments
Result: There is no single source of truth on data.
A fragmented monitoring environment.
3. Schema Drift
Data is constantly evolving; if there are no appropriate controls in place, the following things will occur:
- Fields Change
- Types Change
- Structures Break
Result of Schema Drift: Downstream Failures; Silent Data Corruption.
4. Long Feedback Loops
The majority of issues that you find in your data won't be found until:
- Hours after the fact
- Days after the fact
With these lengthy delays come:
Very high costs to fix when you do find out the issue. A loss of trust in the data.
5. Over-Reliance on Alerts
Too many alerts can lead to:
- Getting burned out from alerts warnings
- Ignoring other or additional "wowed" alerts.
The most important take away here... The biggest risk of your pipeline is not failure; it is "undetected" failure!
The Hidden Cost of Poor Observability
Poor Observability affects Engineering and More.
1. Business Decisions
Making critical business decisions with "bad" or incorrect data leads to:
- Poor business strategies.
- Missed revenue opportunities.
2. Engineering Productivity
Teams spend significant time:
- Debugging the Pipelines to see where the failure occurred.
- Tracing the issue(s) that are causing poor data.
Consequently, the time taken to "debug" and "trace" is time wasted on developing new features.
3. Trusting the Data
Once you have lost trust in any data source, you will:
- Have a decline in user adoption of the source
- Have teams revert back to "manual" processes.
The most important take away here: Observability isn't just something technical; it is a business requirement!
What are the Components of Data Infrastructure Management for Observability?
To fix this problem, you need to rethink data infrastructure management.
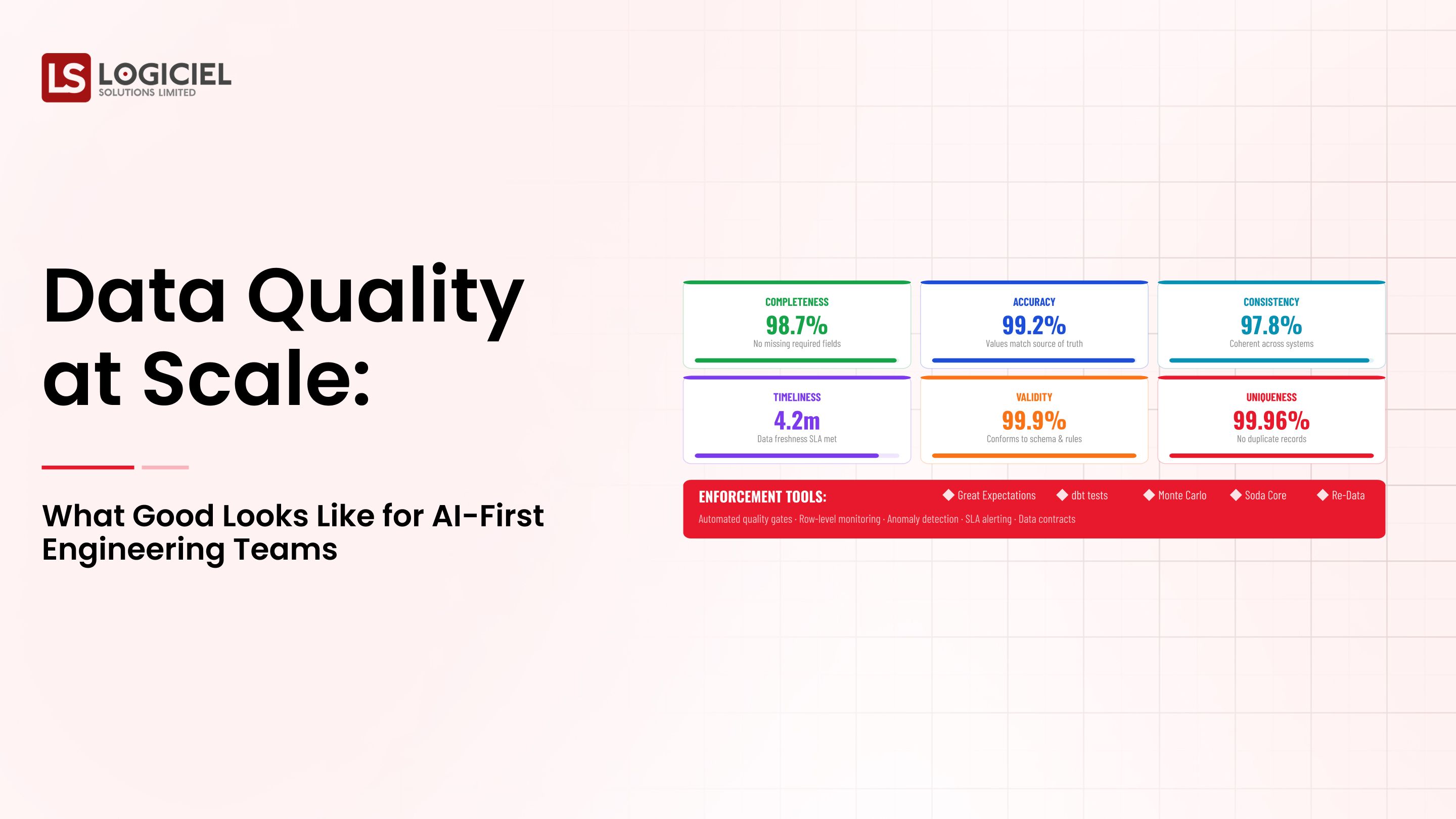
1. Data Quality Monitoring
- Track Missing Values
- Track Unexpected Records
Track AnomaliesThe ability to see what you have in your data is called Data Lineage.
Understand: Where is your data coming from, and how will it be impacted by future processes?
To maintain data health, it's important to monitor the pipeline continuously.
Pipeline Health Monitoring - Includes looking at:
- Ben: Latency
- Bonnie: Throughput
- Brad: Failure
Schema Management - Refers to understanding and controlling the schema of data
Changes
Upper: Schema compatibility will be critical as a company moves forward.
Alerting and Incident Management
1. Alerts should go to the right teams at the right time.
Key takeaway: Multiple layers are needed to achieve observability.
- Choosing the Best Data Infrastructure Platforms-in-the-cloud Environments
