

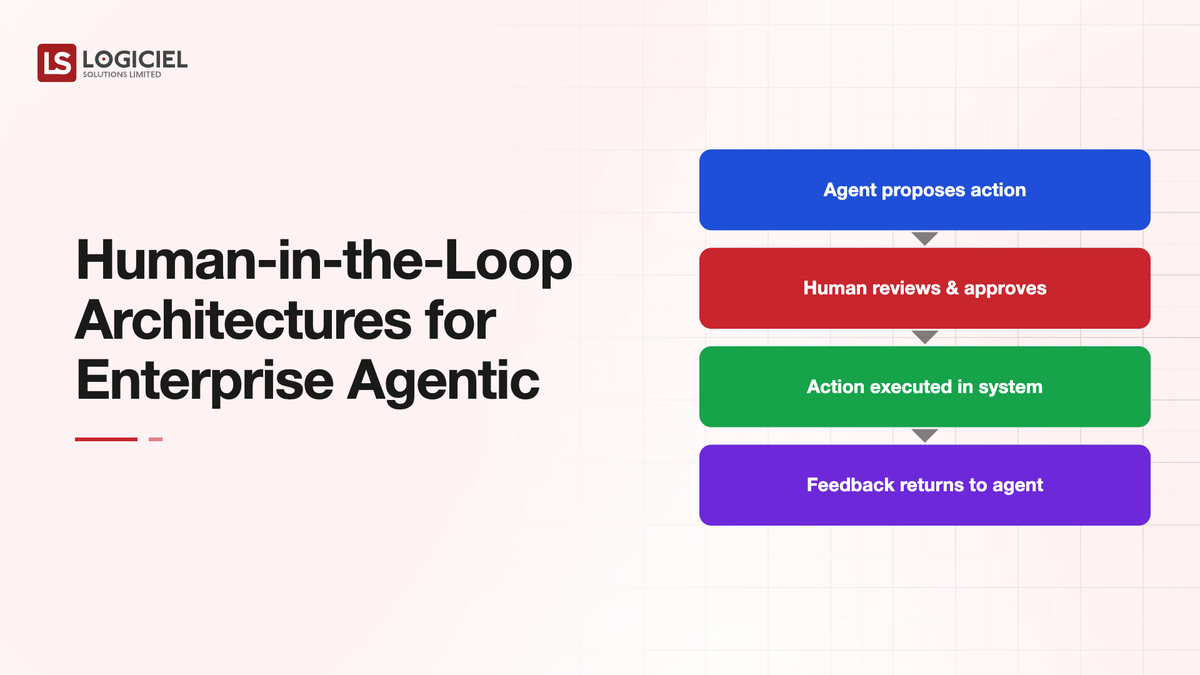
Beyond the Approval Button
Human-in-the-loop, in too many production systems, is implemented as an approval button that a human clicks without reading what they are approving. The implementation satisfies the letter of governance requirements and provides none of the value. EU AI Act enforcement starting August 2026 makes this kind of nominal HITL increasingly indefensible. Article 14 specifically requires that human oversight be meaningful rather than ceremonial (European Commission, EU AI Act timeline).
Beyond regulatory pressure, HITL also affects user experience and business outcomes. Production agentic systems with weak HITL produce more bad outputs that reach users. Production agentic systems with overweight HITL produce slow, friction-heavy workflows that users circumvent. The architecture matters.
Three HITL architecture patterns now dominate production enterprise agentic AI. Each one fits different workload characteristics. Picking the right pattern is the difference between meaningful oversight and either-or extremes that produce poor outcomes.
The Three Patterns
Production HITL architectures cluster into three patterns. Each one places the human at a different point in the workflow and produces different latency, throughput, and quality characteristics.
The first pattern is checkpoint HITL. The agent works autonomously through defined steps and pauses for human review at specific checkpoints. The human reviews the agent's progress, approves or redirects, and the agent continues. The pattern fits multi-step workflows where individual steps are low-risk and the cumulative trajectory needs oversight. Document workflows, research tasks, complex investigations.
The second pattern is escalation HITL. The agent works autonomously and only involves humans when it detects uncertainty or hits a defined escalation trigger. Most work flows through without human involvement. The escalation cases get full human attention. The pattern fits high-volume workflows where the majority of work is straightforward and a minority needs judgment. Customer support, triage, content moderation.
The third pattern is shadow HITL. The agent produces output that humans review or use as input but do not necessarily approve. The human's involvement is consumption, not gating. The pattern fits workflows where the agent informs human decisions rather than replacing them. Sales analysis, research summaries, executive briefings.
A workload assigned to the wrong pattern produces predictable friction. Workloads assigned correctly find the human involvement falls into a sustainable rhythm rather than creating bottleneck.
