


There is a vector store in your organization holding millions of embeddings that power search, recommendations, or retrieval, and it was populated once and largely left alone. Then the embedding model was upgraded, and now new content is embedded with the new model while the old content still carries the old one, so they are no longer comparable. Or the underlying content changed and the embeddings did not refresh, so they describe stale data. The embeddings were treated as a one-time artifact, not a managed asset that must stay consistent and current.
This is more than a stale index. It is embeddings treated as a one-time artifact rather than managed at scale.
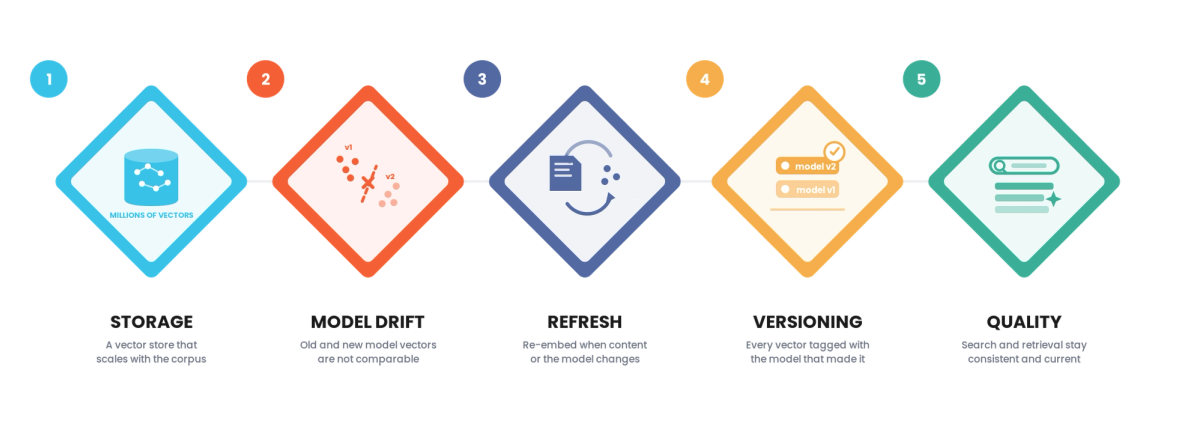
Managing embeddings at scale is more than generating and storing vectors. It is storage that scales, refresh when the model or underlying data changes, and versioning so all embeddings in use come from the same model and stay comparable. Embeddings power features whose quality depends on consistency and currency, and at scale, model upgrades and data changes break both unless storage, refresh, and versioning are managed.
However, many teams generate embeddings once and discover, after a model upgrade or data change, that inconsistent or stale embeddings silently degrade the features they power.
If you are an ML or data platform leader running embedding-based features, the intent of this article is:
- Define what managing embeddings at scale requires
- Walk through storage, refresh, and versioning
- Lay out the controls a production embedding system needs
To do that, let's start with the basics.
Where Health Data Standards Break in Real Systems
Why FHIR R4 certification does not equal FHIR interoperability, the specific data availability.
What Is Managing Embeddings at Scale? The Basic Definition
At a high level, managing embeddings at scale is maintaining the embeddings that power features as a consistent, current asset, through scalable storage, refresh when the model or data changes, and versioning so all embeddings in use are comparable, rather than treating them as a one-time artifact.
To compare:
If a one-time embedding index is a map drawn once and never updated, managed embeddings are a maintained map that updates when the territory changes and is redrawn consistently when the surveying method changes. The features relying on it need the map current and internally consistent.
Why Is Managing Embeddings at Scale Necessary?
Issues that managing embeddings addresses or resolves:
- Keeping all embeddings comparable after a model upgrade
- Refreshing embeddings when underlying data changes
- Maintaining consistency and currency at scale
Resolved Issues by Managing Embeddings
- Keeps embeddings consistent across a model change
- Refreshes embeddings when data changes
- Versions embeddings so all in use are comparable
Core Components of Managing Embeddings at Scale
- Scalable vector storage
- Refresh on model or data change
- Versioning of embeddings to the model
- Consistency across all embeddings in use
- Monitoring of staleness and consistency
Modern Embedding Tooling
- Vector databases and stores
- Embedding generation pipelines
- Versioning and model tracking
- Refresh and re-embedding jobs
- Monitoring of consistency and staleness
These tools support management; the discipline is treating embeddings as a managed asset, not a one-time artifact.
Other Core Issues They Will Solve
- Maintain feature quality through changes
- Avoid silent degradation from stale or inconsistent embeddings
- Support model upgrades without breaking comparability
Importance of Managing Embeddings in 2026
Managing embeddings matters more as embedding-based features proliferate. Four reasons explain why it matters now.
1. Embeddings power critical features.
Search, recommendations, and retrieval depend on embeddings. Their quality depends on embedding consistency and currency.
2. Model upgrades break comparability.
Upgrading the embedding model makes new and old embeddings incomparable unless versioned and re-embedded. The upgrade silently degrades features.
