

A cloud architecture diagram that says "scalable" and a system that actually scales under load are two very different things, and the distance between them is where most "build for scale" efforts stall. The strategy is the diagram. Production is the system that holds up when traffic, data, and teams grow, which depends on a hundred details the diagram waves past. An engineering partner shortens that crossing by having built systems that scaled, and seen the ones that did not.
EHR Integration Problems Engineers Actually Face
The three gaps between Epic's FHIR R4 documentation and production behavior.
Cloud architecture for scale means designing systems that handle growth, in traffic, data, and teams, without breaking or requiring a rebuild. The strategy describes the scalable design; production is making it real, with the autoscaling, statelessness, data partitioning, and operational maturity that scaling actually requires. The gap is large because scaling is mostly in the details, and the enterprise is often designing for a scale it has not hit yet.
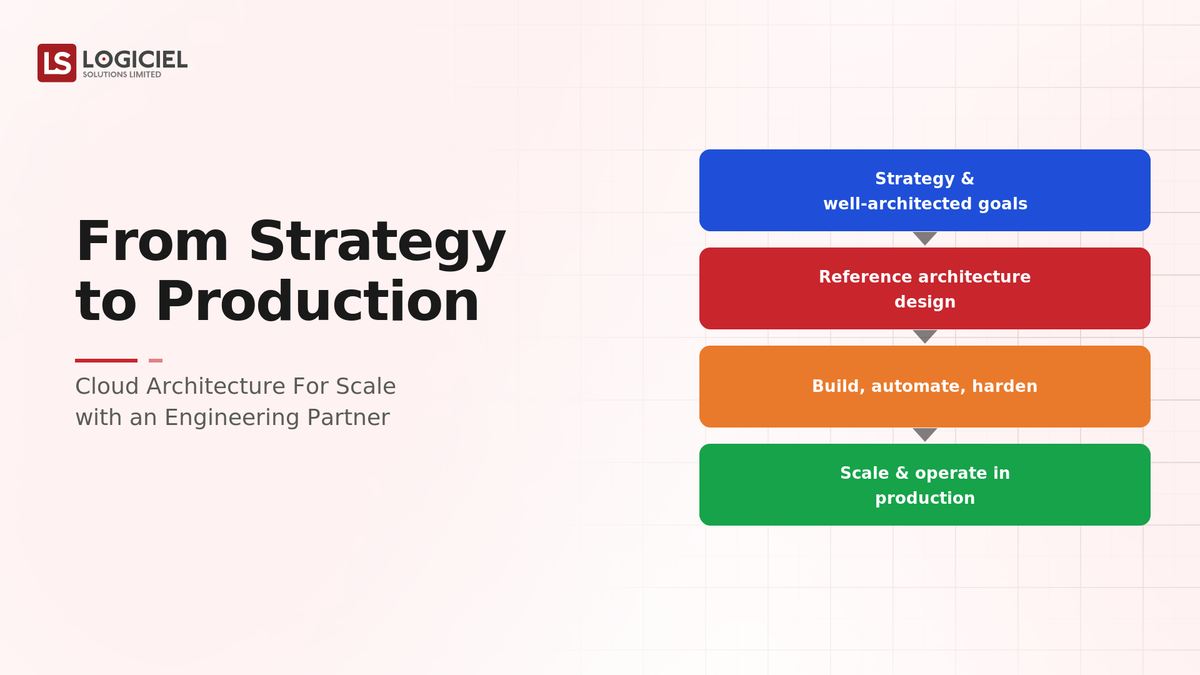
The Gap Between Strategy and Production
The strategy describes a scalable architecture: stateless services, horizontal scaling, partitioned data, async where it helps. Production is the system that holds those properties under real load: autoscaling that actually triggers correctly, state genuinely externalized, data partitioned so no shard is hot, dependencies that scale together, and the observability to see scaling behavior. The gap is wide because "scalable" on a diagram is a claim, and scaling is proven only under load. The enterprise designing for future scale rarely has the experience of what breaks first.
The Path From Strategy to Production
- Translate the strategy into concrete scaling mechanisms. Turn "scalable" into specifics: what scales horizontally, where state lives, how data partitions, what the bottlenecks are.
- Find and fix the first bottlenecks. Identify what breaks first under load, often the database or a stateful component, and address it. Scaling everything else is moot if one tier caps you.
- Prove it under load. Load-test to the target scale and beyond, so scaling is demonstrated, not assumed. A diagram does not survive contact with traffic; a load test does.
- Build the operational maturity scaling needs. Autoscaling, observability of scaling behavior, and the ability to respond when scaling misbehaves. Scaling is operational, not just architectural.
- Transfer ownership. Leave the enterprise able to run and evolve the scaled system, not dependent on the partner.
Where an Engineering Partner Adds Value
A partner has built systems that scaled and debugged the ones that did not, so they know where scaling actually breaks (usually the data tier and shared state), can scope the gap honestly, and prove scaling under load rather than trusting the diagram. The right partner transfers the capability to operate at scale rather than creating a dependency.
