

The Score That Stopped Meaning What It Did
A clinical data scientist at a large health system told me about a risk stratification model her team had deployed in 2022 for predicting hospitalization risk. The model had been validated rigorously before deployment. The discriminatory performance held over time. By mid-2024, clinicians were ignoring the scores because the scores no longer matched clinical intuition.
She investigated and found the issue. The model's discriminatory performance was still good. Patients who would be hospitalized had higher scores than patients who would not. The calibration had drifted. A patient with a score of 50 was being hospitalized at much higher rates than the 50 percent the score implied. Clinicians had noticed the mismatch and stopped trusting the absolute values even when the relative rankings remained useful.
She told me the experience taught her something the textbook treatment of risk stratification did not emphasize. Discriminatory performance is not the same as calibration. A model with good discrimination can have poor calibration. Clinical decisions often depend on absolute probability rather than relative ranking. Calibration matters as much as discrimination for risk stratification used in clinical workflows.
The pattern is common. Risk stratification models that work in development drift in production. The drift is sometimes in discrimination and sometimes in calibration. Both matter for clinical use. Both require ongoing monitoring.
Why Audit-Ready Beats Audit-Survived Every Time
Inside a 120-day remediation that turned three material findings into zero at follow-up.
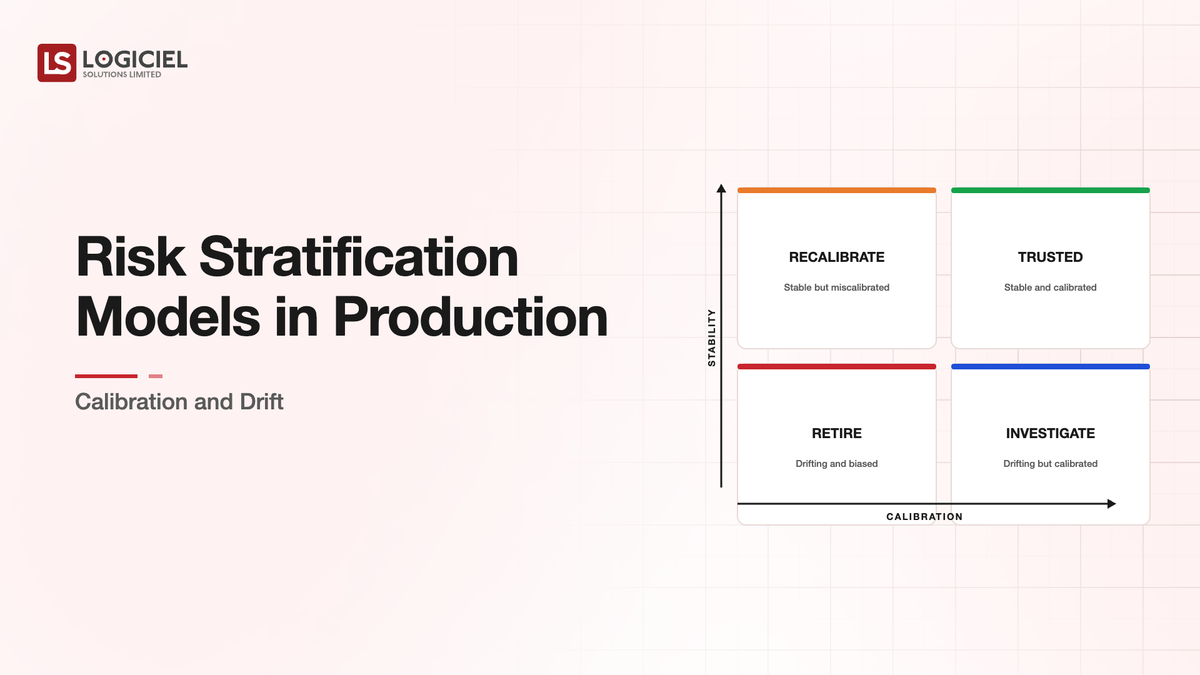
Three Failure Modes That Recur
Three failure modes for production risk stratification models recur across deployments.
The first failure mode is calibration drift while discrimination holds. The model's ranking ability stays intact but the absolute probabilities become inaccurate. Patients with score X get outcomes at rates different from what the score predicts.
The cause is usually a shift in the underlying population. New treatments change outcome rates. Demographic shifts in the served population change baselines. Care pathway changes affect outcome probabilities. The model's relative ranking still reflects risk; the absolute probabilities reflect the population the model was trained on rather than the current population.
The remediation is recalibration. The model's outputs get mapped to current outcome rates through Platt scaling, isotonic regression, or similar methods. The recalibration runs continuously rather than as one-time fix.
The second failure mode is discrimination degradation in specific subgroups. The model performs well overall but produces poor performance in specific patient populations. The aggregate metric looks healthy. The subgroup-specific reality is worse.
The cause is usually changing population characteristics. The training data may have under-represented specific subgroups. As the deployment expands to broader populations, the under-representation produces lower performance for the under-represented groups.
The remediation requires explicit subgroup analysis. The model's performance gets measured across patient subgroups (age, sex, race, ethnicity, comorbidity, insurance status, other relevant categories). Subgroups with weak performance get explicit attention through additional training data, model refinement, or subgroup-specific calibration.
The third failure mode is concept drift where outcomes themselves change. The model predicts hospitalization. The criteria for hospitalization change in the served population. The model's predictions no longer correspond to current clinical reality.
