

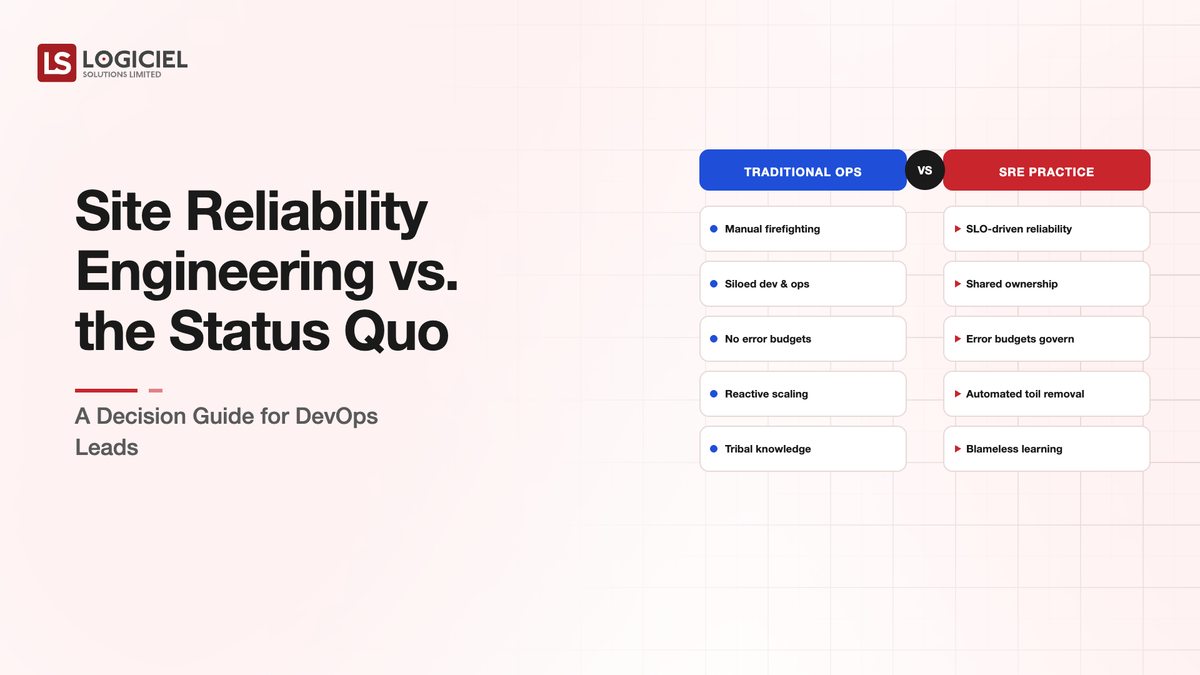
Adopt SRE when your reliability problems have outgrown informal ownership, and not before. That is the decision in one line. SRE is not strictly better than a solid DevOps status quo; it is more structure, more measurement, and more process, which pays off at a certain scale and complexity and is dead weight below it. A DevOps lead's job here is to judge which side of that line your organization is on, honestly.
The status quo for many teams is competent DevOps: CI/CD, on-call, monitoring, engineers who own what they ship. SRE adds explicit reliability objectives, error budgets, formal toil reduction, and often a dedicated function. The question is not which sounds more advanced. It is whether the added structure buys you reliability you are currently failing to get, or just adds ceremony to a system that is already fine.
This guide gives you the decision: what each approach is, the signals that you have outgrown the status quo, the signals that you have not, and how to choose without cargo-culting whatever the big tech companies do.
What Each Approach Is
The status quo, done well, is mature DevOps: developers own their services, there is CI/CD and monitoring, on-call exists, and reliability is managed through good engineering judgment and informal norms. It works, often surprisingly far. SRE formalizes what the status quo leaves implicit: reliability becomes measurable SLOs, failure tolerance becomes an explicit error budget, toil becomes something measured and engineered away, and incidents feed blameless learning. The trade is structure for rigor. The question is whether you need the rigor.
Agentic AI Launch in Just 10 Weeks
An AI governance playbook for Chief Risk Officers in regulated energy markets.
Signals You Have Outgrown the Status Quo
1. Reliability arguments have no shared language
If "how reliable is reliable enough" is settled by whoever argues hardest, you need SLOs and error budgets to make it a measured decision rather than a personality contest.
2. Reliability and velocity fight constantly
If every release is a tense negotiation between shipping and stability, the error budget gives both sides a rule instead of a recurring fight.
3. Toil is drowning the team
If manual operational work is eating the team and growing with the system, SRE's discipline of measuring and engineering away toil addresses it directly.
4. Incidents repeat without learning
If the same failures recur and postmortems are blame sessions or do not happen, blameless incident response is a real upgrade.
5. Scale has made informal ownership fail
If the system is large and complex enough that informal norms no longer hold reliability together, the formal structure earns its cost.
Signals the Status Quo Is Still Enough
1. Reliability is fine and not contentious
If your systems are reliable enough for your users and nobody is fighting about it, SRE's machinery solves a problem you do not have.
2. The team is small and the system simple
At small scale, informal ownership is faster and lighter than formal SRE structure, which would add overhead without proportional benefit.
3. You would adopt the titles, not the practices
If you cannot commit to enforcing an error budget, adopting SRE is theater. The status quo is more honest than a costume.
Common Misconception
The misconception that drives bad adoptions: SRE is the advanced, correct version of DevOps, so mature teams should adopt it.
SRE is not universally more advanced; it is more structured, which is an advantage at scale and complexity and a cost below it. Plenty of teams run reliably for years on a strong DevOps status quo and would gain nothing but overhead from formal SRE. Adopting it because the big companies did, or because it sounds advanced, is how you bolt process onto a system that did not need it.
