Standing up a container orchestration cluster is the easy part; the hard part, and where DevOps leads get caught, is everything around it: networking, storage, security, observability, and the operating model. A running cluster that nobody can observe, that has no resource governance, and that was secured by default is not production-ready, it is a future incident. This checklist is about the foundations that make orchestration actually work in production, not just the cluster that technically runs.
Energy Operator Built Real-Time Grid Signal Pipeline
A real-time grid pipeline playbook for Heads of Data Platform.
Container orchestration automates deploying, scaling, scheduling, and healing containerized workloads across a cluster. Implementing it well means getting the surrounding foundations right, networking, storage, security, observability, resource governance, and an operating model, because those are what make orchestration reliable and safe in production. This checklist covers the foundations a DevOps lead has to get right.
What Implementing Orchestration Involves
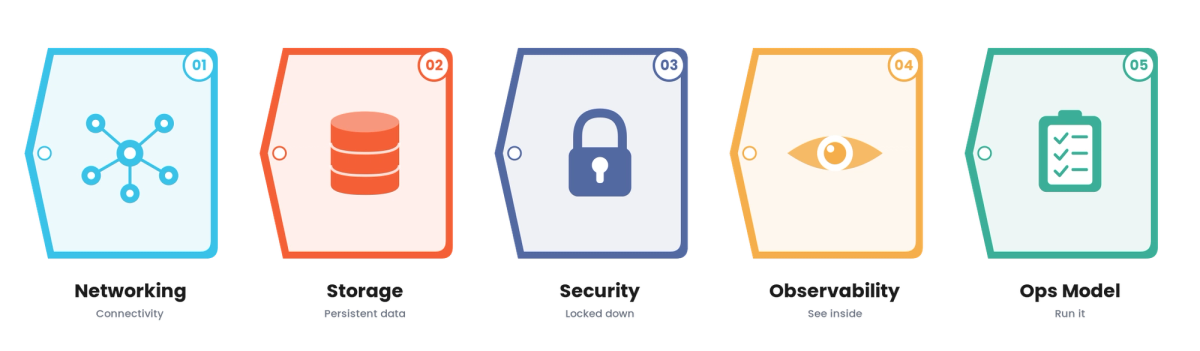
A running orchestration cluster is necessary but not sufficient. Production-ready orchestration also needs: networking (how services communicate and are exposed), storage (how stateful workloads persist data), security (access control, secrets, workload isolation, not defaults), observability (so you can see what the cluster and workloads are doing), resource governance (so workloads do not over-consume or starve each other), and an operating model (who runs and upgrades the cluster). The cluster is the start; these foundations are what make it production-ready.
The Implementation Checklist
- Get networking right. Decide how services communicate, how traffic is routed in, and how the network is segmented. Networking is a common source of orchestration complexity and failure.
- Plan storage for stateful workloads. Orchestration handles stateless workloads easily; stateful ones need deliberate storage planning. Get this right before running stateful services.
- Secure beyond defaults. Default orchestration security is not production-grade. Set up access control, secrets management, and workload isolation deliberately.
- Build observability in. You cannot operate what you cannot see. Ensure visibility into the cluster, workloads, and their behavior from the start.
- Govern resources. Set resource requests, limits, and quotas so workloads do not over-consume or starve each other, controlling both reliability and cost.
- Define the operating model. Decide who runs, upgrades, and responds to issues on the cluster. Orchestration is an ongoing operational responsibility, or use a managed option.
Common Misconception
The misconception that ships future incidents: implementing container orchestration is standing up the cluster.
The cluster is the easy, visible part. Production-ready orchestration requires the foundations around it, networking, storage, security, observability, resource governance, and an operating model, which is most of the work. A running cluster without those is not production-ready; it is a future incident waiting on the missing security, observability, or governance. Treating implementation as "stand up the cluster" is why orchestration rollouts hit problems the foundations would have prevented.
Key Takeaway: Implementing container orchestration is getting the foundations right, networking, storage, security, observability, governance, operating model, not just standing up the cluster. The cluster is the start; the foundations make it production-ready.
