The Order That Produces Different Outcomes
AI initiatives launched on top of data infrastructure that was not ready typically discover the data problems after they have committed to the AI investment. The pattern is consistent: the initiative starts with the AI capability, encounters data quality or accessibility issues, and ends up doing data engineering work as part of the AI project. The data engineering work is necessary, larger than expected, and changes the project's economics.
The order that produces better outcomes is the reverse: assess data readiness, address gaps, then add AI. The assessment takes weeks; the gap closure takes months; the AI work that follows is faster, cheaper, and more reliable than what would have happened in the reverse order.
Gartner's 2024 data and AI research suggests roughly 70 percent of failed AI initiatives traced to data infrastructure issues rather than AI-specific problems (Gartner, "Data Foundations for AI 2024"). The figure varies by source but the pattern is consistent. Most AI implementation problems are data problems.
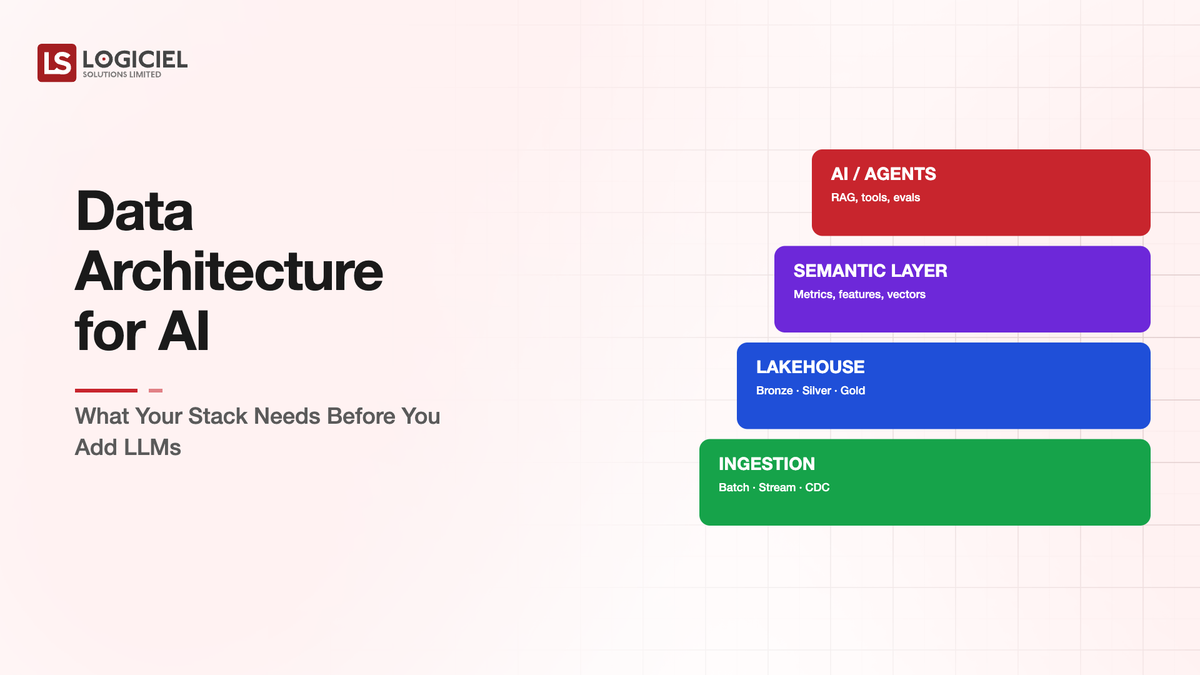
Five readiness conditions determine whether the data stack is ready for LLM workloads. Checking them before starting the AI work is much cheaper than discovering them during.

The Five Readiness Conditions
The five conditions span data inventory, quality, accessibility, governance, and lineage. Each one is a yes-or-no operational question.
Condition one is data inventory completeness. The organization knows what data it has, where it lives, what condition it is in, and who owns it. Not aspirationally. Currently and accurately. AI initiatives that depend on data the organization does not know it has are starting with incomplete information.
Condition two is data quality fit for purpose. The data is accurate, complete, and timely enough for AI workloads. The quality bar depends on the AI use case. RAG systems can tolerate some noise; decision-support AI cannot. Quality has to be measured against the specific use case, not against general standards.
Condition three is programmatic accessibility. The AI workload can access the data through documented APIs or query interfaces. Data trapped behind systems that require manual extraction or that lack programmatic access is effectively unavailable to AI workloads regardless of how good the underlying data is.
Condition four is governance maturity. The organization knows what data can be used for which AI purposes, what consent or legal basis covers each use, and what controls have to be in place. AI workloads that use data without governance clearance produce regulatory exposure that materializes later.
Condition five is lineage and metadata. The AI workload can trace data back to its source. When the AI produces an output, the underlying data and its provenance are recoverable. Without lineage, AI outputs are not auditable, which is increasingly a regulatory requirement and always a debugging requirement.
Why Audit-Ready Beats Audit-Survived Every Time
Inside a 120-day remediation that turned three material findings into zero at follow-up.
