

Most RAG projects spend their effort on the wrong half. Teams obsess over the language model and treat retrieval as a checkbox, then wonder why the system confidently answers from the wrong context. The practical roadmap to RAG inverts that: build retrieval quality first, because retrieval is the ceiling on everything the model can do. A great model fed bad context produces great-sounding wrong answers. Get retrieval right and the rest follows.
Hidden PHI Exposure Risks in Healthcare AI
Why 90% of healthcare organizations are unknowingly exposing patient data through AI tools.
RAG (retrieval-augmented generation) grounds a language model in your own data by retrieving relevant content and supplying it as context. A practical roadmap sequences the work by what actually determines success: a real grounding problem, high-quality retrieval, proven grounding on a real corpus, then scale and production hardening. This roadmap walks that sequence and the traps at each step.
What RAG Architecture Is
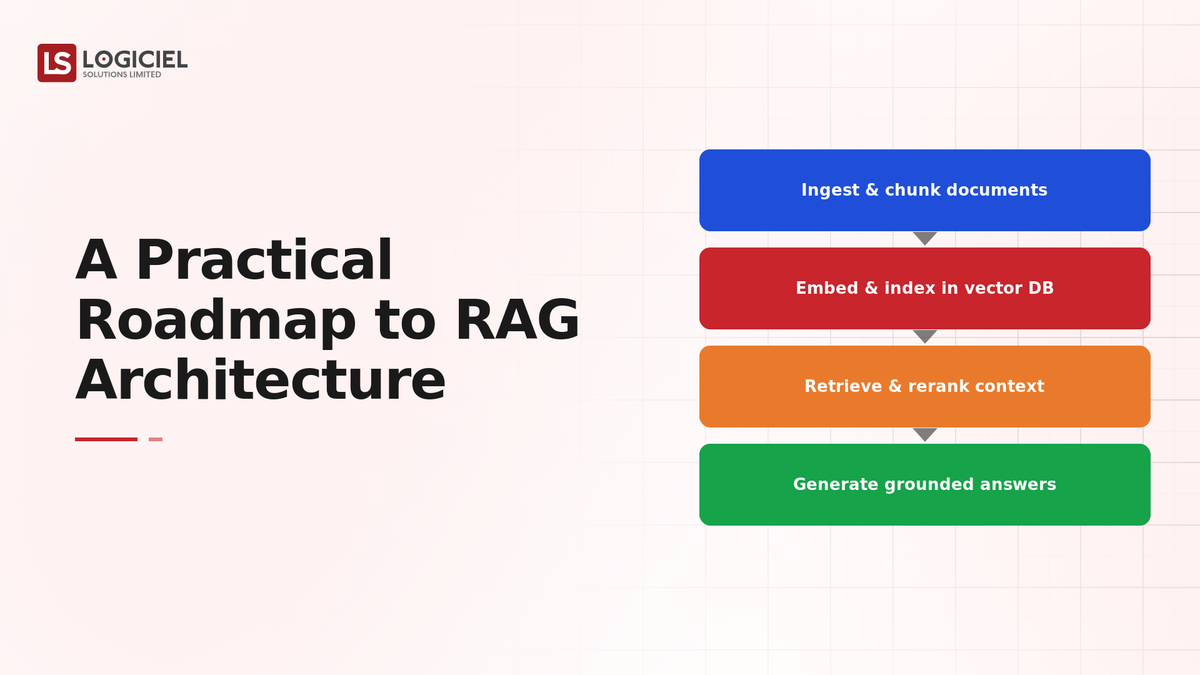
RAG works in two steps: retrieve the most relevant pieces of your data for a query (usually via embeddings and a vector store), then supply them to the model as context to answer from. The model grounds its answer in what retrieval returns. The critical property: the system can only ground in what retrieval surfaces, so retrieval quality determines the ceiling on answer quality. RAG is a grounding pattern, and grounding is a retrieval problem first.
The Roadmap
- Confirm RAG fits the problem. RAG is for grounding in a corpus of documents or data. If the problem is reasoning-heavy or real-time computation, RAG is the wrong tool. Confirm fit before building.
- Build retrieval quality first. Invest in chunking, embeddings, and retrieval tuning so the right context is surfaced for real queries. This is the ceiling; everything else depends on it.
- Prove grounding on a real corpus. Test on your actual data and real questions, measuring whether answers are correctly grounded, not whether the demo looks good. Fix retrieval where answers go wrong.
- Add the generation layer deliberately. With good retrieval, tune how retrieved context is supplied to the model and how answers cite sources. The model is the second-order concern.
- Harden for production. Handle latency, cost per query, context limits, and the case where retrieval finds nothing useful (so the model says "I don't know" instead of inventing).
- Monitor and maintain. Retrieval quality degrades as the corpus grows and changes. Monitor grounding quality and keep the index current.
Common Misconception
The misconception that produces confident wrong answers: RAG quality is mostly about the language model.