Where Orchestration Implementation Goes Right
- Networking, storage, and security set up deliberately, not by default
- Observability and resource governance built in from the start
- A clear operating model (or managed orchestration)
Where It Goes Wrong
- Standing up the cluster and calling it production-ready
- Default security, no observability, no resource governance
- No operating model, so the cluster is unowned
Key Takeaway: Orchestration is production-ready when the foundations are in place; a running cluster without them is a future incident.
What High-Performing DevOps Teams Do Differently
- Set up networking and storage deliberately.
- Secure beyond orchestration defaults.
- Build observability in from the start.
- Govern resources with requests, limits, and quotas.
- Define the operating model or use managed orchestration.
Logiciel's value add is helping DevOps leads implement container orchestration with the foundations right, networking, storage, security, observability, resource governance, and an operating model, so orchestration is production-ready rather than a running cluster that becomes an incident.
Takeaway for High-Performing Teams: Implement orchestration by getting the foundations right, networking, storage, security, observability, governance, operating model, not just standing up the cluster. Those foundations are most of the work and what make orchestration reliable and safe in production.
Adjacent Capabilities and Connected Work
Container orchestration shares infrastructure with the cloud platform, the CI/CD pipeline, and the observability and security stacks, and shares team capacity with platform engineering, the application teams, and security. The common scoping mistake is treating each adjacency as someone else's problem: the security beyond defaults is your problem, the observability is your problem, the operating model is your problem. Pretending otherwise returns later as an orchestration incident the foundations would have prevented. Own the adjacencies, partner with the teams that own them, share the timeline.
Conclusion
Implementing container orchestration as a DevOps lead means getting the foundations right, networking, storage, security beyond defaults, observability, resource governance, and an operating model, not just standing up a cluster. The cluster is the easy, visible part; the foundations are most of the work and what make orchestration production-ready. A running cluster without them is a future incident, so the checklist is about the foundations that make orchestration reliable and safe.
Key Takeaways:
- Implementing orchestration is the foundations, not just the cluster
- Networking, storage, security, observability, governance, operating model
- A running cluster without the foundations is a future incident
CISO Redesigned Cloud Security Without Slowing Delivery
A cloud security architecture playbook for CISOs balancing security and engineering velocity.
