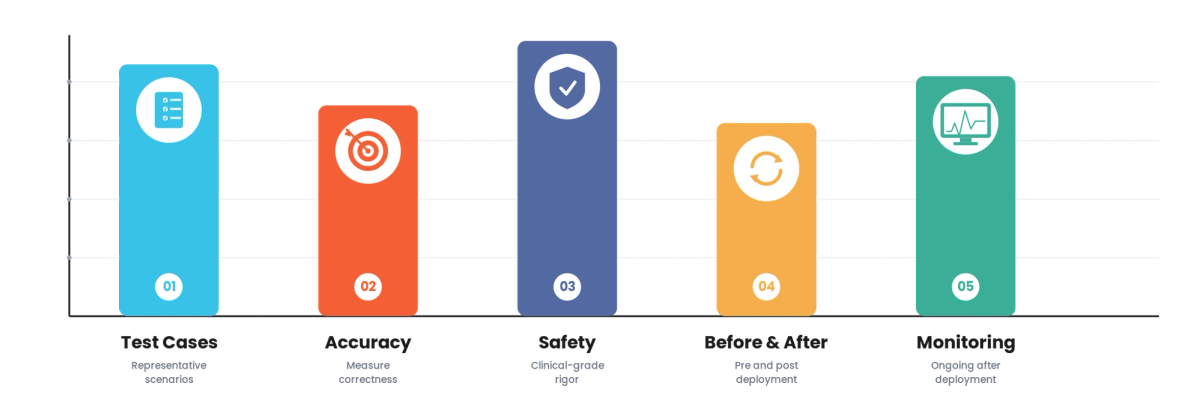
In 2026, healthcare has largely stopped accepting "it looked good in a few examples" as evidence that an LLM is safe to use, and started demanding real evaluation. That shift is the state of it. As LLMs moved toward clinical and patient-facing uses, the gap between a model that demos well and one that is safe became unacceptable, and ad hoc spot-checking gave way to systematic evaluation: tested against representative cases, measured for accuracy and safety, and monitored after deployment. The trend is LLM evaluation maturing toward something closer to clinical-grade rigor.
Real Estate Platform Ships Agentic AI in 10 Weeks
A time-to-value playbook for VPs of Product who need agents in production this quarter, not next year.
LLM evaluation and testing is the systematic measurement of whether an LLM is accurate, safe, and reliable enough for its use, before and after deployment. In healthcare, where an LLM error can affect care, evaluation has to be rigorous: representative test cases, accuracy and safety metrics, and ongoing monitoring. The 2026 trends are about closing the gap between impressive demos and evaluated, safe systems.
What LLM Evaluation and Testing Is
LLM evaluation measures whether a model performs well enough for its purpose: accuracy on representative cases, safety (not producing harmful or dangerous outputs), robustness (handling edge cases and adversarial inputs), and reliability over time. It is the LLM equivalent of testing, but harder, because outputs are open-ended and "correct" is often nuanced. In healthcare, evaluation must also weigh clinical safety and the consequences of being wrong, which raises the bar well above general LLM evaluation.
The Trends Shaping It in 2026
- From spot checks to systematic evaluation. The core trend: healthcare is moving from "it looked good on a few examples" to testing against representative case sets with measured accuracy and safety, because anecdotes do not establish safety.
- Safety evaluation as central. Beyond accuracy, evaluating that the LLM does not produce harmful or dangerous outputs is becoming central, given clinical stakes.
- Evaluation before and after deployment. The trend is evaluating before deployment and continuously monitoring after, since LLM behavior drifts and edge cases emerge in production.
- Clinical involvement in evaluation. Increasingly, clinical experts are involved in defining what "good" and "safe" mean for healthcare LLM outputs, rather than leaving it to technical metrics alone.
Common Misconception
The misconception that lets unsafe LLMs through: if the LLM produces good answers in our testing, it is ready.
A handful of good answers in informal testing does not establish that an LLM is accurate and safe across the range of real inputs, including edge cases and adversarial ones. In healthcare, where being wrong can affect care, anecdotal evidence is dangerous. The 2026 standard is systematic evaluation, representative cases, measured accuracy and safety, ongoing monitoring, because impressive demo answers are not evidence of clinical-grade reliability.
Key Takeaway: In 2026, healthcare LLM evaluation is moving from spot checks to systematic, safety-centered evaluation before and after deployment. Good demo answers are not evidence an LLM is safe for care.
