

There is an AI service in your organization whose traffic is spiky, quiet for stretches, then sudden surges, and its autoscaling policy is tuned to one extreme or the other. Tuned for cost, it scales too slowly and the spikes hit before capacity arrives, degrading latency. Tuned for capacity, it holds too much headroom and pays for peak even when traffic is quiet. The policy treats capacity and cost as a single setting when spiky AI traffic demands a policy that balances them, scaling fast for spikes without paying for peak continuously.
This is more than a tuning detail. It is an autoscaling policy that does not balance capacity and cost for spiky AI traffic.
Autoscaling policies for spiky AI traffic balance capacity and cost: scaling responsively enough that spikes are met within latency, while not holding peak capacity when traffic is quiet, through warmed capacity, scaling speed, and headroom tuned to the spikiness. AI traffic is spiky and inference scaling has lead time, so the policy must react fast enough for the spike without paying for the peak continuously.
However, many teams tune the policy to one extreme and discover it either misses spikes or pays for idle capacity.
If you are a platform or ML infrastructure leader, the intent of this article is:
- Define the capacity-versus-cost balance for spiky AI traffic
- Walk through scaling speed, warmed capacity, and headroom
- Lay out the policy spiky AI traffic needs
To do that, let's start with the basics.
Real Estate Platform Reduced Pipeline Costs 45%
A pipeline FinOps playbook for FinOps Leads who need cost reductions that survive next quarter.
What Is a Spiky-Traffic Autoscaling Policy? The Basic Definition
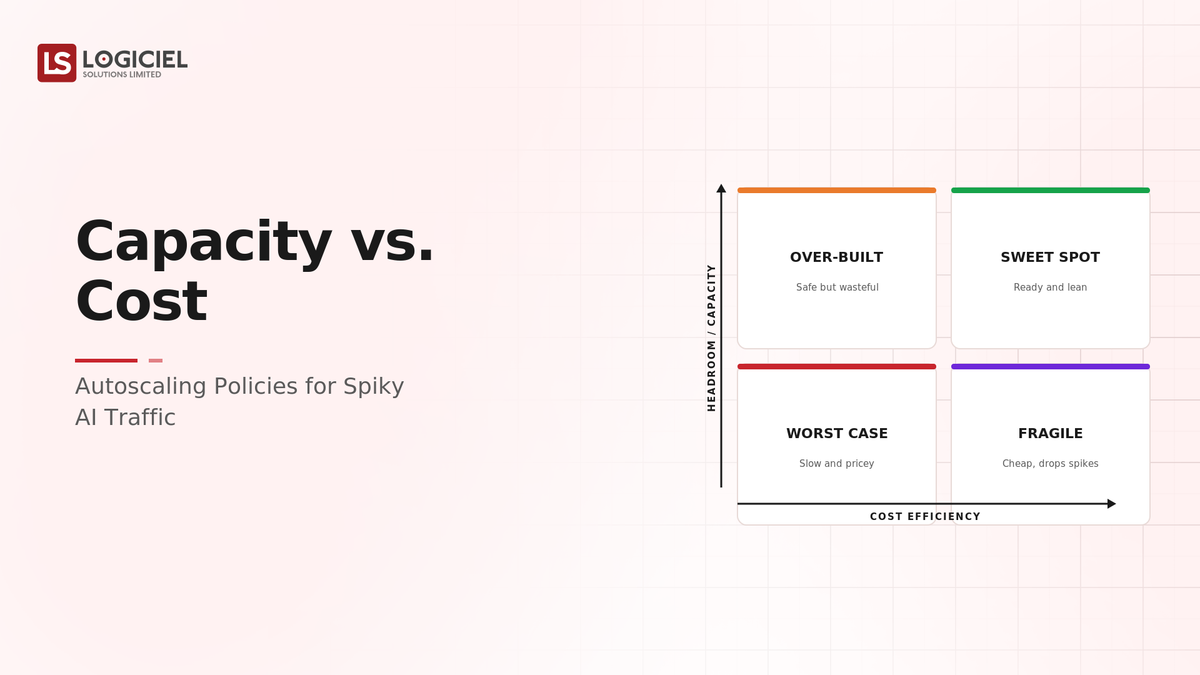
At a high level, a spiky-traffic autoscaling policy balances capacity and cost by scaling fast enough to meet spikes within latency, with tuned warmed capacity and headroom, while not holding peak capacity when traffic is quiet.