Key Takeaway: SRE trades structure for rigor. Adopt it when reliability problems have outgrown informal ownership, not because it sounds more advanced than your status quo.
Where SRE Wins
- Large, complex systems where informal ownership has stopped holding
- Constant reliability-versus-velocity conflict that needs a shared rule
- Drowning toil and repeating incidents that need formal discipline
Where the Status Quo Wins
- Smaller teams and simpler systems where informal ownership is faster
- Reliability that is already fine and uncontentious
- Organizations that would adopt SRE titles but not enforce the practices
Key Takeaway: The right choice depends on whether your reliability problems have outgrown informal ownership. Below that line, the status quo wins on speed and simplicity.
What High-Performing DevOps Leads Do Differently
1. Diagnose before adopting
They judge whether reliability problems have outgrown the status quo, rather than adopting SRE on reputation.
2. Adopt practices, not titles
If they adopt SRE, they commit to the enforced error budget and toil reduction, not just the labels.
3. Adopt incrementally
They take the SRE practices that solve a real problem (often SLOs and error budgets first) rather than the whole apparatus at once.
4. Keep what works
They do not throw away a strong DevOps status quo; they add rigor only where it pays.
5. Revisit the decision
They re-evaluate as scale grows, since the line moves.
Logiciel's value add is helping DevOps leads make the SRE-versus-status-quo call honestly, diagnosing whether reliability problems have outgrown informal ownership, and adopting the SRE practices that solve real problems incrementally, rather than bolting on structure that does not pay.
Takeaway for High-Performing Teams: Decide based on whether your reliability problems have outgrown informal ownership. SRE's structure is an asset at scale and a cost below it. Adopt the practices that solve a real problem, keep the status quo that works.
Adjacent Capabilities and Connected Work
This work does not exist in isolation. The SRE-versus-status-quo decision depends on, and feeds into, several adjacent capabilities. Building one without thinking about the others is the most common scoping mistake.
In most organizations, this decision shares infrastructure with the observability stack, the deployment pipeline, and the incident process. It shares team capacity with platform engineering, the development teams, and operations. And it shares leadership attention with whatever the next reliability initiative is on the roadmap. Naming these adjacencies upfront helps the program scope realistically and helps leadership see the work as a portfolio rather than a one-off project.
The most common mistake in adjacent-capability scoping is treating each adjacency as someone else's problem. The observability that any reliability practice depends on is your problem. The error-budget enforcement, if you adopt it, is your problem. The honest diagnosis is your problem to make. Pretending otherwise pushes work to teams that did not plan for it, and the work returns to you later as either unmanaged reliability or pointless process. Own the adjacencies you depend on, partner with the teams that own them, and share the timeline.
Conclusion
Choosing between SRE and the status quo is a judgment about scale and pain, not prestige. SRE adds structure, measurement, and process that pay off when reliability problems have outgrown informal ownership, and weigh you down when they have not. A DevOpslead's job is to diagnose which side of that line the organization is on, adopt the practices that solve real problems, and keep the status quo where it already works.
Key Takeaways:
- SRE trades structure for rigor; it pays at scale and complexity, not below
- Adopt it when reliability problems have outgrown informal ownership
- Adopt practices, not titles, and adopt incrementally
Done right, the decision gives you the right amount of reliability process for your actual scale, neither unmanaged risk nor ceremony for its own sake.
90-Day AI Production Guide for CTOs
Move AI from demo to durable production system, without burning your roadmap.
What Logiciel Does Here
Before adopting SRE, diagnose honestly: have your reliability problems outgrown informal ownership? If yes, adopt the practices that solve them. If no, keep the status quo that works.
Learn More Here:
- Site Reliability Engineering Implementation Checklist for CTOs
- The SRE Error Budget Conversation: Reliability vs. Velocity
- The SLO Handbook: Setting Targets That Mean Something
At Logiciel Solutions, we work with DevOps leads on the SRE-versus-status-quo decision, SLOs, error budgets, and incremental adoption. Our reference patterns come from production reliability programs.
Explore site reliability engineering versus the status quo, a decision guide for DevOps leads.
Frequently Asked Questions
Is SRE just a more advanced version of DevOps?
No. SRE is more structured, not universally more advanced. It formalizes what a good DevOps status quo leaves implicit: measurable reliability targets, an explicit error budget, formal toil reduction. That structure is an advantage at scale and complexity and a cost below it, so it is not strictly better than a strong existing approach.
When should a team adopt SRE?
When reliability problems have outgrown informal ownership: reliability arguments have no shared language, reliability and velocity fight constantly, toil is drowning the team, incidents repeat without learning, or scale has made informal norms fail. Those are the signals the added structure will pay for itself.
When is the status quo still the better choice?
When reliability is already fine and uncontentious, when the team is small and the system simple enough that informal ownership is faster, or when you would adopt SRE titles without committing to the practices. In those cases, formal SRE adds overhead without proportional benefit.
Can we adopt SRE partially?
Yes, and you usually should. Take the practices that solve a real problem first, often SLOs and error budgets, rather than the whole apparatus at once. Incremental adoption lets you add rigor where it pays and keep the parts of your status quo that already work.
What is the biggest mistake DevOps leads make here?
Adopting SRE on reputation, because big tech companies do it or because it sounds advanced, rather than diagnosing whether their reliability problems have actually outgrown informal ownership. That bolts process onto a system that did not need it, or worse, adopts SRE titles without enforcing the practices, which is theater.

