

The Shadow Pipeline Problem
A data platform team at a mid-sized enterprise built strong infrastructure over three years. Snowflake, dbt, Airflow, a feature store, comprehensive observability. By 2025, the AI team had built its own parallel infrastructure outside the platform. Vector databases, embedding pipelines, retrieval services, prompt management. The platform team found out by accident.
When asked why, the AI team said the official platform took 4-6 weeks to onboard a new data source. They needed 4-6 hours. The platform was built for analytics workloads. AI workloads needed a different shape of self-service.
Wakefield Research's 2024 survey of AI engineers found 71 percent reported their organization's data platform slows them down rather than accelerates them (Wakefield Research, "State of AI Engineering," 2024). The shadow pipeline problem is the visible symptom. The platform-AI fit problem is the cause.
If your AI team is building infrastructure outside your data platform, the platform is failing the test that matters: AI teams choosing to use it.
Coined Frame: The Four Friction Points
Four friction points determine whether AI teams use the platform or build around it. Each one is a specific decision point in the engineer's workflow.
Friction 1 - Data source onboarding time. When an AI team needs a new data source connected, how long does it take. Mature data platforms typically take 2-6 weeks (ticketing, approvals, engineering work, validation). AI teams iterate in days. The mismatch produces shadow pipelines.
Friction 2 - Schema discovery and access. When an AI engineer wants to use data they have not used before, how long does it take to find it, understand it, and get access. Most data platforms have governance friction that adds days to this step.
Friction 3 - Iteration latency. When an AI engineer modifies a pipeline or prompt, how long until they see the result. Production-grade pipelines often run on hourly or daily schedules. AI iteration needs sub-minute feedback.
Friction 4 - Production graduation path. When an AI experiment is ready for production, how much rework is required. If experimental code has to be substantially rewritten for production, AI teams build parallel production systems rather than graduating through the platform.
A platform that addresses all four friction points becomes the system AI teams choose to use. A platform that addresses none of them becomes the system AI teams route around.
The Self-Service Bar
The bar for "self-service" has risen sharply for AI workloads.
In analytics workloads, self-service means a business analyst can query data without filing a ticket. The query language is SQL, the latency is seconds, the data is at rest.
In AI workloads, self-service means an AI engineer can connect new sources, transform data, generate embeddings, run retrieval evaluations, and deploy to production without filing tickets. The interaction is programmatic, the latency is sub-minute, the data is in motion.
Most data platforms are sized for the analytics bar and fail the AI bar. The teams that have rebuilt for the AI bar share recognizable patterns.
API-first access. Every operation that an AI engineer needs is available through an API, not just through a UI. Notebooks, scripts, and AI agents can use the platform programmatically.
Pre-authorized access patterns. Data engineers approve broad access patterns once (this team can access this domain of data for these purposes), and AI engineers operate within those patterns without ticket-per-query overhead.
Fast feedback loops. Pipeline modifications, transformation changes, and eval runs complete in minutes, not hours. The architecture has to support fast iteration explicitly.
Production graduation by configuration, not rewrite. Experimental pipelines become production pipelines through configuration changes (scheduling, monitoring, scale), not through code rewrite.
These four patterns produce platforms that AI teams use because they want to, not because they have to.
What the Modern Platform Looks Like
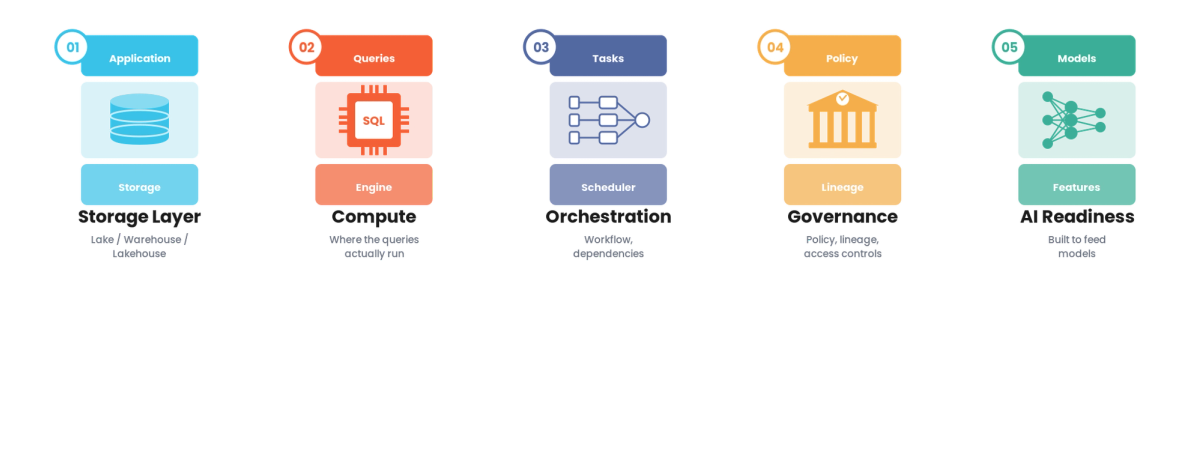
The shape of the data platform that serves AI teams in 2026 has consolidated.