What Each Pattern Costs in Practice
The patterns have different operational costs that influence which fits a given workload.
Checkpoint HITL is moderately expensive because every workflow pays human-time cost at each checkpoint. The total human time is predictable: roughly volume times checkpoints times time-per-checkpoint. For workloads with high volume and many checkpoints, the human staffing cost becomes the dominant cost line.
Escalation HITL is variable cost because the human time scales with escalation rate. The cost discipline is keeping the escalation rate calibrated. Too low (under 5-10 percent) and the system is operating without meaningful oversight. Too high (over 30-40 percent) and the cost dominates and the agent provides little leverage.
Shadow HITL has near-zero direct human cost because the human time is incurred as part of normal work the human would do anyway. The agent's output is an input to the human's existing process. The cost is in the human's mental load of evaluating the agent's input alongside other inputs.
The patterns produce different per-unit economics. The choice often comes down to which cost line the organization can absorb most easily.
What Makes HITL Meaningful
EU AI Act Article 14 distinguishes meaningful oversight from nominal oversight. The distinction matters because meaningful oversight is harder to design than checking a box.
Meaningful oversight requires the human have sufficient context to evaluate the AI's output. A reviewer who sees only the AI's recommendation cannot meaningfully evaluate it. A reviewer who sees the recommendation plus the underlying reasoning, evidence, and confidence indicators can.
Meaningful oversight requires the human have authority to override the AI. A reviewer whose disagreement carries no weight is performing theater. A reviewer whose disagreement actually changes the outcome is performing oversight.
Meaningful oversight requires the human have time to actually review. A reviewer processing 200 cases per hour is not meaningfully reviewing each one. A reviewer with bounded throughput that allows real attention is.
Meaningful oversight requires the human have appropriate expertise. A reviewer who lacks the domain knowledge to evaluate the AI's output cannot meaningfully oversee it. The skills and authority have to match the work.
These four properties are testable. Auditors and regulators have learned to test for them. Architectures that produce nominal HITL pass surface-level inspection and fail meaningful inspection.
The Workflow Design That Distinguishes
Beyond the pattern selection, the workflow design within the pattern affects whether HITL works.
Context presentation matters. The interface that shows the human what the AI did, why, and how confidently is what makes the human's review meaningful. Bad interfaces produce bad oversight regardless of how the underlying architecture is structured.
Decision support matters. The interface that lets the human compare to similar past cases, see typical patterns, or check against policy rules amplifies the human's ability to oversee. Bare approval buttons do less than interfaces that support the human's reasoning.
Feedback loops matter. The signals that flow from human decisions back into the AI system (preference data, error correction, edge case capture) determine whether the system improves over time. Without feedback loops, HITL is a wall the AI cannot learn from.
Workflow design within the pattern often matters more than which pattern was chosen. A poorly designed escalation HITL produces worse outcomes than a well-designed checkpoint HITL.
What Logiciel Does Here
Logiciel works with engineering and operations teams designing or improving HITL architectures for production agentic systems. The work is typically structured around pattern selection followed by workflow design with explicit attention to the meaningful-oversight criteria.
The HITL Architectures framework covers the Feature HITL design that complements the three-pattern model. The Guardrails for Agentic AI framework covers the four-layer guardrails that operate alongside HITL.
A 30-minute working session is enough to assess your current HITL pattern selection and workflow design.
Frequently Asked Questions
How do I choose between the three patterns?
Workload characteristics drive the choice. Multi-step workflows with cumulative risk fit checkpoint. High-volume workflows with judgment minority fit escalation. Inform-not-decide workflows fit shadow. A workflow can run different patterns for different parts of the system.
How do I calibrate the escalation rate in escalation HITL?
Start conservative (high escalation rate) and reduce as confidence builds. The rate should reflect actual uncertainty, not target throughput. If the rate has to be artificially suppressed to hit throughput targets, the pattern fit is wrong.
How do I prevent reviewer fatigue in checkpoint HITL?
Limit per-reviewer volume. Vary the work assigned. Build interfaces that surface decision-relevant information efficiently. Reviewer fatigue is the leading cause of HITL degradation and is preventable through workflow design.
What is the right reviewer skill profile?
Domain expertise sufficient to evaluate the AI's output. The skill profile depends on the workflow. Medical workflows need clinical reviewers; legal workflows need legal reviewers; financial workflows need financial reviewers. Generic reviewers produce generic oversight.
How does HITL interact with model improvement?
HITL is one of the strongest signals for model improvement when the feedback loop is designed for it. The reviewer's decisions become training data, evaluation data, or prompt refinement input. HITL without feedback loop misses this benefit. Sources: - European Commission, EU AI Act timeline - NIST, "AI Risk Management Framework 1.1," 2024

