There is a Spark workload in your organization running on a self-managed cluster that someone stands up, tunes, patches, and babysits, because that is how the team has always run Spark. Nobody has asked whether AWS Glue's managed, serverless model would remove most of that operational burden, or whether Glue's constraints and cost model would actually fit the workload better. The choice is a habit, and the operational tax of that habit is paid every week.
This is more than an operational preference. It is a choice between managed and self-managed Spark made without weighing the real tradeoffs.
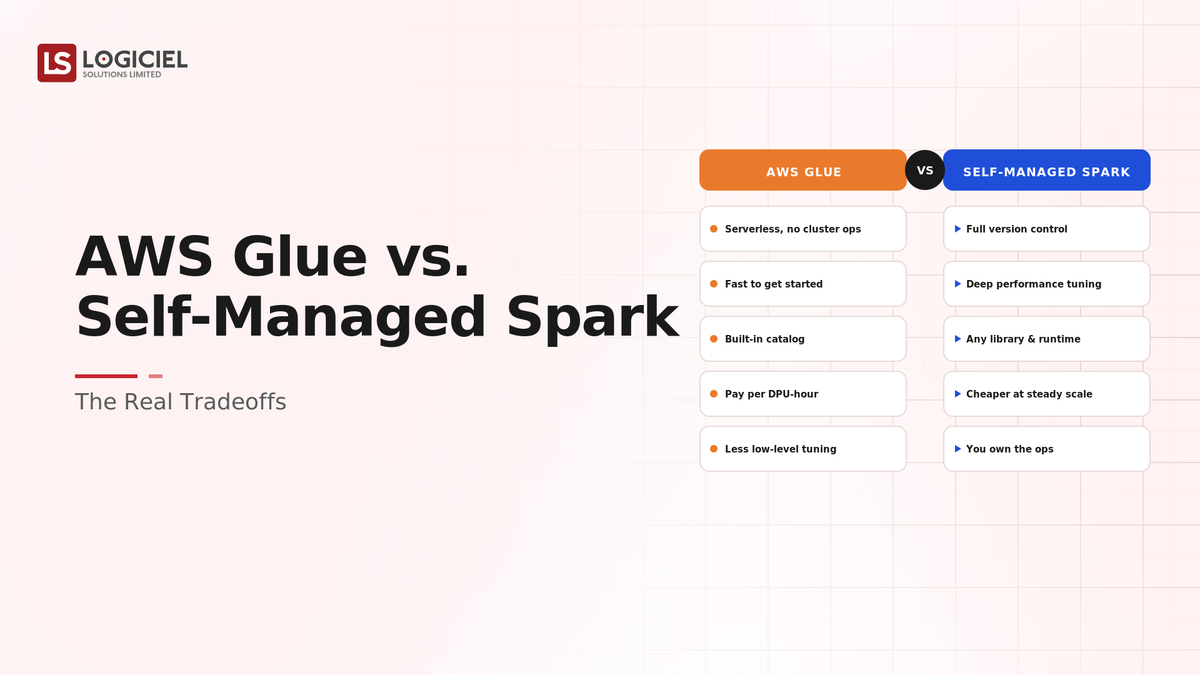
AWS Glue and self-managed Spark both run Spark workloads, but they trade differently: Glue is serverless and managed, removing cluster operations at the cost of some control and a particular cost model, while self-managed Spark offers full control and tuning at the cost of running the cluster yourself. The right choice depends on the workload, the team's operational capacity, and cost at real scale.
However, many teams run self-managed Spark by default, or adopt Glue assuming managed always wins, without matching the choice to their workload and operational reality.
If you are a data or platform leader running Spark workloads, the intent of this article is:
- Define what Glue and self-managed Spark each offer
- Walk through the real tradeoffs in control, cost, and operations
- Lay out how to choose for your workload
To do that, let's start with the basics.
Healthcare Platform Shifted From Batch to Streaming
A streaming migration playbook for Data Engineering Leads moving healthcare workloads to real-time.
What Are AWS Glue and Self-Managed Spark? The Basic Definition
At a high level, AWS Glue is a serverless, managed Spark service that runs jobs without you provisioning or operating a cluster, while self-managed Spark means running Spark yourself, on EMR, EKS, or EC2, with full control over configuration, tuning, and the cluster lifecycle.
To compare:
If self-managed Spark is owning and maintaining your own vehicle fleet, Glue is a ride service that handles the vehicles and drivers. One gives full control and can be cheaper if you run it well; the other removes the operational burden at the cost of some control and a different cost model.
Why Is This Choice Necessary to Weigh?
