For an SRE lead, a CI/CD pipeline is not just a delivery convenience; it is a reliability tool, the place where you build in the gates, safety, and rollback that keep bad changes from reaching production and let good ones ship fast. Most pipeline design treats CI/CD as a way to deploy faster. An SRE lead designs it as a way to deploy faster and more safely, because the pipeline is the last line of defense between a change and an incident. This introduction covers designing CI/CD pipelines from a reliability perspective.
Healthcare AI That Stays Accurate as Data Changes
Why clinical AI accuracy degrades when code sets update, how ontology mapping breaks across EHR vendors, and the canonical data layer.
A CI/CD pipeline automates the path from code commit to production: build, test, deploy. CI/CD pipeline design is the deliberate engineering of that path, including the quality gates, safety mechanisms, and rollback. For an SRE lead, designing it well means the pipeline catches bad changes, deploys safely, and recovers fast, making delivery both quick and reliable.
What CI/CD Pipeline Design Is
CI/CD pipeline design is the engineering of how code goes from commit to production: continuous integration (building and testing changes automatically) and continuous delivery or deployment (releasing them through automated, repeatable steps). Designing it includes the quality gates (tests, checks that block bad changes), the deployment strategy (staged rollout, canaries), the safety (verification, automatic rollback), and the speed (fast feedback). For an SRE lead, the pipeline is a reliability mechanism: it is where you stop bad changes and recover from them, not just where you deploy.
How an SRE Lead Should Approach It
- Treat the pipeline as a reliability tool. Design it to catch bad changes and recover from them, not just to deploy fast. The pipeline is the last line of defense before production.
- Build meaningful quality gates. Put automated tests and checks in the pipeline that actually catch the problems that cause incidents, not just any tests. Gates that do not catch real issues are theater.
- Use safe deployment strategies. Stage rollouts (canary, blue-green) so a bad change affects a small blast radius first, not all of production at once.
- Make rollback fast and automatic. Design the pipeline to detect a bad deploy and roll back quickly, since fast recovery is as important as prevention.
- Keep feedback fast. Slow pipelines get bypassed. Fast feedback means the pipeline is used, and reliability gates are not skipped under pressure.
- Tie it to SLOs and error budgets. Use the pipeline to enforce reliability practices, e.g., slowing or gating deploys when the error budget is spent.
Common Misconception
The misconception that ships incidents: a CI/CD pipeline is about deploying faster.
Speed is half of it. For an SRE lead, the pipeline is equally about deploying safely, the gates that catch bad changes, the staged rollout that bounds blast radius, and the rollback that recovers fast. A pipeline designed only for speed ships bad changes faster, causing incidents. Designing CI/CD purely for velocity ignores that the pipeline is the reliability mechanism between a change and production, and that safe, fast delivery is the actual goal.
Key Takeaway: For an SRE lead, CI/CD pipeline design is a reliability tool, gates, safe rollout, fast rollback, not just a way to deploy faster. The pipeline is the last line of defense before production.
Where CI/CD Pipeline Design Goes Right
- The pipeline designed as a reliability tool, not just for speed
- Meaningful quality gates and safe, staged deployment
- Fast, automatic rollback, with fast feedback so the pipeline is used
Where It Goes Wrong
- Designing the pipeline only for deployment speed
- Quality gates that do not catch real problems
- No staged rollout or rollback, so bad changes hit all of production
Key Takeaway: An SRE lead designs the CI/CD pipeline to deploy fast and safely, with gates, staged rollout, and rollback; designing only for speed ships incidents faster.
What High-Performing SRE Leads Do Differently
- Treat the pipeline as a reliability mechanism.
- Build quality gates that catch incident-causing problems.
- Use staged rollout to bound blast radius.
- Make rollback fast and automatic.
- Keep feedback fast and tie deploys to SLOs and error budgets.

Logiciel's value add is helping SRE leads design CI/CD pipelines as reliability tools, meaningful gates, safe staged rollout, fast rollback, and fast feedback, so delivery is both quick and reliable rather than fast but incident-prone.