To compare:
If a cost-tuned policy is a kitchen with minimal staff that buckles at the dinner rush, and a capacity-tuned one is full staff all day paying for idle hours, a balanced policy is staff scaled to the rush with enough on hand to start fast. It meets the rush without paying for peak all day.
Why Is Balancing Capacity and Cost Necessary?
Issues that balancing addresses or resolves:
- Meeting spikes within latency
- Not paying for peak capacity continuously
- Balancing capacity and cost for spiky traffic
Resolved Issues by a Balanced Policy
- Scales fast enough for spikes
- Avoids holding peak capacity when quiet
- Balances capacity and cost
Core Components of a Spiky-Traffic Policy
- Scaling speed for spikes
- Warmed capacity to absorb lead time
- Headroom tuned to spikiness
- Cost-versus-latency balance
- Monitoring of spikes and scaling
Modern Autoscaling Tooling
- Predictive and reactive autoscaling
- Warmed pools and pre-provisioned capacity
- Scaling speed configuration
- Latency and cost monitoring
- Spike pattern analysis
These tools enable balancing; the discipline is tuning the policy to the spikiness, not one extreme.
Other Core Issues They Will Solve
- Keep latency met under spikes
- Keep cost proportional to traffic
- Handle spiky AI workloads efficiently
Importance of Balancing in 2026
Balancing capacity and cost matters more as AI traffic spikes and cost grows. Four reasons explain why it matters now.
1. AI traffic is spiky.
AI service traffic surges and quiets unpredictably. A policy tuned to one extreme misses spikes or wastes cost.
2. Inference scaling has lead time.
Scaling inference capacity takes time, so a spike can hit before capacity arrives unless the policy reacts fast or holds warmed capacity.
3. Both extremes are costly.
Cost-tuned misses spikes and degrades latency; capacity-tuned pays for idle peak. The balance avoids both.
4. Cost is scrutinized.
Paying for peak capacity continuously is scrutinized spend. The policy must keep cost proportional while meeting spikes.
Traditional vs. Balanced Policy
- Tuned to one extreme vs. balancing capacity and cost
- Misses spikes or wastes cost vs. meets spikes affordably
- Single setting vs. scaling speed, warmed capacity, headroom
- Cost or latency alone vs. both balanced
In summary: A spiky-traffic autoscaling policy balances capacity and cost, scaling fast for spikes with tuned warmed capacity and headroom, without paying for peak continuously.

Details About the Components of a Spiky-Traffic Policy: What Are You Tuning?
Let's go through each element.
1. Scaling Speed Layer
Reacting to spikes.
Speed decisions:
- Scaling responsive enough for spikes
- Reaction time versus spike onset
- Predictive scaling where patterns allow
2. Warmed Capacity Layer
Absorbing lead time.
Warmed decisions:
- Warmed capacity to absorb scaling lead time
- Pre-provisioned to start fast
- Tuned to spike onset
3. Headroom Layer
Buffer for spikes.
Headroom decisions:
- Headroom tuned to spikiness
- Enough to absorb a spike's start
- Not peak held continuously
4. Balance Layer
Cost versus latency.
Balance decisions:
- Cost and latency balanced
- Neither extreme
- Tuned to the workload
5. Monitoring Layer
Spikes and scaling.
Monitoring decisions:
- Spikes and scaling monitored
- Latency under spikes tracked
- Cost proportionality checked
Benefits Gained from a Balanced Policy
- Spikes met within latency
- Cost proportional to traffic, not peak continuously
- Capacity and cost balanced for spiky traffic
How It All Works Together
The policy is tuned to the traffic's spikiness rather than one extreme. Scaling speed is responsive enough that spikes are met within latency, with predictive scaling where patterns allow. Warmed capacity, pre-provisioned, absorbs the scaling lead time so capacity can start fast when a spike begins, and headroom is tuned to the spikiness, enough to absorb a spike's onset without holding peak continuously. Cost and latency are balanced, neither extreme, with spikes, scaling, latency, and cost proportionality monitored. The spiky AI traffic is met within latency at a cost proportional to traffic, because the policy balances capacity and cost rather than being tuned to miss spikes or waste cost.