Common Misconception
The misconception that strands "build for scale" efforts: a scalable architecture diagram means the system will scale.
The diagram is a claim, not a proof. Systems that look scalable routinely fall over under real load because of a bottleneck the diagram ignored, the database, a stateful component, a dependency that did not scale with the rest. Scaling is proven under load, in the details, not asserted in a design. Treating the diagram as the finish line is why systems hit a wall at the scale they were "designed" for.
Key Takeaway: Cloud architecture for scale reaches production when the design is made real and proven under load, not when the diagram says scalable. Scaling lives in the details and the bottlenecks, not the picture.
Where the Journey Goes Right
- "Scalable" translated into concrete scaling mechanisms
- First bottlenecks found and fixed, scaling proven under load
- Operational maturity for scaling, ownership transferred
Where It Goes Wrong
- Treating the diagram as proof the system scales
- Ignoring the first bottleneck (often the data tier)
- Never load-testing to the target scale
Key Takeaway: The system scales when the design is proven under load and the bottlenecks are fixed; the diagram alone is a claim that breaks under traffic.
What High-Performing Enterprises Do Differently
- Translate "scalable" into concrete mechanisms.
- Find and fix the first bottleneck before scaling the rest.
- Prove scaling under load, not on paper.
- Build the operational maturity scaling requires.
- Use a partner's experience and transfer ownership.
Logiciel'svalue add is helping enterprises take cloud architecture for scale from strategy to production, translating the design, fixing bottlenecks, proving scale under load, and building operational maturity, with the experience of systems that scaled and ones that did not.
Takeaway for High-Performing Teams: Respect the gap between a scalable diagram and a system that scales. It lives in the bottlenecks and the details. Prove scaling under load, fix the first bottleneck, and use a partner's experience to cross faster.
Adjacent Capabilities and Connected Work
Cloud architecture for scale shares infrastructure with the cloud platform, the data tier, and the observability stack, and shares team capacity with platform engineering, the application teams, and SRE. The common scoping mistake is treating each adjacency as someone else's problem: the data-tier scaling is your problem, the load testing is your problem, the scaling observability is your problem. Pretending otherwise returns later as a system that hit a wall under load. Own the adjacencies, partner with the teams that own them, share the timeline.
Conclusion
Taking cloud architecture for scale from strategy to production is closing the gap between a scalable diagram and a system that actually holds up under load, by translating the design into concrete mechanisms, fixing the first bottlenecks, proving scale under load, and building operational maturity. Scaling lives in the details and is proven under traffic, not asserted on paper. An engineering partner shortens the crossing by knowing where scaling breaks.
Key Takeaways:
- A scalable diagram is a claim; scaling is proven under load
- Find and fix the first bottleneck, usually the data tier or shared state
- Scaling is operational as well as architectural
Hidden PHI Exposure Risks in Healthcare AI
Why 90% of healthcare organizations are unknowingly exposing patient data through AI tools.
What Logiciel Does Here
If your "built for scale" system is just a scalable diagram, cross the gap: concrete mechanisms, fixed bottlenecks, and scaling proven under load.
Learn More Here:
- Why Data Architectures Break at 10x
- Designing for Graceful Degradation
- A Practical Roadmap to Designing for Scale
At Logiciel Solutions, we work with enterprises on cloud architecture for scale, bottleneck analysis, load testing, and operational maturity. Our reference patterns come from production systems built to scale.
Explore taking cloud architecture for scale from strategy to production with an engineering partner.
Frequently Asked Questions
What is cloud architecture for scale?
Designing systems that handle growth, in traffic, data, and teams, without breaking or requiring a rebuild: stateless services, horizontal scaling, partitioned data, async processing where it helps. Production-grade scaling means those properties actually hold under real load, which depends on details the high-level design glosses over.
Why doesn't a scalable diagram guarantee scaling?
Because the diagram is a claim, not a proof. Systems that look scalable routinely fall over under real load due to a bottleneck the diagram ignored, the database, a stateful component, a dependency that did not scale with the rest. Scaling is proven under load and lives in the details, not in the picture.
Where do systems usually break first under load?
Often the data tier (a database that does not partition or a hot shard) and shared state (a stateful component that cannot scale horizontally). Fixing the first bottleneck matters most, because scaling everything else is moot if one tier caps the whole system. Finding that bottleneck is a core part of the work.
Why load-test to reach production?
Because scaling is demonstrated only under load. Load-testing to the target scale and beyond reveals the bottlenecks and proves the system holds, rather than trusting the design. A diagram does not survive contact with traffic; a load test shows whether the system actually scales before real users find out it does not.
Where does an engineering partner add value?
A partner has built systems that scaled and debugged ones that did not, so they know where scaling breaks, can scope the gap honestly, and prove scaling under load instead of trusting the diagram. They build the operational maturity scaling requires and transfer the capability to operate at scale, rather than creating a dependency.