3. Data changes make embeddings stale.
When underlying content changes, embeddings that do not refresh describe stale data. Refresh keeps them current.
4. Scale makes management essential.
At millions of embeddings, consistency and currency cannot be maintained ad hoc. Storage, refresh, and versioning must be managed.
Traditional vs. Managed Embeddings
- Generate once vs. manage as a consistent, current asset
- Mixed model versions vs. versioned, comparable embeddings
- Stale on data change vs. refreshed on change
- One-time artifact vs. managed at scale
In summary: Managing embeddings at scale maintains them as a consistent, current asset through storage, refresh, and versioning, not a one-time artifact.
Details About the Core Components of Managing Embeddings: What Are You Designing?
Let's go through each layer.
1. Storage Layer
Holding the vectors.
Storage decisions:
- Scalable vector storage
- Efficient retrieval at scale
- Capacity for millions of embeddings
2. Refresh Layer
Keeping current.
Refresh decisions:
- Re-embedding when underlying data changes
- Refresh cadence or triggers
- Staleness avoided
3. Versioning Layer
Keeping comparable.
Versioning decisions:
- Embeddings versioned to the model
- All in use from the same model
- Re-embedding on model upgrade
4. Consistency Layer
Uniform across the store.
Consistency decisions:
- No mixed model versions in use
- Comparability maintained
- Migrations handled
5. Monitoring Layer
Tracking health.
Monitoring decisions:
- Staleness and consistency monitored
- Feature quality tracked
- Issues detected
Benefits Gained from Managing Embeddings
- Embeddings consistent and comparable across changes
- Features kept current and high-quality
- Model upgrades handled without silent degradation
How It All Works Together
Embeddings live in scalable vector storage that supports efficient retrieval across millions of vectors. When underlying content changes, refresh jobs re-embed the affected items so the embeddings stay current rather than describing stale data. Embeddings are versioned to the model that produced them, and on a model upgrade, the store is re-embedded so all embeddings in use come from the same model and remain comparable, rather than mixing versions. Consistency is maintained across the store, with migrations handled, and staleness, consistency, and feature quality are monitored. The features powered by embeddings stay current and high-quality through model upgrades and data changes, because the embeddings are managed as an asset, not left as a one-time artifact.
Common Misconception
Once embeddings are generated and stored, the work is done.
Embeddings power features whose quality depends on consistency and currency, and at scale, model upgrades and data changes break both. Treating embeddings as a one-time artifact leads to mixed model versions and stale vectors that silently degrade features. Managing storage, refresh, and versioning is the ongoing work.
Key Takeaway: Embeddings are a managed asset, not a one-time artifact. Their value depends on staying consistent and current through model upgrades and data changes.
Real-World Embedding Management in Action
Let's take a look at how managing embeddings operates with a real-world example.
We worked with a team whose embeddings degraded after a model upgrade, with these constraints:
- Keep all embeddings comparable after model changes
- Refresh embeddings when data changes
- Maintain consistency at scale
Step 1: Scale the Storage
Hold the vectors.
- Scalable vector storage
- Efficient retrieval
- Capacity for millions
Step 2: Refresh on Data Change
Stay current.
- Re-embedding on data change
- Refresh cadence or triggers
- Staleness avoided
Step 3: Version to the Model
Stay comparable.
- Embeddings versioned to the model
- All in use from the same model
- Re-embed on upgrade
Step 4: Maintain Consistency
No mixed versions.
- No mixed model versions in use
- Comparability maintained
- Migrations handled
Step 5: Monitor
Track health.
- Staleness and consistency monitored
- Feature quality tracked
- Issues detected
Where It Works Well
- Scalable storage with refresh and versioning
- All embeddings in use from the same model
- Consistency maintained and monitored
Where It Does Not Work Well
- Generating embeddings once and leaving them
- Mixed model versions after an upgrade
- Stale embeddings after data changes
Key Takeaway: The embedding-based features that stay high-quality are the ones whose embeddings are managed, stored, refreshed, and versioned, not the ones treated as a one-time artifact.
Common Pitfalls
i) Treating embeddings as one-time
Generating once and leaving them leads to staleness and mixed versions that degrade features. Manage them as an asset.
- Refresh on data change
- Version to the model
- Maintain consistency
ii) Mixed model versions
After a model upgrade, new and old embeddings are incomparable. Version and re-embed so all in use are from the same model.
iii) Stale embeddings
Embeddings that do not refresh when data changes describe stale data. Refresh on change.
iv) No monitoring
Without monitoring staleness and consistency, degradation is silent. Monitor and detect.
Takeaway from these lessons: Most embedding-feature degradation traces to treating embeddings as one-time, not to the model. Manage storage, refresh, and versioning, and monitor.
Embedding Management Best Practices: What High-Performing Teams Do Differently
1. Treat embeddings as a managed asset
Maintain embeddings as consistent and current, not a one-time artifact, through storage, refresh, and versioning.