Common Misconception
Autoscaling handles spiky traffic automatically.
Autoscaling tuned to one extreme either scales too slowly for spikes, missing them because inference scaling has lead time, or holds too much capacity, paying for peak when quiet. Handling spiky AI traffic requires a policy that balances capacity and cost, with tuned scaling speed, warmed capacity, and headroom, not a default.
Key Takeaway: Spiky AI traffic needs a policy that balances capacity and cost, scaling fast for spikes with warmed capacity, not a one-extreme default.
Real-World Balanced Policy in Action
Let's take a look at how a balanced policy operates with a real-world example.
We worked with a team whose autoscaling missed spikes or wasted cost, with these constraints:
- Meet spikes within latency
- Avoid paying for peak continuously
- Balance capacity and cost
Step 1: Tune Scaling Speed
React to spikes.
- Responsive scaling
- Reaction versus spike onset
- Predictive where patterns allow
Step 2: Add Warmed Capacity
Absorb lead time.
- Warmed capacity pre-provisioned
- Start fast on a spike
- Tuned to onset
Step 3: Tune Headroom
Buffer.
- Headroom tuned to spikiness
- Absorb spike onset
- Not peak continuously
Step 4: Balance Cost and Latency
Neither extreme.
- Cost and latency balanced
- Tuned to the workload
- Neither extreme
Step 5: Monitor
Track.
- Spikes and scaling monitored
- Latency under spikes
- Cost proportionality
Where It Works Well
- Scaling speed and warmed capacity tuned to spikes
- Headroom tuned to spikiness, not peak held
- Cost and latency balanced and monitored
Where It Does Not Work Well
- Policy tuned to one extreme
- Missing spikes or paying for idle peak
- Cost or latency considered alone
Key Takeaway: The autoscaling that handles spiky AI traffic is the one balancing capacity and cost, scaling fast with warmed capacity, not the policy tuned to one extreme.
Common Pitfalls
i) Tuning to one extreme
A policy tuned only for cost misses spikes; only for capacity wastes cost. Balance the two.
- Tune scaling speed
- Add warmed capacity
- Tune headroom
ii) Ignoring scaling lead time
Inference scaling takes time, so a spike hits before capacity arrives. Use warmed capacity and fast scaling.
iii) Holding peak continuously
Capacity-tuned policies pay for idle peak. Hold headroom for spikes, not peak continuously.
iv) No monitoring
Without monitoring spikes, latency, and cost, the policy cannot be tuned. Monitor them.
Takeaway from these lessons: Most spiky-traffic autoscaling problems trace to one-extreme tuning and ignored lead time, not to autoscaling. Balance capacity and cost with scaling speed, warmed capacity, and headroom.
Spiky-Traffic Policy Best Practices: What High-Performing Teams Do Differently
1. Balance capacity and cost
Tune the policy to balance meeting spikes within latency against paying for peak, not to one extreme.
2. Tune scaling speed to spike onset
Make scaling responsive enough for spikes, with predictive scaling where patterns allow.
3. Use warmed capacity for lead time
Pre-provision warmed capacity to absorb inference scaling lead time so capacity starts fast.
4. Tune headroom to spikiness
Hold enough headroom to absorb a spike's onset, not peak capacity continuously.
5. Monitor spikes, latency, and cost
Monitor to tune the policy, keeping latency met under spikes and cost proportional.
Logiciel's value add is helping teams set autoscaling policies for spiky AI traffic that balance capacity and cost, scaling speed, warmed capacity, headroom, so spikes are met within latency without paying for peak continuously.
Takeaway for High-Performing Teams: Focus on balancing capacity and cost for the spikiness. Spiky AI traffic needs a policy that scales fast with warmed capacity to meet spikes, while holding headroom not peak, so latency is met and cost stays proportional.
Signals You Are Autoscaling Spiky Traffic Correctly
How do you know the policy is balanced? Not in one metric, but in meeting spikes affordably. Below are the signals that distinguish a balanced policy from one-extreme tuning.
Spikes are met within latency. The policy scales fast enough for spikes.
Cost is proportional. The policy does not hold peak capacity when traffic is quiet.
