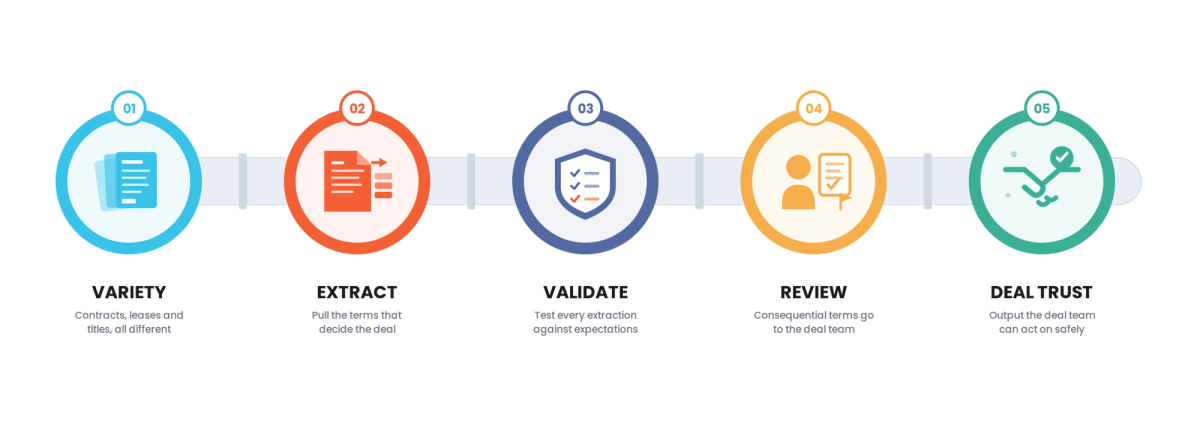
There is a deal in your real estate organization waiting on someone to read a stack of documents, a purchase contract, a set of leases, a title report, and pull the terms that determine whether the deal works. It is slow, expensive, and error-prone, and a missed clause or a misread title exception can be costly. A document-intelligence demo extracted clean terms from a sample, which is why automation is on the table. What the demo did not show is the variety of these documents, the consequence of an extraction error in a contract or title, and the validation that turns extraction into something a deal team can trust.
This is more than a slow review. It is real estate document intelligence where extraction without validation carries deal-level risk.
Document intelligence for real estate extracts terms from contracts, leases, and titles, and doing it reliably is more than running extraction across document types. It is a workflow that handles the variety of real estate documents, extracts the terms that matter, validates them against expectations, and routes the consequential and uncertain to human review, because an extraction error in a contract or title is not a typo, it is a deal-level risk.
However, many teams deploy extraction across document types and trust it uniformly, and discover that a misread title exception or a missed contract clause carries consequences a demo never hinted at.
If you are a real estate or data leader automating document review, the intent of this article is:
- Define what reliable real estate document intelligence requires
- Walk through handling document variety, extraction, and validation
- Lay out the controls a production workflow needs
To do that, let's start with the basics.
Why ML Pilots Fail in Production
Inside an 8-month rebuild that turned three failed pilots into a 9:1 ROI model.
What Is Real Estate Document Intelligence? The Basic Definition
At a high level, real estate document intelligence is using AI to extract and structure information from contracts, leases, and titles, reliably done through a workflow that handles document variety, extracts key terms, validates them, and routes consequential and uncertain extractions to human review.
To compare:
If manual document review is an experienced analyst reading carefully, document intelligence without validation is a fast reader who never double-checks a consequential clause. The speed is valuable; the validation and review are what keep a fast read from becoming a costly miss on a contract or title.
Why Is Reliable Document Intelligence Necessary?
Issues that reliable document intelligence addresses or resolves:
- Handling the variety of real estate document types
- Preventing consequential extraction errors in contracts and titles
- Producing structured terms a deal team can trust
Resolved Issues by Reliable Document Intelligence
- Extracts across contracts, leases, and titles
- Validates extractions against expectations
- Routes consequential and uncertain terms to review
Core Components of Reliable Document Intelligence
- Handling of varied document types and formats
- Extraction of the terms that matter per document type
- Validation against expectations
- Human review of consequential and uncertain terms
- Structured output with provenance
Modern Document Intelligence Tooling
- Document AI and LLM extraction across document types
- OCR for scanned contracts, leases, and titles
- Type-specific extraction and validation
- Human-in-the-loop review interfaces
- Structured output traceable to the source
These tools enable document intelligence; the discipline is validation and review proportional to the consequence.
Other Core Issues They Will Solve
- Speed up deal due diligence
- Improve consistency over manual review
- Provide structured document data for the deal team
Importance of Real Estate Document Intelligence in 2026
Reliable document intelligence matters more as extraction is trusted in deals. Four reasons explain why it matters now.
1. The documents are consequential.
Contracts and titles determine whether deals work. Extraction errors here are deal-level risks, not typos.
2. The documents vary widely.
Real estate documents come in many formats and structures. Extraction must handle the variety, not just a clean sample.
