If you are a CTO standing up SRE, the failure mode to avoid is obvious and common: renaming your ops team to "SRE," changing nothing else, and wondering why reliability did not improve. SRE is a set of practices, measurable reliability targets, error budgets, toil reduction, blameless incident response, with the organizational backing to make them real. The title is the easy part. This checklist is the hard part: the decisions and foundations a CTO has to get right for SRE to work.
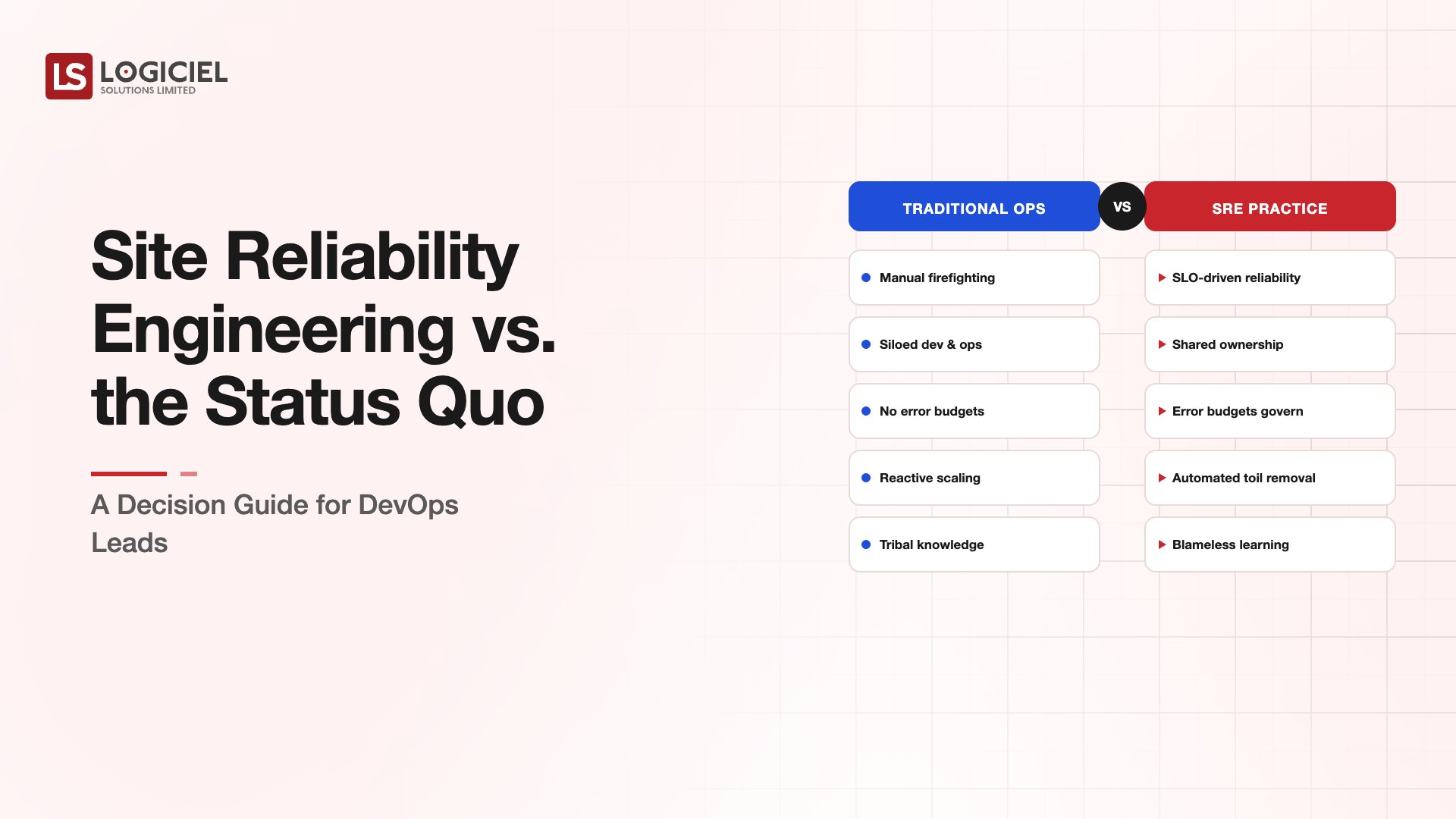
Site reliability engineering treats reliability as an engineering problem with explicit targets and an explicit budget for failure, run by people who are expected to automate away the toil rather than absorb more of it. Done right, it makes reliability measurable and gives the organization a shared language for the eternal reliability-versus-velocity tension. Done as a rename, it is a new org chart and the same incidents.