Warmed capacity absorbs lead time. Capacity starts fast on a spike.
Headroom matches spikiness. Enough headroom for spike onset, not peak continuously.
Spikes and cost are monitored. The policy is tuned from monitored spikes, latency, and cost.
Adjacent Capabilities and Connected Work
This work does not exist in isolation. Spiky-traffic autoscaling depends on, and feeds into, several adjacent capabilities. Building one without thinking about the others is the most common scoping mistake.
In most organizations, autoscaling shares infrastructure with the inference serving stack, the capacity planning, and the cost-management process. It shares capacity with ML infrastructure, platform engineering, and the teams owning the service. And it shares leadership attention with whatever the next AI infrastructure initiative is on the roadmap. Naming these adjacencies upfront helps the program scope realistically and helps leadership see the work as a portfolio rather than a one-off project.
The most common mistake in adjacency-capability scoping is treating each adjacency as someone else's problem. The serving stack's scaling lead time is your problem. The capacity planning the policy works within is your problem. The cost monitoring is your problem. Pretending otherwise pushes work to teams that did not plan for it, and the work returns to you later as missed spikes or wasted cost. Own the adjacencies you depend on; partner with the teams that own them; share the timeline.
Conclusion
Autoscaling policies for spiky AI traffic balance capacity and cost, scaling fast for spikes with warmed capacity and tuned headroom, without paying for peak continuously. The discipline that delivers it is the same discipline behind any autoscaling: tune the policy to the workload's actual pattern, not to one extreme.
Key Takeaways:
- Spiky AI traffic needs a policy balancing capacity and cost
- Tune scaling speed, warmed capacity, and headroom to the spikiness
- Meet spikes within latency without paying for peak continuously
Setting the policy well requires speed, warmed-capacity, and headroom discipline. When done correctly, it produces:
- Spikes met within latency
- Cost proportional to traffic, not peak continuously
- Capacity and cost balanced for spiky traffic
- A monitored, tuned policy
Healthcare CIO Cuts AI Costs Without Accuracy Loss
A field guide to AI cost optimization for VP Engineering teams running clinical and operational LLMs in production.
What Logiciel Does Here
If your AI autoscaling misses spikes or wastes cost, tune the policy to balance capacity and cost, scaling speed, warmed capacity, and headroom for your spikiness.
Learn More Here:
- Capacity Planning for AI Inference Fleets
- Cluster Autoscaling That Doesn't Surprise Your Finance Team
- AI Inference Cost Optimization
At Logiciel Solutions, we work with platform and ML infrastructure leaders on autoscaling for spiky AI traffic, capacity-cost balance, and tuning. Our reference patterns come from production inference services.
Explore autoscaling policies that balance capacity and cost for spiky AI traffic.
Frequently Asked Questions
What is a spiky-traffic autoscaling policy?
A policy that balances capacity and cost for traffic that surges and quiets, scaling fast enough to meet spikes within latency, with tuned warmed capacity and headroom, while not holding peak capacity when traffic is quiet. It is tuned to the spikiness, not one extreme.
Why doesn't default autoscaling handle spiky AI traffic?
Because a policy tuned to one extreme either scales too slowly for spikes, missing them since inference scaling has lead time, or holds too much capacity, paying for peak when quiet. Spiky traffic needs a policy that balances capacity and cost with tuned scaling speed, warmed capacity, and headroom.
What is warmed capacity and why does it matter?
Pre-provisioned capacity kept ready so the service can start handling a spike fast, absorbing the lead time it takes to scale inference. It matters because without it, a spike can hit before newly scaled capacity arrives, degrading latency.
How do you avoid paying for peak capacity continuously?
By holding headroom tuned to the spikiness, enough to absorb a spike's onset, rather than holding peak capacity at all times, and by scaling down promptly when traffic quiets. The policy balances enough warmed capacity for spikes against not paying for idle peak.
What is the biggest mistake in autoscaling spiky AI traffic?
Tuning the policy to one extreme, cost or capacity. Cost-tuned misses spikes and degrades latency; capacity-tuned pays for idle peak. Balance the two with tuned scaling speed, warmed capacity, and headroom matched to the traffic's spikiness, and monitor to tune.

