


There is a grid forecasting system in your utility that runs centrally, pulling meter and sensor data to the cloud, computing forecasts, and sending decisions back. For slow, aggregate forecasting that works. For the fast, local decisions the modern grid increasingly needs, at the substation, near the meter, where distributed energy resources swing supply and demand in seconds, the round trip to the cloud is too slow and depends on connectivity that is not always there. The forecasting that needs to happen close to the meter is happening far from it.
This is more than a latency annoyance. It is grid forecasting running centrally where it increasingly needs to run at the edge.
Grid forecasting at the edge is moving forecasting models close to the meter, to substations and field devices, so local forecasts and decisions happen with low latency and without depending on a round trip to the cloud. The driver is the modern grid's need for fast, local decisions as distributed energy resources make conditions change quickly near the edge. It is the same edge AI discipline, applied to the grid: placement, optimization, and fleet management of models near the meter.
However, many utilities keep forecasting centralized and discover that fast, local grid decisions cannot wait for a cloud round trip.
If you are a utility or grid technology leader, the intent of this article is:
- Define why grid forecasting moves to the edge
- Walk through model placement, optimization, and fleet management near the meter
- Lay out the controls a production edge-forecasting deployment needs
To do that, let's start with the basics.
Six Contact Attempts Drive Higher CRM Conversions
Why 6 follow-up attempts convert 3.4x more than 3.
What Is Grid Forecasting at the Edge? The Basic Definition
At a high level, grid forecasting at the edge is running forecasting models close to the meter, at substations and field devices, so local forecasts and decisions happen with low latency and without depending on a cloud round trip, while the central system handles aggregate forecasting.
To compare:
If centralized forecasting is a single weather station forecasting for a whole region, edge forecasting is local sensors forecasting microclimates in real time. The region forecast is useful; the local, fast one is what you need to react to conditions changing block by block.
Why Is Edge Grid Forecasting Necessary?
Issues that edge grid forecasting addresses or resolves:
- Meeting the latency fast local grid decisions require
- Operating when connectivity to the cloud is intermittent
- Forecasting close to where conditions change quickly
Resolved Issues by Edge Forecasting
- Brings forecast latency down to what local decisions need
- Maintains forecasting during connectivity loss
- Forecasts close to the meter where DERs swing conditions
Core Components of Edge Grid Forecasting
- Model placement at substations and field devices
- On-device model optimization
- Fleet management of edge models
- Coordination with central aggregate forecasting
- Monitoring of edge model performance
Modern Edge Grid Tooling
- Edge compute at substations and field devices
- Optimized models for edge hardware
- Fleet deployment and update for edge models
- Local-to-central data synchronization
- Edge model monitoring
These tools enable edge forecasting; the discipline is the edge AI placement and fleet management applied to the grid.
Other Core Issues They Will Solve
- Support real-time DER and grid-edge decisions
- Reduce dependence on cloud connectivity
- Enable local autonomy at the grid edge
Importance of Edge Grid Forecasting in 2026
Edge forecasting matters more as the grid distributes. Four reasons explain why it matters now.
1. The grid edge changes fast.
Distributed energy resources swing supply and demand near the meter in seconds. Decisions there cannot wait for a cloud round trip.
2. Connectivity is not guaranteed.
Field locations have intermittent connectivity. Local forecasting must work without depending on the cloud.
3. Latency drives the placement.
The latency local grid decisions require rules out a central round trip. Placing models at the edge meets it.
4. It is edge AI for the grid.
The discipline, placement, optimization, fleet management, is edge AI applied to the grid, with the grid's reliability stakes.
Traditional vs. Edge Grid Forecasting
- Central forecasting only vs. forecasting at the edge for local decisions
- Cloud round trip vs. low-latency local forecasts
- Cloud-dependent vs. resilient to connectivity loss
- One central model vs. a fleet of edge models coordinated with central
In summary: Edge grid forecasting runs models close to the meter for fast, connectivity-resilient local decisions, coordinated with central aggregate forecasting.
Details About the Core Components of Edge Grid Forecasting: What Are You Designing?
Let's go through each layer.
1. Placement Layer
Where models run.
Placement decisions:
- Models at substations and field devices for local decisions
- Central forecasting for aggregate
- Placement by latency and connectivity needs
2. Optimization Layer
Fitting the edge.
Optimization decisions:
- Models optimized for edge hardware
- Accuracy-versus-resource tradeoff measured
- Resource limits respected
3. Fleet Management Layer
Operating the edge models.
Fleet decisions:
- Versioned models across the edge fleet
- Updates pushed over the air
- Rollback for a bad model
4. Coordination Layer
Edge and central together.
Coordination decisions:
- Edge forecasts coordinated with central aggregate
- Local-to-central data synchronization
- Roles split by latency need
5. Monitoring Layer
Edge performance.