Where LLM Evaluation Goes Right
- Systematic testing against representative case sets, not anecdotes
- Safety evaluation central, with clinical experts involved
- Evaluation before deployment and continuous monitoring after
Where It Goes Wrong
- Treating good answers on a few examples as readiness
- Measuring accuracy but not safety
- Evaluating before deployment but not monitoring after
Key Takeaway: Healthcare gets value from LLM evaluation when it is systematic, safety-centered, and ongoing; anecdotal evaluation lets unsafe models through where the stakes are clinical.
What High-Performing Healthcare Teams Do Differently
- Evaluate against representative case sets, not anecdotes.
- Make safety evaluation central, not just accuracy.
- Involve clinical experts in defining good and safe.
- Evaluate before deployment and monitor continuously after.
- Match evaluation rigor to the clinical stakes of the use.
Logiciel's value add is helping healthcare teams build rigorous LLM evaluation, representative testing, safety evaluation, clinical involvement, and ongoing monitoring, so LLMs are demonstrably safe enough for their use rather than approved on impressive demos.
Takeaway for High-Performing Teams: In 2026, evaluate healthcare LLMs systematically, against representative cases, for accuracy and safety, with clinical input, before and after deployment. Demo answers are not evidence of clinical-grade reliability, and the stakes demand the rigor.
Adjacent Capabilities and Connected Work
LLM evaluation shares infrastructure with the model serving and monitoring stack, the test case and data sets, and the clinical governance process, and shares team capacity with applied ML, clinical experts, and quality. The common scoping mistake is treating each adjacency as someone else's problem: the test case construction is your problem, the safety evaluation is your problem, the post-deployment monitoring is your problem. Pretending otherwise returns later as an unsafe LLM output affecting care. Own the adjacencies, partner with the teams that own them, share the timeline.
Conclusion
The state of LLM evaluation and testing in healthcare for 2026 is a shift from ad hoc spot checks to systematic, safety-centered evaluation: representative test cases, measured accuracy and safety, clinical involvement, and monitoring before and after deployment. As LLMs move toward clinical and patient-facing uses, the gap between a model that demos well and one that is safe became unacceptable. The trend is evaluation maturing toward the rigor the clinical stakes demand.
Key Takeaways:
- Healthcare LLM evaluation is moving from spot checks to systematic rigor
- Safety evaluation, with clinical input, is becoming central alongside accuracy
- Evaluate before deployment and monitor continuously after
Agentic AI Launch in Just 10 Weeks
An AI governance playbook for Chief Risk Officers in regulated energy markets.
What Logiciel Does Here
If your healthcare LLM was approved on good demo answers, build real evaluation: representative test cases, measured accuracy and safety, clinical input, and ongoing monitoring.
Learn More Here:
- Building a Business Case for LLM Evaluation And Testing in Energy & Utilities
- A Practical Roadmap to Monitoring LLMs in Production
- Hallucination Mitigation: Concepts, Benefits, and Trade-offs
At Logiciel Solutions, we work with healthcare teams on LLM evaluation and testing, representative case sets, safety evaluation, and ongoing monitoring. Our reference patterns come from production healthcare LLM systems.
Explore the state of LLM evaluation and testing in healthcare for 2026.
Frequently Asked Questions
What is LLM evaluation and testing?
The systematic measurement of whether an LLM is accurate, safe, and reliable enough for its use, before and after deployment: accuracy on representative cases, safety (not producing harmful outputs), robustness on edge cases, and reliability over time. It is the LLM equivalent of testing, but harder because outputs are open-ended and "correct" is often nuanced.
What changed in healthcare for 2026?
A shift from accepting "it looked good on a few examples" to demanding systematic evaluation, as LLMs moved toward clinical and patient-facing uses. The gap between a model that demos well and one that is safe became unacceptable, so ad hoc spot-checking gave way to representative testing, measured accuracy and safety, clinical involvement, and ongoing monitoring.
Why isn't good performance on a few examples enough?
Because a handful of good answers does not establish accuracy and safety across the range of real inputs, including edge cases and adversarial ones. In healthcare, where being wrong can affect care, anecdotal evidence is dangerous. Systematic evaluation against representative cases, with measured safety, is what establishes that an LLM is reliable enough for clinical use.
Why is safety evaluation central in healthcare?
Because an LLM error in a clinical or patient-facing context can affect care, so evaluating that the model does not produce harmful or dangerous outputs matters as much as accuracy. Safety evaluation, increasingly with clinical experts defining what is safe, is central to healthcare LLM evaluation in a way it is not for low-stakes general uses.
Why evaluate after deployment, not just before?
Because LLM behavior drifts as inputs and usage change, and edge cases emerge in production that pre-deployment testing missed. Continuous monitoring after deployment catches degradation and new failure modes, so an LLM that was safe at launch stays safe in use. Evaluation before deployment plus ongoing monitoring is the 2026 standard for healthcare.