Energy and utilities teams often run critical data pipelines, grid telemetry, meter data, operational feeds, with little visibility into whether they are actually working, and the instinct to fix that by rebuilding the pipelines with monitoring built in is exactly what risks disrupting the operations those pipelines support. The way to add pipeline monitoring without disruption is the opposite: instrument the running pipelines incrementally, starting where a silent failure hits operations hardest. You get visibility into pipeline health without taking the pipelines, or the operations, offline.
Real Estate SaaS Reduced AWS Costs 38%
An AWS cost optimization playbook for FinOps Leads who need durable savings, not one-time wins.
Pipeline monitoring is the practice of knowing whether your data pipelines are running and producing correct data, so a silent failure is caught before it affects what depends on the data. For energy and utilities, where pipelines feed operational and grid-related systems, that visibility matters. Implementing it without disruption means instrumenting the existing pipelines incrementally rather than rebuilding them.
What Pipeline Monitoring Is
Pipeline monitoring watches data pipelines for whether they ran, whether they produced the expected data (volume, freshness, schema, quality), and whether they failed, so problems are caught before consumers feel them. It is the difference between knowing a pipeline broke from an alert versus from a wrong operational dashboard hours later. For energy and utilities, the pipelines feed systems that can affect operations, so monitoring their health is about catching failures before they reach operational decisions, which makes adding it without disrupting the running pipelines important.
How Energy & Utilities Teams Do It Without Disruption
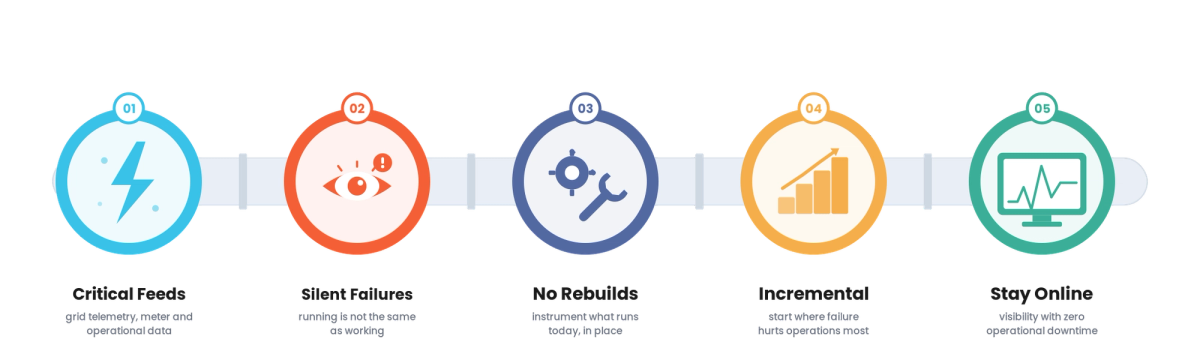
- Instrument running pipelines, do not rebuild them. Add monitoring to the existing pipelines in place, rather than rebuilding them with monitoring built in, which would risk disrupting the operations they support.
- Start where failures hit operations hardest. Prioritize monitoring the pipelines whose silent failure would most affect operational or grid-related systems. That is where visibility matters most.
- Monitor the data, not just the job. Watch whether pipelines produced correct data (freshness, volume, schema), not just whether the job ran, since a job can succeed and produce wrong data.
- Add monitoring incrementally. Instrument pipelines one at a time, delivering visibility as you go and bounding any risk, rather than a big-bang instrumentation.
- Make alerts actionable and owned. Route pipeline alerts to the team that owns the pipeline, with enough context to act, so detection becomes a fix.
- Connect to operational impact. Tie monitoring to the operational systems the pipelines feed, so a pipeline failure is understood in terms of its operational consequence.
Common Misconception
The misconception that risks operations: adding pipeline monitoring means rebuilding the pipelines with monitoring built in.
Rebuilding running pipelines to add monitoring risks disrupting the operations they support, which energy and utilities cannot afford. Monitoring can be added to existing pipelines in place, incrementally, without rebuilding them. Equating monitoring with rebuilding chooses the disruptive path for a capability that can be added non-disruptively. The visibility comes from instrumenting the running pipelines, not from rebuilding them.
Key Takeaway: Energy and utilities teams add pipeline monitoring without disruption by instrumenting running pipelines incrementally, starting where failures hit operations, not by rebuilding the pipelines.