Monitoring decisions:
- Edge model performance monitored in the field
- Drift detected
- Fleet health tracked
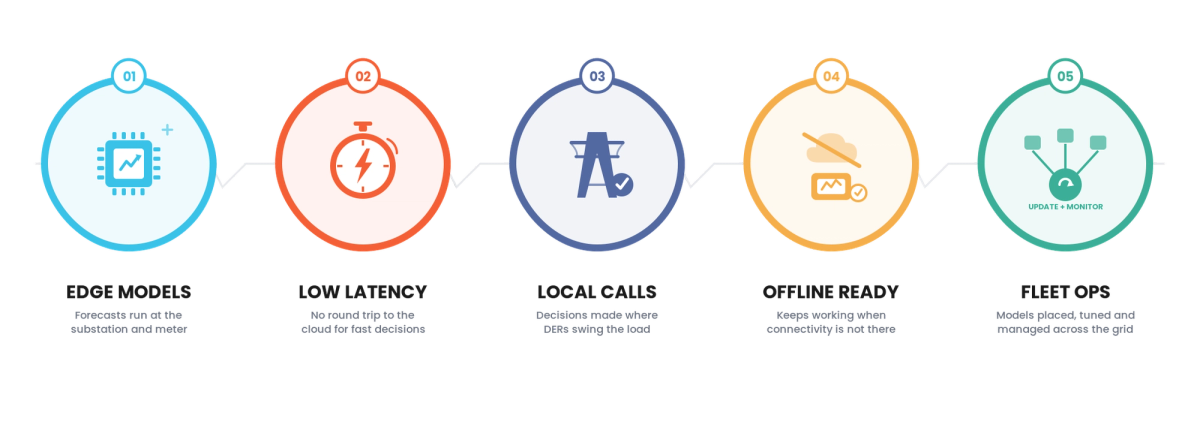
Benefits Gained from Edge Forecasting
- Local grid decisions at the latency they require
- Forecasting resilient to connectivity loss
- Models close to where grid conditions change fast
How It All Works Together
Forecasting models run where the decisions are: at substations and field devices for fast, local decisions, while the central system handles aggregate forecasting. The edge models are optimized for the hardware, with the accuracy-versus-resource tradeoff measured. They are managed as a fleet, versioned, updated over the air, with rollback for a bad model, the same edge AI discipline applied to the grid. Edge forecasts coordinate with central aggregate forecasting, with local-to-central synchronization, and roles split by latency need. Edge model performance is monitored in the field with drift detection. Local grid decisions happen at the latency they need, resilient to connectivity loss, because forecasting moved close to the meter.
Common Misconception
Centralized forecasting is sufficient; we just need more compute.
Centralized forecasting cannot meet the latency fast local grid decisions require, no matter the compute, because of the round trip, and it depends on connectivity field locations may not have. The modern grid's fast, local decisions need models close to the meter. More central compute does not solve a latency and connectivity problem.
Key Takeaway: The issue is not central compute capacity; it is the latency and connectivity of a round trip. Fast local grid decisions need forecasting at the edge.
Real-World Edge Grid Forecasting in Action
Let's take a look at how edge forecasting operates with a real-world example.
We worked with a utility whose forecasting was centralized, with these constraints:
- Meet the latency local grid decisions require
- Operate during connectivity loss
- Forecast close to the meter
Step 1: Decide Placement
Match models to decisions.
- Edge models for local decisions
- Central for aggregate
- Placement by latency and connectivity
Step 2: Optimize for the Edge
Fit the hardware.
- Models optimized for edge devices
- Accuracy-versus-resource tradeoff measured
- Resource limits respected
Step 3: Manage the Edge Fleet
Operate the models.
- Versioned models across the fleet
- Over-the-air updates
- Rollback for bad models
Step 4: Coordinate with Central
Split the roles.
- Edge and central coordinated
- Local-to-central synchronization
- Roles by latency need
Step 5: Monitor the Edge
Keep it reliable.
- Field performance monitored
- Drift detected
- Fleet health tracked
Where It Works Well
- Models placed at the edge for fast local decisions
- Optimized, fleet-managed edge models
- Coordination with central and field monitoring
Where It Does Not Work Well
- Centralized forecasting for fast local decisions
- Dependence on a cloud round trip and connectivity
- Edge models deployed with no fleet management
Key Takeaway: The grid forecasting that meets local decision needs is the one with models at the edge, fleet-managed and coordinated with central, not the centralized system depending on a round trip.
Common Pitfalls
i) Keeping forecasting central
Central forecasting cannot meet local latency or connectivity needs. Place models at the edge for fast local decisions.
- Edge models for local decisions
- Central for aggregate
- Placement by need
ii) No fleet management
Edge models without versioning, updates, and rollback become unmanageable, the same edge AI mistake. Manage the fleet.
iii) Ignoring optimization tradeoffs
Edge hardware is constrained. Measure the accuracy-versus-resource tradeoff rather than assuming it.
iv) No field monitoring
Lab accuracy overstates field reliability. Monitor edge model performance in the field.
Takeaway from these lessons: Most edge grid forecasting trouble traces to keeping it central or skipping fleet management, not to the models. Place at the edge, manage the fleet, and monitor the field.
Edge Grid Forecasting Best Practices: What High-Performing Teams Do Differently
1. Place models by latency and connectivity
Run forecasting at the edge for fast local decisions and centrally for aggregate, placing by what each decision needs.