What Logiciel Does Here
If your container orchestration is a running cluster without the foundations, get them right: networking, storage, security beyond defaults, observability, resource governance, and an operating model.
Learn More Here:
- Container Orchestration vs. the Status Quo: A Decision Guide for VP Engineering
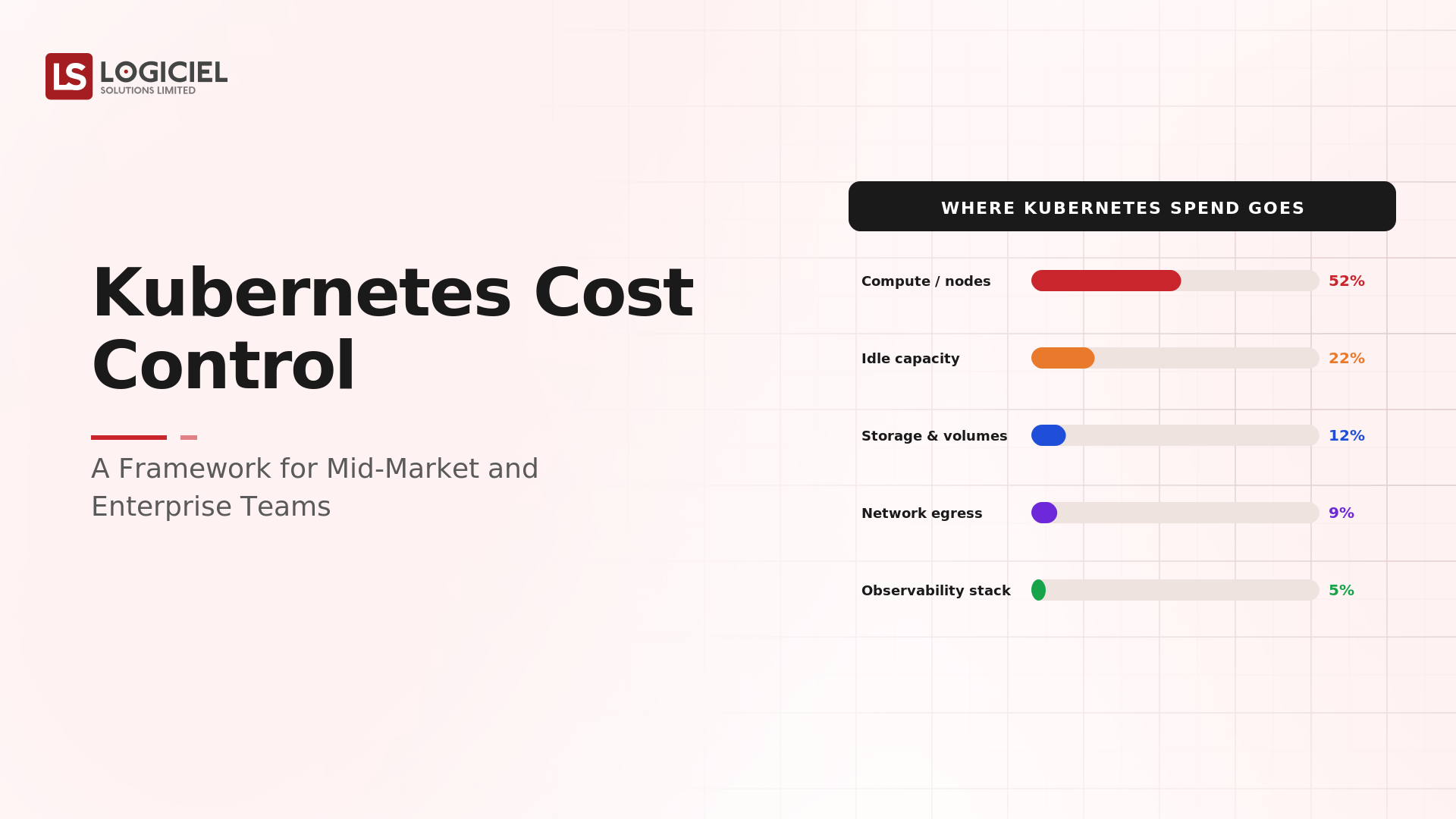
- Kubernetes Cost Control: A Framework for Mid-Market and Enterprise Teams
- Right-Sizing Kubernetes Without Causing Incidents
At Logiciel Solutions, we work with DevOps leads on container orchestration implementation, networking, storage, security, observability, and operating models. Our reference patterns come from production container platforms.
Explore the container orchestration implementation checklist for DevOps leads.
Frequently Asked Questions
What is container orchestration?
A platform that automates deploying, scaling, scheduling, and healing containerized workloads across a cluster (Kubernetes being the best-known). It manages many containers automatically. Implementing it for production requires not just the cluster but the surrounding foundations, networking, storage, security, observability, resource governance, and an operating model.
Why isn't standing up the cluster enough?
Because a running cluster without networking, storage, security beyond defaults, observability, resource governance, and an operating model is not production-ready, it is a future incident. The cluster is the easy, visible part; the foundations around it are most of the work and what make orchestration reliable and safe in production. Implementation is those foundations.
What are the most commonly missed foundations?
Security beyond defaults (default orchestration security is not production-grade), observability (you cannot operate what you cannot see), and resource governance (so workloads do not over-consume or starve each other). Networking and stateful storage are also common sources of complexity and failure. Missing any of these turns a running cluster into a fragile, hard-to-operate one.
How does resource governance fit in?
Setting resource requests, limits, and quotas so workloads get what they need without over-consuming or starving each other. It controls both reliability (workloads do not destabilize each other) and cost (workloads do not over-allocate). Without resource governance, an orchestration cluster is prone to both reliability incidents and runaway cost from over-provisioning.
Should we run orchestration ourselves or use a managed option?
That depends on whether you have the operational capacity and expertise to run the cluster and its foundations sustainably. A managed orchestration option reduces the operational burden of running the control plane and much of the infrastructure. If you lack the capacity to operate orchestration well, a managed option is often the better path, factored into the operating model decision.