- Modern-day observability relies on cloud-native architectures.
Amazon Web Services:
- Scalability of capabilities
- The ability to integrate with multiple monitoring solutions
Google Cloud Platform:
Advanced analytics
Microsoft Azure:
Enterprise-level governance
Things to Consider:
- Integrating with current pipeline systems
- Real-time monitoring
- Scalability
Key takeaway: The platform you choose is important, but how you implement that platform is even more important.
Cost-Optimizing Your Cloud Data Storage and Observability Investment
While observability will increase overhead, not being able to obtain good data will lead to even more significant increases in your costs.
Cost Types Associated with Observability:
- Storage of data in cloud environments
- The cost of monitoring systems
- The cost of computing resources
Cost-Optimization Strategies for Cloud Data Storage and Observability:
- Having tiered storage
- Only monitor critical pipelines
- Automation of anomaly detection
Key takeaway: You want to be cost-optimizing value, not to just save money.
Best Practices for Securing Sensitive Data in Observability Systems
Observability systems obtain sensitive information from organizations.
Best Practices:
- Mask any of the sensitive data stored as part of a record
- Dual controls for full access/restriction to sensitive data
- Ensure encryption of data while in transit or at rest.
Key takeaway: Observability should not have negative impacts on data security.
Evaluating Platforms Supporting Real-time Data Streaming
The ability to provide observability is increased with real-time systems.
Important Criteria:
- Latency of a real-time data stream
- The ability for a real-time data stream to scale as required with business growth
- The ability to integrate the real-time data stream with existing systems
Key takeaway: Real-time observability will decrease your ability to respond to outage events.
Benefits of Automated DataBenefits
- The speed of identifying problems
- Reduced human labor
- Greater consistency
Advantages of Automated Data Infrastructure Management Software
Automation offers:
- Ongoing review
- Self-healing delivery cycles
- Predictive data modeling tools
Significant point:
Automation transforms teams from a react-to-react form of performing their duties to a pro-active style of working.
How to Automate Your Data Pipeline/Delivery and Monitoring Using Automation
Automation should include:
1. Pipeline Delivery
Continuous Integration/Continuous Delivery (CI/CD) for pipeline delivery
2. Monitoring
Automated alerts Detection of data anomalies
3. Incident Management
Automated restoration

Key Point:
Automation greatly reduces human error and increases continuity.