2. Optimize and measure the tradeoff
Optimize models for edge hardware and measure the accuracy-versus-resource tradeoff rather than assuming it.
3. Manage the edge fleet
Version, update over the air, and roll back edge models, the edge AI discipline applied to the grid.
4. Coordinate edge and central
Split roles by latency need and synchronize local-to-central, so edge and central forecasting work together.
5. Monitor in the field
Monitor edge model performance in the field with drift detection, not just lab accuracy.
Logiciel's value add is helping utilities place forecasting models at the edge, optimize and fleet-manage them, and coordinate with central forecasting, so fast local grid decisions happen at the latency they require, resilient to connectivity loss.
Takeaway for High-Performing Teams: Focus on placement and fleet management. Grid forecasting at the edge meets the latency and connectivity needs of fast local decisions, applying edge AI discipline to the grid, while central forecasting handles the aggregate.
Signals You Are Forecasting at the Edge Correctly
How do you know the deployment is sound? Not in central forecast accuracy, but in local decision latency and fleet health. Below are the signals that distinguish edge forecasting from a centralized round trip.
Local decisions meet latency. Fast local grid decisions happen at the edge without a cloud round trip.
It works during connectivity loss. Edge forecasting continues when connectivity drops.
The fleet is managed. The team versions, updates, and rolls back edge models.
Edge and central coordinate. Roles are split by latency need with synchronization.
Field performance is monitored. The team monitors edge models in the field with drift detection.
Adjacent Capabilities and Connected Work
This work does not exist in isolation. Edge grid forecasting depends on, and feeds into, several adjacent capabilities. Building one without thinking about the others is the most common scoping mistake.
In most utilities, edge forecasting shares infrastructure with the grid sensor and SCADA systems, the central forecasting and data platform, and the field operations process. It shares capacity with grid operations, data engineering, and field teams. And it shares leadership attention with whatever the next grid-modernization initiative is on the roadmap. Naming these adjacencies upfront helps the program scope realistically and helps leadership see the work as a portfolio rather than a one-off project.
The most common mistake in adjacent-capability scoping is treating each adjacency as someone else's problem. The edge device fleet management is your problem. The central coordination is your problem. The field monitoring is your problem. Pretending otherwise pushes work to teams that did not plan for it, and the work returns to you later as stale edge models or missed local decisions. Own the adjacencies you depend on; partner with the teams that own them; share the timeline.
Conclusion
Grid forecasting at the edge runs models close to the meter so fast local decisions happen with low latency and without depending on the cloud, applying edge AI discipline to the grid. The discipline that delivers it is the same discipline behind any edge deployment: place by need, optimize, manage the fleet, and monitor the field.
Key Takeaways:
- Fast local grid decisions need forecasting at the edge, not central
- It is edge AI for the grid: placement, optimization, fleet management
- Coordinate edge and central forecasting and monitor the field
Forecasting at the edge well requires placement, fleet, and monitoring discipline. When done correctly, it produces:
- Local grid decisions at the latency they require
- Forecasting resilient to connectivity loss
- Models close to where grid conditions change fast
- A managed, monitored edge fleet
An AI Product Development Playbook for Engineering Teams
How AI-first startups build MVPs faster, ship quicker, & impress investors without big teams.
What Logiciel Does Here
If your grid forecasting is centralized and cannot meet local decision latency, place models at the edge, optimize and fleet-manage them, and coordinate with central forecasting.
Learn More Here:
- Edge AI Implementation: Architecture Patterns for Real-time Inference
- AI for Energy Operations: From Anomaly Detection to Dispatch
- Data Pipelines for Sensor-Heavy Energy Workloads
At Logiciel Solutions, we work with utilities on edge grid forecasting, model placement, and edge fleet management. Our reference patterns come from production grid and edge deployments.
Explore how to bring grid forecasting to the edge, close to the meter.
Frequently Asked Questions
What is grid forecasting at the edge?
Running forecasting models close to the meter, at substations and field devices, so local forecasts and decisions happen with low latency and without depending on a round trip to the cloud, while the central system handles slower, aggregate forecasting.
Why move grid forecasting to the edge?
Because the modern grid needs fast, local decisions, distributed energy resources swing supply and demand near the meter in seconds, and a cloud round trip is too slow and depends on connectivity field locations may not have. Edge placement meets the latency and resilience local decisions require.
Isn't more central compute enough?
No. The problem is the latency of a round trip and dependence on connectivity, not central compute capacity. More compute does not shorten the round trip or restore lost connectivity. Fast local decisions need models running close to the meter.
How is edge grid forecasting managed?
As an edge AI fleet: models optimized for edge hardware, versioned, updated over the air, and rolled back when needed, with field performance monitored. It applies the same edge AI discipline, placement, optimization, fleet management, to the grid, coordinated with central forecasting.
What is the biggest mistake in grid forecasting?
Keeping forecasting centralized for decisions that need to be fast and local, or deploying edge models with no fleet management. Place models by latency and connectivity need, manage the edge fleet, coordinate with central, and monitor field performance.