Where the Approach Goes Right
- Monitoring added to running pipelines in place, incrementally
- Started where silent failures most affect operations
- Data-level monitoring (not just job success), with actionable owned alerts
Where It Goes Wrong
- Rebuilding running pipelines and disrupting operations
- Monitoring that the job ran but not whether the data is correct
- Big-bang instrumentation that risks the operations the pipelines support
Key Takeaway: Energy and utilities teams get pipeline visibility safely by instrumenting running pipelines incrementally; rebuilding them to add monitoring risks the operations they support.
What High-Performing Energy & Utilities Teams Do Differently
- Instrument running pipelines in place, not rebuild them.
- Start where silent failures most affect operations.
- Monitor the data produced, not just job success.
- Add monitoring incrementally to bound risk.
- Make alerts actionable, owned, and tied to operational impact.
Logiciel's value add is helping energy and utilities teams add pipeline monitoring without disruption, instrumenting running pipelines incrementally, monitoring the data, and making alerts actionable, so silent pipeline failures are caught before they affect operations.
Takeaway for High-Performing Teams: Add pipeline monitoring by instrumenting running pipelines incrementally, starting where failures hit operations, not by rebuilding them. The visibility comes from instrumenting what runs, and doing it incrementally keeps the operations the pipelines support undisrupted.
Adjacent Capabilities and Connected Work
Pipeline monitoring shares infrastructure with the data pipelines, the operational systems they feed, and the alerting process, and shares team capacity with data engineering, operations, and platform engineering. The common scoping mistake is treating each adjacency as someone else's problem: the data-level monitoring is your problem, the alert ownership is your problem, the operational-impact connection is your problem. Pretending otherwise returns later as a silent pipeline failure that reached an operational decision. Own the adjacencies, partner with the teams that own them, share the timeline.
Conclusion
Energy and utilities teams implement pipeline monitoring without disruption by instrumenting their running pipelines incrementally, starting where a silent failure would most affect operations, monitoring the data produced (not just job success), and making alerts actionable and tied to operational impact. The disruptive path, rebuilding the pipelines to add monitoring, risks the operations they support. The visibility comes from instrumenting what already runs, incrementally, so operations stay undisrupted.
Key Takeaways:
- Add monitoring by instrumenting running pipelines, not rebuilding them
- Start where silent failures most affect operations
- Monitor the data produced, with actionable, operationally-connected alerts
CTO Consolidated Six Observability Tools Into One
An observability consolidation playbook for CTOs paying the observability tax.
What Logiciel Does Here
If your energy or utilities pipelines run with little visibility, add monitoring without disruption: instrument the running pipelines incrementally, starting where failures hit operations.
Learn More Here:
- From Strategy to Production: Pipeline Monitoring with an Engineering Partner
- A Practical Roadmap to Data Observability
- The On-Call Data Engineer: Runbooks for 3 AM Pipeline Failures
At Logiciel Solutions, we work with energy and utilities teams on pipeline monitoring, non-disruptive instrumentation, data-level monitoring, and actionable alerting. Our reference patterns come from production operational data pipelines.
Explore how energy and utilities teams implement pipeline monitoring without disruption.
Frequently Asked Questions
What is pipeline monitoring?
The practice of watching data pipelines for whether they ran, whether they produced the expected data (freshness, volume, schema, quality), and whether they failed, so a problem is caught before consumers feel it. It is the difference between learning a pipeline broke from an alert versus from a wrong operational dashboard hours later.
How do you add it without disrupting operations?
By instrumenting the existing, running pipelines in place, incrementally, rather than rebuilding them with monitoring built in. Rebuilding running pipelines risks disrupting the operations they support, which energy and utilities cannot afford. Monitoring can be added to pipelines as they run, one at a time, delivering visibility without taking the pipelines or operations offline.
Where should energy and utilities teams start?
With the pipelines whose silent failure would most affect operational or grid-related systems. That is where visibility matters most and where catching a failure early has the greatest operational benefit. Starting there delivers the most value first, then monitoring is extended incrementally to other pipelines.
Why monitor the data, not just whether the job ran?
Because a pipeline job can succeed and still produce wrong data, a half-load, a stale source, a silent schema change. Monitoring only job success misses that. Watching whether the pipeline produced correct data (freshness, volume, schema, quality) catches the silent failures that job-success monitoring misses, which matters when the data feeds operational decisions.
How do you make pipeline monitoring actionable?
Route alerts to the team that owns the pipeline, with enough context to act, and tie them to the operational systems the pipeline feeds so the failure is understood in terms of its operational consequence. An alert nobody owns or understands is noise; an owned, contextual, operationally-connected alert turns detection into a fast fix before operations are affected.