2. Version embeddings to the model
Version embeddings to the model that produced them so all in use are comparable, and re-embed on upgrade.
3. Refresh on data change
Re-embed affected items when underlying content changes so embeddings stay current.
4. Maintain consistency at scale
Avoid mixed model versions in use and handle migrations so embeddings remain comparable.
5. Monitor staleness and consistency
Monitor for staleness, mixed versions, and feature quality so degradation is caught, not silent.
Logiciel's value add is helping teams manage embeddings at scale, scalable storage, refresh, versioning, and consistency, so embedding-based features stay current and high-quality through model upgrades and data changes.
Takeaway for High-Performing Teams: Focus on managing embeddings as an asset. Embedding-based feature quality depends on consistency and currency, which model upgrades and data changes break unless storage, refresh, and versioning are managed.
Signals You Are Managing Embeddings Correctly
How do you know embeddings are well-managed? Not in the initial index, but in consistency and currency over time. Below are the signals that distinguish managed embeddings from a one-time artifact.
Embeddings are versioned. The team versions embeddings to the model and re-embeds on upgrade.
All in use are comparable. No mixed model versions are in use.
Embeddings stay current. Re-embedding happens when underlying data changes.
Storage scales. The store handles millions of embeddings with efficient retrieval.
Consistency is monitored. The team monitors staleness, consistency, and feature quality.
Adjacent Capabilities and Connected Work
This work does not exist in isolation. Managing embeddings depends on, and feeds into, several adjacent capabilities. Building one without thinking about the others is the most common scoping mistake.
In most organizations, embedding management shares infrastructure with the vector store, the embedding and model pipeline, and the feature and retrieval systems. It shares capacity with ML engineering, data engineering, and the teams owning the features. And it shares leadership attention with whatever the next AI feature initiative is on the roadmap. Naming these adjacencies upfront helps the program scope realistically and helps leadership see the work as a portfolio rather than a one-off project.
The most common mistake in adjacency-capability scoping is treating each adjacency as someone else's problem. The model upgrades that require re-embedding are your problem to handle. The data changes that require refresh are your problem. The features consuming embeddings are your problem. Pretending otherwise pushes work to teams that did not plan for it, and the work returns to you later as silently degraded features. Own the adjacencies you depend on; partner with the teams that own them; share the timeline.
Conclusion
Managing embeddings at scale maintains them as a consistent, current asset, through scalable storage, refresh on model and data change, and versioning, so embedding-based features stay high-quality. The discipline that delivers it is the same discipline behind any managed asset: store it, keep it current, and version it for consistency.
Key Takeaways:
- Embeddings are a managed asset, not a one-time artifact
- Version embeddings to the model and re-embed on upgrade
- Refresh on data change and monitor consistency and staleness
Managing embeddings well requires storage, refresh, and versioning discipline. When done correctly, it produces:
- Embeddings consistent and comparable across changes
- Features kept current and high-quality
- Model upgrades handled without silent degradation
- Monitored consistency and currency
Why Most Healthcare AI Projects Fail
The four infrastructure failure modes that determine whether a promising clinical AI pilot becomes a production system.
What Logiciel Does Here
If your embeddings were generated once and left alone, manage them at scale: scalable storage, refresh on data change, versioning to the model, and monitoring of consistency.
Learn More Here:
- RAG (Retrieval-Augmented Generation) Implementation
- Bedrock Knowledge Bases: Managed RAG and Its Limits
- ML Model Monitoring and Drift Detection
At Logiciel Solutions, we work with ML and data platform leaders on embedding management, vector storage, and versioning. Our reference patterns come from production embedding-based systems.
Explore how to manage embeddings at scale: storage, refresh, and versioning.
Frequently Asked Questions
What does managing embeddings at scale mean?
Maintaining the embeddings that power features as a consistent, current asset, through scalable storage, refresh when the model or underlying data changes, and versioning so all embeddings in use come from the same model and stay comparable, rather than treating them as a one-time artifact.
Why do model upgrades break embeddings?
Because embeddings from different models are not comparable. After an upgrade, new content embedded with the new model and old content with the old model occupy different spaces, silently degrading search, recommendations, or retrieval unless the store is re-embedded so all embeddings come from the same model.
When should embeddings be refreshed?
When the underlying content they represent changes. Embeddings that do not refresh after a data change describe stale data, degrading the features they power. A refresh cadence or change-triggered re-embedding keeps them current.
Why version embeddings?
So you know which model produced each embedding and can ensure all embeddings in use are comparable. Versioning enables controlled re-embedding on model upgrades and prevents the silent mixing of model versions that degrades features.
What is the biggest mistake with embeddings?
Treating them as a one-time artifact, generating and storing them once and leaving them. At scale, model upgrades and data changes break consistency and currency, silently degrading the features embeddings power. Manage storage, refresh, and versioning, and monitor consistency.