A stack with all five conditions present is ready to support LLM workloads. A stack missing one or two has gaps that can be closed alongside specific AI projects. A stack missing three or more is usually better served by closing the data gaps first before launching AI initiatives.
What Each Condition Costs to Build
The conditions have different complexity profiles for organizations that are starting from gaps.
Data inventory completeness is moderately expensive to build initially and inexpensive to maintain. Tools (data catalogs like Atlan, Collibra, Alation) automate substantial portions. The discipline of maintaining the inventory requires sustained attention but the work is routine once established.
Data quality fit for purpose varies enormously. Some workloads need clean, structured data that requires substantial engineering investment to produce. Other workloads tolerate noisier data with minimal investment. The cost depends on the use case more than on starting state.
Programmatic accessibility is the variable that often surprises teams. APIs that should exist sometimes do not. APIs that exist sometimes do not work as documented. APIs that work sometimes have rate limits or operational constraints that production AI workloads cannot accommodate. The accessibility work is often the longest path on data readiness.
Governance maturity requires legal, compliance, and engineering coordination. The work is not technical; it is organizational. Organizations with mature data governance for traditional analytics often need extensions for AI. Organizations without mature data governance need the full discipline before launching production AI.
Lineage and metadata is engineering work that benefits from modern data tools (Datafold, Monte Carlo for observability; dbt for lineage in transformation; data catalogs for metadata). The tools have matured to the point that the build cost is reasonable.
Total cost of building data readiness from a low starting state typically runs $1M-$5M over 12-18 months for a mid-market enterprise. The investment pays back through faster, cheaper, more reliable AI work afterward.
What "Ready Enough" Means for Different AI Use Cases
The five conditions matter for all AI use cases but with different weighting per use case.
RAG systems weight conditions 1 (inventory), 3 (accessibility), and 5 (lineage) heavily because retrieval depends on knowing what documents exist, being able to access them, and citing them with provenance. Quality (condition 2) and governance (condition 4) matter but with somewhat lower bar.
ML training pipelines weight conditions 1, 2, and 5 heavily. Knowing what data exists, quality fit for training, and lineage from training data to deployed models. Accessibility (condition 3) for batch use is usually simpler than for retrieval.
Decision-support AI weights all five conditions equally because the regulatory exposure and audit requirements demand each one. Credit scoring, claims processing, hiring decisions all live here.
Conversational AI for customer service weights conditions 2, 3, and 4 heavily. Quality of the knowledge base, accessibility of customer data the agent needs, and governance of what the agent can do with that data.
The mapping from use case to weighted conditions shapes which gaps are most consequential to close before launching specific AI work.
What This Looks Like in Practice
A typical mid-market enterprise's data readiness profile in 2026 looks something like this: condition 1 (inventory) is 60-80 percent complete with documented work to close gaps; condition 2 (quality) is variable by data domain with strong customer data and weak product data; condition 3 (accessibility) is strong for analytical use and weak for AI use because the APIs for AI workloads are newer; condition 4 (governance) is established for traditional analytics and being extended for AI; condition 5 (lineage) is moderate with investment underway.
Organizations in this profile can launch some AI initiatives (those that depend on the stronger conditions) and should defer others (those that depend on the weaker conditions). The roadmap reflects the data readiness rather than ignoring it.
Why ML Pilots Pass Review Then Die in Production
Inside an 8-month rebuild that turned three failed pilots into a 9:1 ROI model.
What Logiciel Does Here
Logiciel works with engineering and data leadership assessing data readiness before launching AI initiatives or remediating data gaps that have emerged during AI initiatives already underway. The work is typically structured around the five-condition assessment followed by sequenced gap closure.
The AI Data Pipelines framework covers the pipeline architecture decisions that data readiness depends on. The AI Readiness 10 Signals framework covers the broader organizational readiness that overlaps with data readiness.
A 30-minute working session is enough to assess your current data stack against the five conditions.
Frequently Asked Questions
Can I launch AI initiatives while data readiness is being built?
Yes, selectively. AI initiatives that depend on the conditions that are already strong can proceed. AI initiatives that depend on weak conditions should wait. The roadmap should match the readiness profile.
Which condition is most often the bottleneck?
Condition 3 (programmatic accessibility) for organizations with mature analytics infrastructure. Condition 1 (inventory) for organizations newer to data discipline. Condition 4 (governance) for regulated industries adopting AI for the first time in their AI history.
How do I assess data quality without launching the AI?
Sample the data manually. Check against the use case requirements. Quality issues that would affect AI usually visible in human inspection of representative samples. The assessment is imperfect but much cheaper than launching and discovering through AI failures.
What about synthetic data?
Synthetic data is a tool that can help with specific gaps, mostly volume of training data or privacy-constrained access. It does not substitute for the five conditions. A stack that is unready for real data is also unready for synthetic data because the operational conditions are the same.
How do I justify data investment when AI is the visible priority?
Through the cost of AI failures that data investment prevents. Each AI initiative that fails because of data problems is a measurable cost. Aggregated across the portfolio, the data investment usually justifies itself in prevented AI failures alone. Sources: - Gartner, "Data Foundations for AI 2024" - Forrester, "The State of Enterprise AI, 2024"