Comparison of Data Infrastructure Management Tools with Integrated AI Technology
AI has been integrated into current software.
Features of Data Infrastructure Management Tools
- Detection of data anomalies
- Root Cause Analysis
- Predictive Monitoring
Trade-offs By Using AI Technology
- Greater complexity
- Greater expense
The Anticipated Benefit
Using AI to create integrated Data Infrastructure Management Solutions will improve speed however will potentially need sound management.
Data Lakehouse vs. Data Warehouse
Architecture and Infrastructure Management:
Data Warehouse
- Structured Data
- Strong Management
Data Lakehouse
- Flexible Data Storage
- Multiple Workloads
Impact on Data Infrastructure Management:
- Easier to monitor data in a data warehouse
- More difficult to monitor data in a data lakehouse
Choose Your Architecture Based on Data Infrastructure Management Needs and Not Only on Scalability.
How to Choose Your Data Infrastructure Management Tool to Use within the Enterprise
Most important criteria are:
- Scalability
- Integration
- Ease of Use
- Observability feature
Questions to Ask Themselves
- Is there end to end visibility?
- Can the software detect data anomalies?
- Does the software integrate with existing tools they use?
Key Point:
The selection of a Due Data Infrastructure Management Tool has to be taken seriously in relation to their architecture and maturity of their teams.
Real Life Example: Silent Pipeline Failure
Problem:
An e-commerce business depends greatly on real-time dashboards.
They're constantly pulling data from their pipelines.
What happens?
Due to a change in the schema of one of their pipelines, data is dropped by the pipeline.
The system thinks it is successful.
How is this going to affect them?
Revenue will show incorrect counts.
They'll make business decisions without all the required information.
Solution:
- Create and implement observability for all pipelines.
- Add to the observability of the pipeline a schema validation process.
- Real-time alerts need to be sent when there has been a schema change.
Results of Following the Solution:
- Ability to identify a problem more quickly.
- Less negative impact on the business based on delayed responses to data.
- Created greater trust in the data.
Key Point:
Using observability systems will transform the result from an incident to a manageable event
The Future of Data Infrastructure Management
1. Data Infrastructure Management Tools will include AI as the primary means of providing observability to businesses.
AI-driven observability systems will provide predictions to when systems will fail prior to the event happening.
2. Unified Data Platforms - One tool that allows for a single view of the data.
3. Data Contracts - Business arrangement between the Data Infrastructure Management Tool provider and the user that guarantees that the level and quality of service defined will be provided.
4. Self-Healing Systems - technology that provides the ability to automatically fix issues within the Data Infrastructure Management Tool.
Key Point:
Observability will be a fundamental building block of Data Infrastructure Management.
Conclusion - Visibility is Your Competitive Advantage
The problem is being able to know when, where and why a pipeline fails.
A modern data team has to manage a data infrastructure system that goes beyond the data delivery system and the dashboard used to view the results of the data being delivered through pipelines.
A modern data team has to be able to deliver:
- Visibility
- Trust
- Actionability
Logiciel Solutions will assist organizations create their own AI-based observability systems in order to convert their data pipelines into reliable and actionable data infrastructure.
The organizations that will win in modern data systems are the ones that will be able to deliver the data to users in a timelier manner than any other.
RAG & Vector Database Guide
Build the quiet infrastructure behind smarter, self-learning systems. A CTO’s guide to modern data engineering.
Frequently Asked Questions
What is observability for data infrastructure management?
Observability is the ability to monitor, identify and separate issues that arise in the data pipelines that an organization uses to pull data.
Why do data pipelines fail and go undetected?
Data pipelines typically record the activity of a pipeline being executed not necessarily the data quality being produced by the executing pipeline.
What is Data Infrastructure Management?
Data infrastructure management is the management of the systems that hold, move and monitor the data moving through those systems.
How does observability assist with data quality?
Observability will assist in allowing for identifying and fixing problems with data at a much earlier stage of the data delivery life cycle, this allows organizations to have the ability to deliver reliable data to decision-makers.
What are observability tools?
Observability tools measure the tracking, monitoring and detecting of anomalies and data lineage.