The model matters, but retrieval is the ceiling. The system can only ground in what retrieval returns, so if retrieval surfaces the wrong or incomplete context, even the best model produces confident wrong answers. Teams that pour effort into the model and treat retrieval as a checkbox build RAG systems that sound great and answer wrong. Retrieval quality, not model choice, is where RAG succeeds or fails.
Key Takeaway: In RAG, retrieval is the ceiling on answer quality. Build retrieval first and prove grounding on a real corpus, because a great model fed bad context still answers wrong.
Where the Roadmap Goes Right
- RAG confirmed as a fit for a corpus-grounding problem
- Retrieval quality built and proven on real data first
- Production hardening for latency, cost, and "no good context" cases
Where It Goes Wrong
- Obsessing over the model and treating retrieval as a checkbox
- Demoing on easy queries instead of proving grounding on real ones
- No handling for when retrieval finds nothing useful
Key Takeaway: RAG succeeds when retrieval quality is built first and grounding is proven on real data; it disappoints when effort goes to the model and retrieval is neglected.
What High-Performing Teams Do Differently
- Confirm RAG fits the problem before building.
- Invest in retrieval quality as the ceiling.
- Prove grounding on a real corpus and real questions.
- Handle the "no good context" case so the model does not invent.
- Monitor grounding quality as the corpus changes.
Logiciel's value add is helping teams build RAG the right way, confirming fit, building retrieval quality first, proving grounding on real data, and hardening for production, so the system answers from the right context instead of confidently from the wrong one.
Takeaway for High-Performing Teams: Sequence RAG by what determines success: fit, then retrieval quality, then proven grounding, then the model, then production. Retrieval is the ceiling, so build it first, and a great model will not save bad retrieval.
Adjacent Capabilities and Connected Work
RAG shares infrastructure with the document and data pipeline, the vector store and embedding stack, and the model serving layer, and shares team capacity with applied ML, data engineering, and product. The common scoping mistake is treating each adjacency as someone else's problem: the data pipeline feeding the index is your problem, the retrieval quality is your problem, the latency and cost are your problem. Pretending otherwise returns later as a RAG system grounding in the wrong context. Own the adjacencies, partner with the teams that own them, share the timeline.
Conclusion
A practical roadmap to RAG architecture sequences by what determines success: confirm RAG fits a corpus-grounding problem, build retrieval quality first, prove grounding on a real corpus, add the generation layer deliberately, harden for production, and monitor as the corpus changes. Retrieval is the ceiling, so the roadmap front-loads it. A great model fed bad context produces great-sounding wrong answers, which is the failure this sequence avoids.
Key Takeaways:
- RAG is a grounding pattern, and retrieval is the ceiling on quality
- Build retrieval first and prove grounding on a real corpus
- Harden for latency, cost, and the "no good context" case
Why Prior Authorization AI Still Fails
What the 16x denial rate finding means for engineering teams building PA automation.
What Logiciel Does Here
If your RAG system answers confidently from the wrong context, fix the sequence: build retrieval quality first and prove grounding on your real corpus before tuning the model.
Learn More Here:
- RAG Architecture: Concepts, Benefits, and Trade-offs
- Embeddings at Scale: Building and Maintaining a Vector Store
- AI Model Monitoring in Production: Drift, Decay, and What to Do About It
At Logiciel Solutions, we work with teams on RAG architecture, retrieval quality, grounding evaluation, and production hardening. Our reference patterns come from production RAG systems.
Explore a practical roadmap to RAG architecture.
Frequently Asked Questions
What is RAG architecture?
Retrieval-augmented generation: a pattern that grounds a language model in your own data by retrieving the most relevant content for a query (usually via embeddings and a vector store) and supplying it to the model as context. The model answers from what retrieval returns, so the system grounds its answers in your corpus rather than only the model's training.
Why build retrieval quality first?
Because retrieval is the ceiling: the system can only ground in what retrieval surfaces, so if retrieval returns the wrong or incomplete context, even the best model produces confident wrong answers. Investing in chunking, embeddings, and retrieval tuning first is what makes the whole system answer correctly, which is why the roadmap front-loads it.
How do you prove a RAG system works?
By testing on your actual corpus and real questions, measuring whether answers are correctly grounded, not by whether a demo on easy queries looks good. Where answers go wrong, the fix is usually retrieval (wrong context surfaced), not the model. Proving grounding on real data is what separates a working system from an impressive demo.
When is RAG the wrong tool?
When the problem is not grounding in a corpus, reasoning-heavy tasks, real-time computation, or problems not about retrieving from documents or data. RAG fits corpus-grounding well; applied to other problems it is the wrong or over-engineered choice. Confirming fit before building avoids investing in a pattern the problem does not need.
What production concerns matter for RAG?
Latency and cost per query (retrieval plus generation add both), context-window limits (only so much retrieved content fits), keeping the index current as the corpus changes, and handling the case where retrieval finds nothing useful, so the model says it does not know rather than inventing an answer. Monitoring grounding quality over time matters too.