Takeaway for High-Performing Teams: Design the CI/CD pipeline as a reliability tool: gates that catch bad changes, staged rollout that bounds blast radius, and fast rollback that recovers, with fast feedback so it is used. For an SRE lead, the pipeline is the last line of defense, and safe, fast delivery is the goal.
Adjacent Capabilities and Connected Work
CI/CD pipeline design shares infrastructure with the version control and build systems, the testing infrastructure, and the deployment targets and observability, and shares team capacity with platform engineering, the application teams, and SRE. The common scoping mistake is treating each adjacency as someone else's problem: the test quality is your problem, the rollback safety is your problem, the SLO-gated deploys are your problem. Pretending otherwise returns later as a pipeline that shipped an incident. Own the adjacencies, partner with the teams that own them, share the timeline.
Conclusion
For an SRE lead, CI/CD pipeline design is the engineering of a reliability tool, the path from commit to production with the quality gates, staged rollout, and fast rollback that keep bad changes out and recover from them, not just a way to deploy faster. The pipeline is the last line of defense before production. Designed for both speed and safety, with meaningful gates and fast rollback, it makes delivery quick and reliable, which is the actual goal of CI/CD from a reliability perspective.
Key Takeaways:
- For an SRE lead, the CI/CD pipeline is a reliability tool, not just a deployment one
- Build meaningful gates, staged rollout, and fast rollback
- Keep feedback fast and tie deploys to SLOs and error budgets
Ambient Clinical Documentation Needs Better Infrastructure
The three engineering challenges that determine whether ambient AI documentation ships into a health system or fails security review.
What Logiciel Does Here
If your CI/CD pipeline is designed only for speed, redesign it as a reliability tool: meaningful gates, staged rollout, fast rollback, and fast feedback, so delivery is quick and safe.
Learn More Here:
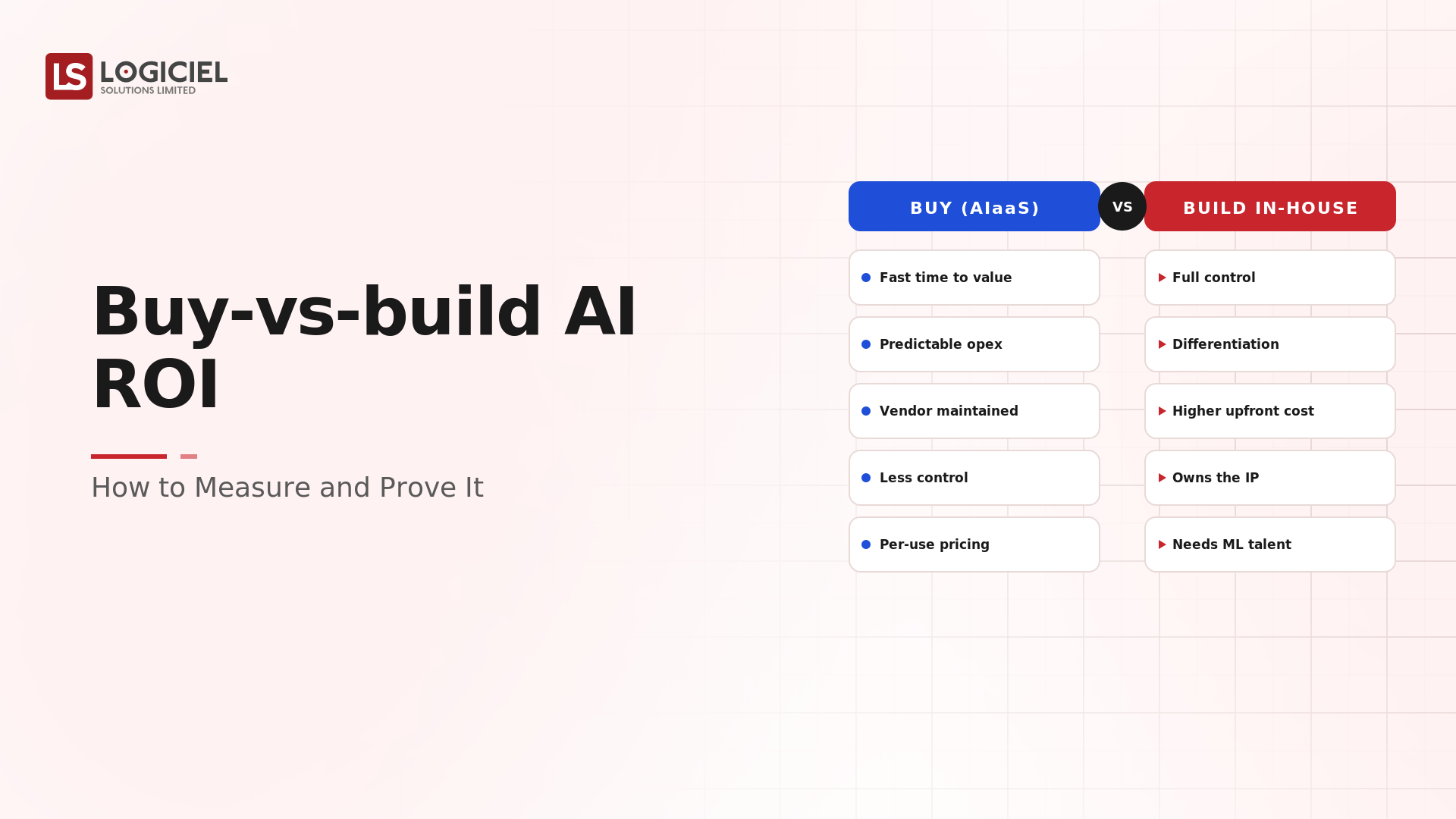
- CI/CD Pipeline Design ROI: How to Measure and Prove It
- CI/CD Pipeline Design vs. the Status Quo: A Decision Guide for VP Engineering
- Progressive Delivery: Canaries, Blue-Green, and Feature Flags