3. Confident errors carry consequence.
A misread title exception or missed clause, confidently extracted and unchecked, can be costly. Validation and review catch it.
4. Speed must not sacrifice reliability.
Document intelligence must be more reliable than careful manual review where it matters, not just faster.
Traditional vs. Reliable Document Intelligence
- Manual review vs. AI extraction with validation
- Uniform trust vs. validation and consequence-based review
- Speed alone vs. speed plus reliability
- Output without provenance vs. structured data traceable to source
In summary: Reliable real estate document intelligence handles document variety, validates extractions, and reviews the consequential and uncertain, producing trustworthy structured terms.
Details About the Core Components of Reliable Document Intelligence: What Are You Designing?
Let's go through each layer.
1. Variety Layer
Handling document types.
Variety decisions:
- Contracts, leases, and titles handled
- Varied formats and structures
- OCR for scanned documents
2. Extraction Layer
Getting the right terms.
Extraction decisions:
- Type-specific terms extracted
- The terms that matter per document
- Handling of unusual clauses
3. Validation Layer
Checking the extraction.
Validation decisions:
- Validation against expectations
- Consistency and anomaly checks
- Type-specific validation rules
4. Consequence Layer
Routing by stakes.
Consequence decisions:
- Consequential terms reviewed even at confidence
- Uncertain extractions routed to review
- Review proportional to risk
5. Output Layer
Trustworthy structured data.
Output decisions:
- Structured output with provenance
- Traceability to the source document and location
- Trustworthy for the deal team
Benefits Gained from Validation and Consequence-Based Review
- Fast extraction across document types with trustworthy output
- Consequential errors caught before they affect a deal
- Structured document data the deal team can rely on
How It All Works Together
The workflow handles the variety of real estate documents, contracts, leases, titles, in their many formats, using OCR for scanned ones. It extracts the terms that matter per document type, including unusual clauses, and validates each against type-specific expectations with consistency and anomaly checks. Routing is by consequence and confidence: consequential terms, like title exceptions and key contract clauses, are reviewed even at confidence, and uncertain extractions are routed to human review, with effort proportional to risk. The structured output carries provenance to the source document and location, so any term can be verified. The deal team gets fast, trustworthy structured terms, because extraction across consequential documents is validated and reviewed, not trusted uniformly.
Common Misconception
If document intelligence extracts terms well across document types, the output is ready to use.
Extraction is capable but not infallible across varied, consequential documents, and an error in a contract or title is a deal-level risk, not a typo. Reliable document intelligence requires validation and human review proportional to consequence, not uniform trust in extraction.
Key Takeaway: Inreal estate documents, an extraction error is consequential. Validation and consequence-based review are what make fast extraction trustworthy for a deal.
Real-World Document Intelligence in Action
Let's take a look at how reliable document intelligence operates with a real-world example.
We worked with a team automating document review and trusting extraction uniformly, with these constraints:
- Handle the variety of real estate documents
- Catch consequential errors before they affect deals
- Keep the speed advantage over manual review
Step 1: Handle Document Variety
Cover the types and formats.
- Contracts, leases, titles handled
- Varied formats and OCR for scans
- Unusual clauses handled
Step 2: Extract the Right Terms
Get what matters.
- Type-specific terms extracted
- Terms that matter per document
- Edge cases handled
Step 3: Validate the Extraction
Check the output.
- Validation against type-specific expectations
- Consistency and anomaly checks
- Errors flagged
Step 4: Route by Consequence
Apply review where it matters.
- Consequential terms reviewed at confidence
- Uncertain extractions routed
- Review proportional to risk
Step 5: Produce Traceable Output
Make it trustworthy.
- Structured output with provenance
- Traceable to source and location
- Trustworthy for the deal team
Where It Works Well
- Document variety handled with type-specific extraction and validation
- Consequential and uncertain terms reviewed
- Structured output traceable to the source document
Where It Does Not Work Well
- Trusting extraction uniformly across consequential documents
- No review of consequential terms like title exceptions
- Output with no provenance, so errors cannot be traced
Key Takeaway: The document intelligence a deal team can trust is the one that handles variety, validates extraction, and reviews the consequential and uncertain, not the one that trusts extraction because it worked on a clean sample.
Common Pitfalls
i) Uniform trust across documents
Trusting extraction the same on a title as on a routine document ignores consequence. Review proportional to stakes.
- Validate extractions
- Review consequential terms
- Route the uncertain
ii) Ignoring document variety
Real estate documents vary widely. Extraction tuned to a clean sample fails on the variety. Handle the range with OCR and type-specific logic.
iii) No review of consequential terms
Title exceptions and key clauses warrant review even at confidence. Skipping it risks deal-level errors.
iv) No provenance
Output that cannot be traced to the source document cannot be verified. Carry provenance to source and location.
Takeaway from these lessons: Most document-intelligence errors trace to uniform trust and ignored consequence, not to extraction capability. Validate, review by consequence, and trace to source.