Issues that weighing the choice addresses or resolves:
- Matching the operational model to the team's capacity
- Choosing the cost model that fits the workload at real scale
- Deciding deliberately rather than by habit or assumption
Resolved Issues by Weighing the Tradeoffs
- Aligns operational burden with team capacity
- Matches the cost model to the workload pattern
- Replaces habit with a workload-based decision
Core Components of the Decision
- Operational burden: managed serverless versus self-run cluster
- Control and tuning needs
- Cost model and cost at real scale
- Workload pattern: sporadic versus steady
- The team's operational capacity and preference
Modern Spark Options on AWS
- AWS Glue for serverless, managed Spark jobs
- EMR for managed-but-tunable Spark clusters
- Spark on EKS for containerized, controlled Spark
- Self-managed Spark on EC2 for full control
- A spectrum from fully managed to fully self-run

These options span control versus operational burden; the choice follows the workload and the team.
Other Core Issues They Will Solve
- Reduce or retain operational overhead per the team's capacity
- Match cost to sporadic or steady workload patterns
- Provide the control needed for unusual tuning requirements
Importance of the Choice in 2026
Choosing the right Spark model matters more as data workloads and cost scrutiny grow. Four reasons explain why it matters now.
1. Operational burden is a real cost.
Running Spark clusters, provisioning, tuning, patching, costs engineering time. Glue removes much of it, which matters when that time is scarce.
2. Cost models favor different patterns.
Glue's serverless model fits sporadic workloads; a well-run self-managed cluster can be cheaper for steady, heavy ones. The pattern decides.
3. Managed does not always win.
Assuming managed is always better ignores that self-managed offers control and can be cheaper at steady scale. The tradeoff is real both ways.
4. Habit leaves value on the table.
Running self-managed by default, or adopting Glue by assumption, both miss the chance to match the model to the workload.
Traditional vs. Modern Spark Operations
- Self-managed by default vs. model matched to workload
- Operate the cluster yourself vs. serverless where it fits
- Cost by assumption vs. cost modeled at real scale
- One model everywhere vs. the right model per workload
In summary: A modern Spark choice matches the operational and cost model to the workload pattern and the team's capacity, rather than defaulting.
Details About the Decision Factors: What Are You Comparing?
Let's go through each factor.
1. Operational Layer
Who runs the cluster.
Operational factors:
- Glue: serverless, no cluster operations
- Self-managed: you provision, tune, and patch
- The team's capacity to operate weighed
2. Control Layer
How much you can tune.
Control factors:
- Self-managed: full control over configuration and tuning
- Glue: managed, with constraints on control
- Unusual tuning needs favor self-managed
3. Cost Layer
What each costs at real scale.
Cost factors:
- Glue: pay-per-use, fitting sporadic workloads
- Self-managed: can be cheaper for steady, heavy use if run well
- Cost modeled at the workload's real pattern
4. Workload Pattern Layer
How the workload behaves.
Pattern factors:
- Sporadic, bursty jobs fit Glue's serverless model
- Steady, heavy workloads can suit a self-managed cluster
- The pattern characterized honestly
5. Decision Layer
How the choice is made.
Decision choices:
- Operational capacity, control needs, and cost weighed
- The fitting model chosen per workload
- Revisited as workloads change
Benefits Gained from Matching the Model to the Workload
- Operational burden aligned with the team's capacity
- Cost matched to the workload pattern
- Control where the workload genuinely needs it
How It All Works Together
You characterize the workload, sporadic or steady, light or heavy, and unusual in tuning needs or not, and assess the team's operational capacity. If the workload is sporadic and the team values removing cluster operations, Glue's serverless, managed model fits, paying per use without babysitting a cluster. If the workload is steady and heavy, or needs unusual tuning, a well-run self-managed cluster on EMR, EKS, or EC2 may be cheaper and more controllable. Cost is modeled at the workload's real pattern rather than assumed. The model is chosen per workload and revisited as it changes, rather than run by habit.
Common Misconception
Managed services like Glue are always the better choice over self-managed Spark.
Glue removes operational burden, which is valuable, but at the cost of some control and a serverless cost model that fits some workloads better than others. A well-run self-managed cluster can be cheaper for steady, heavy workloads and offers full control. Managed wins often, but not always.
Key Takeaway: The choice is a tradeoff between operational burden and control and cost, decided by the workload, not a blanket preference for managed.
Real-World Spark Model Selection in Action
Let's take a look at how a deliberate choice operates with a real-world example.
We worked with a team running self-managed Spark by habit, with these constraints:
- Match the operational model to the team's capacity
- Choose the cost model that fit the workload
- Decide deliberately, not by habit
Step 1: Characterize the Workloads
Understand how they behave.
- Sporadic versus steady patterns identified
- Light versus heavy assessed
- Unusual tuning needs noted
Step 2: Assess Operational Capacity
Weigh the burden of self-managing.