Layer 1 - Storage and serving. Data warehouse or lakehouse for structured data, object storage for unstructured, vector database for embeddings. The choice of vendor matters less than the consistency of interfaces.
Layer 2 - Transformation. dbt or equivalent for SQL transformations, Python notebooks integrated with the warehouse for programmatic transformations, embedding pipelines for AI-specific work. The transformation layer has to handle both analytical and AI workloads without forcing engineers to choose tools.
Layer 3 - Orchestration. Airflow, Dagster, Prefect, or equivalent for scheduled work. Increasingly, event-driven orchestration for AI workloads that need to respond to upstream changes.
Layer 4 - Observability and cost management. Cross-cutting visibility into pipeline health, cost, quality, and usage. AI workloads add specific metrics (token costs, embedding generation rates, retrieval quality) that the platform has to track natively.
Layer 5 - Self-service interface. APIs, SDK, CLI, and UI that make the platform usable by AI engineers without platform team mediation.
The teams that have rebuilt their platforms with the AI use case as a first-class requirement typically end up at this five-layer shape regardless of vendor choice.
The Governance Question
The hardest question in building self-service AI data platforms is governance.
Strong governance protects against data leakage, regulatory violations, and quality problems. Strong governance also produces the friction that makes AI teams build shadow infrastructure. The bar that works in 2026 is governance through automation rather than governance through approval.
Examples of governance through automation: data classification applied at ingestion, access policies enforced at query time, audit trails generated automatically, PII detection in pipelines, lineage tracking across transformations. Each control is a runtime check, not a pre-approval gate.
The platforms that have built this pattern typically reduce governance friction by 60-80 percent while maintaining or improving actual compliance posture. The shift is from "engineers wait for governance approval" to "governance enforces itself and engineers operate within the enforced bounds."
What This Costs
Rebuilding a data platform to meet the AI team's bar typically requires a dedicated platform engineering team of four to eight engineers for two to four quarters, depending on starting state. The investment is meaningful and the payoff is operational rather than financial in the first year.
The alternative cost is the cost of shadow infrastructure that grows in parallel to the official platform. Shadow infrastructure usually costs more than the official platform once aggregate spend is counted, and it carries security and compliance risk that the official platform was designed to manage.
What Logiciel Does Here
Logiciel works with data platform leaders who recognize the AI team gap and want to close it. The work is structured around the four friction points: which one is the binding constraint, what specific platform changes address it, and how to sequence the changes without disrupting existing analytics workloads.
The AI Data Pipelines framework covers the pipeline-specific architecture decisions. The Continuous Intelligence Architecture framework covers how the platform supports the broader inference-first stack.
A 30-minute working session is enough to map your current platform against the four friction points and identify the highest-leverage gap.
Frequently Asked Questions
How do I get AI teams to migrate from shadow infrastructure back to the platform?
Make the platform genuinely better than what they built. Ship one capability they need badly. Let them keep their existing work running while they migrate piece by piece. Forced migration usually fails. Migration through superior fit usually succeeds.
Should I build a separate platform for AI workloads?
Almost never. Two platforms create governance gaps, duplicate cost, and fragment the data team. The right answer is one platform with AI-specific capabilities built in. The wrong answer is one platform for analytics and another for AI.
What is the right team size for a modern data platform?
Smaller than analytics-era platforms required. Four to eight engineers can run a serious platform serving 100-300 analytics and AI engineers, if the platform is well-designed. The platforms requiring 20+ platform engineers usually have accumulated technical debt that limits leverage.
How do I prioritize between governance and self-service?
They are not opposites. Governance through automation enables self-service. The framing of "trade off governance for self-service" usually means the governance has been implemented as approval gates rather than as automated controls. Fix the implementation, not the priority.
How do I handle the cultural change of self-service?
Start with one team that wants self-service and is willing to operate within the platform's bounds. Build the success story. Other teams follow. Top-down mandates for self-service without bottom-up demand rarely work because the platform has to actually serve the use case. Sources: - Wakefield Research, "State of AI Engineering," 2024 - dbt Labs, "Analytics Engineering Benchmarks 2024"