Here is the checklist, grouped by the foundations a CTO owns: the targets, the budgets, the practices, and the backing. Work through it before you declare an SRE function exists.
Healthcare CIO Cuts AI Costs Without Accuracy Loss
A field guide to AI cost optimization for VP Engineering teams running clinical and operational LLMs in production.
What SRE Actually Requires
SRE rests on a few load-bearing ideas. Reliability gets defined as measurable objectives (SLOs) tied to what users actually need. Those objectives imply an error budget, the amount of unreliability you tolerate before reliability work takes priority over features. Toil, the manual, repetitive operational work, is treated as something to engineer away, not staff up for. Incidents are handled blamelessly, so the organization learns instead of hides. And all of this needs leadership backing, because the error budget is meaningless if features always win the argument. A CTO's job is to make these real, not to print new titles.
The Implementation Checklist
1. Define SLOs that mean something
For the services that matter, set reliability objectives tied to real user needs, not an arbitrary number of nines. An SLO nobody chose deliberately is an SLO nobody will defend.
2. Set error budgets and the rule for spending them
Define the acceptable unreliability each SLO allows, and decide in advance what happens when it is spent: reliability work takes priority over features until the budget recovers. Write the rule down before you need it.
3. Make the error-budget rule have teeth
Decide, as CTO, that the error-budget rule is real and that you will back it when product pushes back. This is the single decision that determines whether SRE is a practice or a costume.
4. Measure and attack toil
Measure how much time the team spends on manual operational work, and set the expectation that SREs reduce it through engineering. If SREs just absorb more toil, you have hired expensive operators.
5. Stand up blameless incident response
Establish incident response with blameless postmortems, so the organization learns from failure instead of punishing it. Fear hides the information you need to get more reliable.
6. Instrument before you promise
You cannot meet or measure an SLO you cannot observe. Make sure the observability exists to measure reliability honestly before you commit to targets.
7. Decide the operating model
Choose how SRE engages: embedded in teams, a central function, or a hybrid. Each has trade-offs; the wrong fit for your org structure undermines the rest.
Common Misconception
The misconception that kills most SRE rollouts: SRE is an ops team with a better name.
It is not. SRE is a set of practices, measurable targets, an enforced error budget, engineered-away toil, blameless learning, backed by leadership willing to let reliability sometimes beat velocity. Rename ops to SRE without those, and you get the same team doing the same firefighting under a new banner. The practices and the backing are the substance. The title is decoration.
Key Takeaway: SRE is practices plus leadership backing, not a renamed ops team. The error-budget rule with teeth is the decision that makes it real.
Where SRE Implementation Goes Right
- Meaningful SLOs and enforced error budgets the CTO backs
- Toil measured and engineered down, not absorbed
- Blameless incident response that produces learning
Where It Goes Wrong
- Renaming ops to SRE and changing nothing else
- An error budget that features always overrule
- SREs staffed to absorb toil instead of eliminate it
Key Takeaway: SRE delivers reliability when the practices are real and leadership backs the error budget, not when the org chart is relabeled.
What High-Performing Teams Do Differently
1. Set deliberate SLOs
They tie reliability targets to real user needs and defend them.
2. Enforce the error budget
They let reliability beat features when the budget is spent, with leadership backing.
3. Engineer away toil
They measure toil and reduce it, instead of hiring to absorb more of it.
4. Run blameless postmortems
They learn from incidents instead of punishing them.
5. Instrument first
They build the observability to measure reliability before promising targets.