Document Intelligence Best Practices: What High-Performing Teams Do Differently
1. Handle the document variety
Cover contracts, leases, and titles in their many formats, with OCR and type-specific extraction. A clean-sample model fails on real variety.
2. Validate extractions
Validate against type-specific expectations and check consistency, so output is trustworthy, not just fast.
3. Review by consequence
Review consequential terms, title exceptions, key clauses, even at confidence, and route uncertain extractions to humans.
4. Carry provenance
Trace every structured term to its source document and location, so any value can be verified.
5. Beat manual review on reliability
Ensure the workflow is more reliable than careful manual review where it matters, not just faster.
Logiciel's value add is helping real estate teams build document-intelligence workflows that handle document variety, validate extraction, and review the consequential and uncertain, producing structured terms a deal team can trust.
Takeaway for High-Performing Teams: Focus on validation and consequence-based review. Real estate document intelligence is valuable when fast extraction is paired with the checking that matches the deal-level consequence of an error.
Signals You Are Doing Document Intelligence Reliably
How do you know the workflow is sound? Not in extraction speed, but in trustworthiness on consequential documents. Below are the signals that distinguish reliable document intelligence from uniform trust.
Variety is handled. The team handles contracts, leases, and titles in their real formats, not just a clean sample.
Extraction is validated. The team validates against type-specific expectations and checks consistency.
Review matches consequence. Consequential terms are reviewed even at confidence; uncertain ones are routed.
Output is traceable. Structured terms carry provenance to the source document and location.
Reliability beats manual. The team can show the workflow is more reliable, not just faster, where it matters.
Adjacent Capabilities and Connected Work
This work does not exist in isolation. Real estate document intelligence depends on, and feeds into, several adjacent capabilities. Building one without thinking about the others is the most common scoping mistake.
In most real estate organizations, document intelligence shares infrastructure with the document management system, the deal and property data platform, and the due-diligence workflow. It shares capacity with data engineering, the deal team, and the legal reviewers. And it shares leadership attention with whatever the next data-automation initiative is on the roadmap. Naming these adjacencies upfront helps the program scope realistically and helps leadership see the work as a portfolio rather than a one-off project.
The most common mistake in adjacent-capability scoping is treating each adjacency as someone else's problem. The document store the documents come from is your problem. The human review workflow is your problem. The deal team consuming the structured terms is your problem. Pretending otherwise pushes work to teams that did not plan for it, and the work returns to you later as a missed clause in a deal. Own the adjacencies you depend on; partner with the teams that own them; share the timeline.
Conclusion
Document intelligence for real estate extracts terms from contracts, leases, and titles, and doing it reliably means handling document variety and pairing extraction with validation and consequence-based review. The discipline that delivers it is the same discipline behind any high-stakes extraction: check the output, review by consequence, and make it traceable.
Key Takeaways:
- Real estate document errors are deal-level risks, not typos
- Handle document variety and pair extraction with validation
- Review by consequence, carry provenance, and beat manual on reliability
Doing document intelligence reliably requires variety, validation, and consequence discipline. When done correctly, it produces:
- Fast extraction across document types with trustworthy output
- Consequential errors caught before they affect a deal
- Structured document data the deal team can rely on
- Traceability from every term to its source
Why Functional Infrastructure Fails Due Diligence
Inside a 90-day sprint that took a flagged round to a $28M close.
What Logiciel Does Here
If you are automating real estate document review, handle the document variety, validate extractions, review consequential and uncertain terms, and carry provenance before trusting the data in a deal.
Learn More Here:
- Lease Abstraction with AI: From PDFs to Structured Data
- Real Estate Underwriting AI: Models for Commercial Investment Decisions
- Data Quality and Anomaly Detection
At Logiciel Solutions, we work with real estate and data leaders on document intelligence, extraction validation, and human-in-the-loop workflows. Our reference patterns come from production document-extraction systems.
Explore how to handle real estate contracts, leases, and titles with reliable document intelligence.
Frequently Asked Questions
What is document intelligence for real estate?
Using AI to extract and structure information from real estate documents, contracts, leases, and titles, reliably done through a workflow that handles document variety, extracts the terms that matter, validates them, and routes consequential and uncertain extractions to human review.
Why isn't extraction alone enough for real estate documents?
Because extraction is capable but not infallible across varied, consequential documents, and an error in a contract or title is a deal-level risk rather than a typo. Validation and human review proportional to consequence are what make the output trustworthy.
Which extracted terms need human review?
Consequential terms, such as title exceptions and key contract clauses, warrant review even at decent confidence, and uncertain extractions of any kind should be routed to a human. Review effort should be proportional to the deal-level risk of an error.
How does document intelligence handle the variety of documents?
By handling many formats and structures, using OCR for scanned documents, and applying type-specific extraction and validation for contracts, leases, and titles. A model tuned only to a clean sample fails on the real variety of documents.
What is the biggest mistake in real estate document intelligence?
Trusting extraction uniformly across consequential documents because it worked on a clean sample. A confidently misread title exception or missed clause carries deal-level consequences. Handle the variety, validate extractions, review by consequence, and trace terms to their source.