At Logiciel Solutions, we work with SRE leads on CI/CD pipeline design, reliability gates, staged rollout, and fast rollback. Our reference patterns come from production delivery pipelines.
Explore an SRE lead's introduction to CI/CD pipeline design.
Frequently Asked Questions
What is CI/CD pipeline design?
The deliberate engineering of the path from code commit to production: continuous integration (automated build and test) and continuous delivery or deployment (automated, repeatable release), including the quality gates, deployment strategy, safety mechanisms, and rollback. For an SRE lead, it is the design of a reliability tool, where bad changes are caught and recovered from, as well as a delivery one.
Why is the pipeline a reliability tool, not just a delivery one?
Because it is the last line of defense between a change and production. The pipeline's gates catch bad changes before they deploy, its staged rollout bounds the blast radius of a bad change, and its rollback recovers fast. Designed only for speed, the pipeline ships bad changes faster, causing incidents. For an SRE lead, it is equally a reliability mechanism.
What makes a quality gate meaningful?
That it actually catches the problems that cause incidents, not just that tests run. Gates that pass everything, or test the wrong things, are theater that gives false confidence. Meaningful gates are the automated tests and checks that catch the real issues, broken functionality, regressions, misconfigurations, that would cause an incident if they reached production.
Why does staged rollout matter for reliability?
Because deploying a change to all of production at once means a bad change affects everyone immediately. Staged rollout (canary, blue-green) releases the change to a small portion first, so a bad change has a bounded blast radius and can be caught and rolled back before it affects all users. It is a core reliability mechanism in the pipeline.
How does the pipeline relate to SLOs and error budgets?
The pipeline can enforce reliability practices tied to SLOs and error budgets, for example, slowing or gating deploys when the error budget is spent, so the team stabilizes before shipping more change. This makes the pipeline an enforcement point for the reliability-versus-velocity balance, integrating CI/CD with the SRE practices that govern it.