Logiciel's value add is helping CTOs implement SRE as a practice, meaningful SLOs, enforced error budgets, toil reduction, and blameless incident response, with the observability and operating model to support it, so SRE improves reliability instead of relabeling ops.
Takeaway for High-Performing Teams: Implement SRE as practices plus backing, not a rename. The CTO's decisive act is making the error-budget rule real and defending it. Everything else follows from that.
Adjacent Capabilities and Connected Work
This work does not exist in isolation. SRE depends on, and feeds into, several adjacent capabilities. Building one without thinking about the others is the most common scoping mistake.
In most organizations, SRE shares infrastructure with the observability stack, the deployment pipeline, and the incident management process. It shares team capacity with platform engineering, the product teams whose features compete with the error budget, and operations. And it shares leadership attention with whatever the next reliability or velocity initiative is on the roadmap. Naming these adjacencies upfront helps the program scope realistically and helps leadership see the work as a portfolio rather than a one-off project.
The most common mistake in adjacent-capability scoping is treating each adjacency as someone else's problem. The observability that makes SLOs measurable is your problem. The error-budget enforcement is your problem. The blameless culture is your problem to back. Pretending otherwise pushes work to teams that did not plan for it, and the work returns to you later as an SRE function in name only. Own the adjacencies you depend on, partner with the teams that own them, and share the timeline.
Conclusion
Implementing SRE as a CTO means getting the foundations right: meaningful SLOs, enforced error budgets you actually back, toil measured and engineered down, blameless incident response, and the observability and operating model to support it. The title is trivial to grant. The practices, and your willingness to let reliability sometimes win, are what turn SRE from a costume into a capability.
Key Takeaways:
- SRE is practices plus leadership backing, not a renamed ops team
- The enforced error budget is the decision that makes SRE real
- Toil reduction, blameless learning, and observability are the foundations
Done right, SRE makes reliability measurable, gives the organization a shared language for reliability versus velocity, and steadily reduces both incidents and toil.
Real Estate Platform Ships Agentic AI in 10 Weeks
A time-to-value playbook for VPs of Product who need agents in production this quarter, not next year.
What Logiciel Does Here
If your SRE function is a renamed ops team, implement the practices: meaningful SLOs, an enforced error budget you back, toil reduction, and blameless incident response.
Learn More Here:
- The SLO Handbook: Setting Targets That Mean Something
- The SRE Error Budget Conversation: Reliability vs. Velocity
- Incident Management and On-Call Engineering
At Logiciel Solutions, we work with CTOs on SRE implementation, SLOs, error budgets, toil reduction, and incident response. Our reference patterns come from production reliability programs.
Explore the site reliability engineering implementation checklist for CTOs.
Frequently Asked Questions
What is site reliability engineering?
A set of practices that treat reliability as an engineering problem with explicit, measurable targets (SLOs), an explicit budget for failure (error budgets), toil engineered away rather than staffed up, and blameless incident response, run with leadership backing so reliability can sometimes take priority over features. It is practices and backing, not a job title.
What is the single most important decision a CTO makes?
Making the error-budget rule real and backing it when product pushes back. The error budget, the agreement that reliability work takes priority once unreliability exceeds the budget, is meaningless if features always win the argument. That decision determines whether SRE is a practice or a costume.
Why isn't renaming the ops team enough?
Because the title carries none of the substance. Without meaningful SLOs, an enforced error budget, toil reduction, and blameless learning, a renamed ops team does the same firefighting under a new banner. The practices and the leadership backing are what improve reliability, not the relabeling.
What is toil, and why does it matter?
Toil is the manual, repetitive operational work that scales with the system instead of being automated away. SRE treats it as something to engineer down, not absorb. If SREs simply take on more toil, you have hired expensive operators and missed the point, which is freeing engineering time by eliminating the repetitive work.
Do we need observability before setting SLOs?
Yes. You cannot meet or honestly measure a reliability target you cannot observe. Instrumenting the services so you can measure reliability has to come before committing to SLOs, otherwise the targets are aspirations you have no way to track or defend.