The cause can be external (changing reimbursement, evolving clinical guidelines) or internal (organizational policy changes affecting admission patterns). The model has not changed; the world it predicts has.
The remediation is more substantial. The model may need retraining on updated data. The clinical use may need re-evaluation against new outcomes. The model's purpose may need to evolve along with the clinical reality.
What Production Monitoring Has to Catch
Production monitoring for risk stratification models has to catch all three failure modes. The monitoring infrastructure has specific characteristics.
Continuous discrimination measurement against actual outcomes. The model's predictions get compared to observed outcomes on a rolling basis. AUC, sensitivity, specificity, and similar metrics get tracked. Trends matter more than point-in-time values.
Continuous calibration measurement at multiple probability ranges. The model's predicted probabilities get compared to observed outcome rates within score bands. Calibration plots get updated regularly. Drift in calibration becomes visible early.
Subgroup performance monitoring. The metrics above run separately for each meaningful subgroup. Performance degradation in any subgroup gets surfaced.
Drift detection on input distributions. The patient characteristics flowing into the model get monitored for shifts. Significant shifts trigger calibration review even before outcome metrics change.
Most production deployments have some discrimination monitoring. Fewer have continuous calibration monitoring. Fewer still have subgroup-specific monitoring. The gaps produce the failure patterns described above.
The Practices That Maintain Clinical Trust
Beyond technical monitoring, three practices maintain clinical trust in risk stratification models.
The first practice is transparent communication of model performance to clinical users. The clinicians who use the scores know how the model is performing. Performance changes get communicated. Calibration adjustments get explained. The transparency builds trust rather than undermining it.
The second practice is explicit clinical workflow integration. The model's outputs feed clinical decisions in defined ways. The integration accounts for the model's strengths and limitations. The clinician's role remains central; the model supports rather than substitutes for clinical judgment.
The third practice is responsive iteration based on clinical feedback. Clinical users surface concerns. The model team investigates. Issues that prove valid produce model updates. Issues that prove unfounded produce communication about why the model is performing as designed. The loop closes.
Models without these practices produce technical performance that does not translate to clinical use. Models with these practices produce sustained clinical impact.
What Goes Wrong With Risk Stratification Deployments
Three patterns of deployment failure are common.
The first pattern is treating model deployment as the end rather than the beginning. The model gets validated, deployed, and considered complete. The post-deployment monitoring is light. The drift accumulates. Clinical trust erodes.
The second pattern is over-investing in initial model development relative to deployment infrastructure. The team produces a sophisticated model with strong development performance. The infrastructure to monitor it in production is weak. The deployment looks good initially and degrades over time.
The third pattern is treating monitoring as a separate function from model development. The team that built the model does not see the production performance. The team that monitors the model does not have authority to make changes. The feedback loop is broken.
Each pattern is preventable through deliberate program design. Monitoring as continuous operation. Investment balance between development and deployment. Integrated team ownership across model lifecycle.
What This Costs
Operating risk stratification models at production grade with appropriate monitoring typically requires one dedicated data scientist or ML engineer per several models, plus shared infrastructure that supports monitoring across the portfolio.
Tooling investment includes model monitoring platforms, calibration analysis tools, subgroup performance dashboards, and integration with clinical workflows. The annual cost depends on portfolio size; serious capability for multiple models typically lands in the $500K-$2M range.
The alternative cost is the cost of clinical trust erosion. Models that lose clinical trust get ignored or removed. The development investment becomes sunk cost. Subsequent model deployments face skepticism.
Why ML Pilots Pass Review Then Die in Production
Inside an 8-month rebuild that turned three failed pilots into a 9:1 ROI model.
What Logiciel Does Here
Logiciel works with healthcare technology and clinical data science teams operating risk stratification models or designing new deployments. The work is typically structured around monitoring architecture assessment and operational practice maturity.
The AI Model Reliability in Clinical Decision Support framework covers the broader clinical AI reliability discipline. The AI Model Monitoring: Drift, Decay, and Response framework covers the cross-industry drift patterns that apply to clinical models too.
A 30-minute working session is enough to assess your current model monitoring against production-grade patterns.
Frequently Asked Questions
How often should I recalibrate?
Continuously where possible. For models where continuous recalibration is not feasible, quarterly review with calibration adjustments as needed. The right cadence depends on how quickly the underlying population changes.
What about model fairness across subgroups?
Subgroup performance monitoring is part of fairness assurance. The monitoring detects performance disparities. Remediation requires explicit investment. Organizations that monitor without remediating have detection without action; organizations that remediate based on detection produce better outcomes.
How does this work for proprietary vendor models?
Through vendor cooperation on monitoring data. Some vendors provide monitoring infrastructure. Others require customer-built monitoring against vendor-provided outputs. The vendor relationship has to support the monitoring requirements.
What about generative AI for risk stratification?
Emerging applications use LLM-based approaches for risk stratification or risk explanation. The fundamental monitoring requirements apply. Calibration and discrimination still matter. The technology is different; the discipline is similar.
How do I handle model retirement?
Through structured deprecation. Models that no longer perform adequately get retired with explicit communication to clinical users. Replacement models go through validation. The transition has to be managed rather than allowed to drift. Sources: - JAMA Network, "Algorithmic Stewardship in Healthcare," 2024 - FDA, AI/ML SaMD Action Plan, 2024