- Time spent operating clusters measured
- Team capacity assessed
- Value of removing the burden estimated
Step 3: Model Cost at Real Scale
Compare the cost models on the actual pattern.
- Glue pay-per-use estimated for the pattern
- Self-managed cost at steady scale estimated
- Cost compared, not assumed
Step 4: Choose per Workload
Match the model to each workload.
- Glue for sporadic, operations-light needs
- Self-managed for steady, heavy, or control-heavy needs
- Decision matched, not defaulted
Step 5: Revisit as Workloads Change
Keep the choice current.
- Patterns reassessed over time
- Model changed if the workload changes
- Cost re-modeled periodically
Where It Works Well
- The model matched to workload pattern and operational capacity
- Cost modeled at the workload's real scale
- Control retained where the workload needs it
Where It Does Not Work Well
- Running self-managed by habit when Glue would remove the burden
- Adopting Glue assuming managed always wins, ignoring cost at steady scale
- Choosing without modeling cost at the real pattern
Key Takeaway: The right Spark model is the one matched to the workload's pattern, the team's operational capacity, and cost at real scale, not the habitual self-managed cluster or the assumption that managed always wins.
Common Pitfalls
i) Self-managing by habit
Running clusters because that is how it has always been done pays an operational tax that Glue might remove. Reassess against the workload.
- Measure the operational burden
- Compare to Glue's managed model
- Choose the fit
ii) Assuming managed always wins
Glue is not always cheaper or sufficient. Steady, heavy workloads can be cheaper self-managed, and some need control Glue constrains.
iii) Not modeling cost at real scale
Glue's pay-per-use and a self-managed cluster's cost behave differently per pattern. Model cost on the actual workload, not by assumption.
iv) One model for everything
Different workloads have different patterns. Forcing one model across all of them mismatches some.
Takeaway from these lessons: Most Spark-model regret traces to habit and assumption, not to either option. Characterize the workload, model cost, and choose per workload.
Spark Model Best Practices: What High-Performing Teams Do Differently
1. Characterize the workload first
Sporadic or steady, light or heavy, ordinary or unusual in tuning, drives the choice. Assess it before deciding.
2. Weigh operational capacity honestly
Glue's removal of cluster operations is valuable when engineering time is scarce. Self-managing has a real, recurring cost.
3. Model cost at the real pattern
Glue's pay-per-use fits sporadic; self-managed can be cheaper steady. Model cost on the actual workload, not by assumption.
4. Retain control where needed
Workloads with unusual tuning needs favor self-managed. Do not give up control the workload genuinely requires.
5. Choose per workload and revisit
Different workloads warrant different models, and patterns change. Match each and reassess over time.
Logiciel's value add is helping teams characterize Spark workloads, weigh operational capacity, and model cost at real scale, so the choice between Glue and self-managed Spark fits the workload rather than following habit or assumption.
Takeaway for High-Performing Teams: Focus on the workload pattern, operational capacity, and real-scale cost. Glue removes operational burden and fits sporadic workloads; self-managed offers control and can be cheaper steady; the work is matching the model to the workload.
Signals You Are Choosing the Spark Model Correctly
How do you know the choice is sound? Not in which option you run, but in the fit to the workload. Below are the signals that distinguish a deliberate choice from a habit.
The choice matches the pattern. The team can explain the model choice in terms of the workload's pattern and operational needs.
Operational burden fits capacity. The team is not babysitting clusters it lacks the capacity to run, nor paying for management it does not need.
Cost was modeled. The team compared Glue and self-managed cost on the actual workload pattern, not by assumption.
Control matches need. Workloads with unusual tuning needs are self-managed; ordinary ones use the managed model.
The choice is revisited. The team reassesses as workloads and patterns change.
Adjacent Capabilities and Connected Work
This work does not exist in isolation. The Spark-model choice depends on, and feeds into, several adjacent capabilities. Building one without thinking about the others is the most common scoping mistake.
In most enterprise programs, Spark workloads share infrastructure with the data platform, the orchestration layer, and the cost-management process. They share team capacity with data engineering, platform engineering, and the analysts consuming the outputs. And they share leadership attention with whatever the next data initiative is on the roadmap. Naming these adjacencies upfront helps the program scope realistically and helps leadership see the work as a portfolio rather than a one-off project.
The most common mistake in adjacent-capability scoping is treating each adjacency as someone else's problem. The orchestration that triggers Spark jobs is your problem. The cost monitoring that proves the model fits is your problem. The data the jobs process is your problem. Pretending otherwise pushes work to teams that did not plan for it, and the work returns to you later as an operational tax or a surprising bill. Own the adjacencies you depend on; partner with the teams that own them; share the timeline.
Conclusion
AWS Glue and self-managed Spark trade operational burden against control and cost, and the right choice matches the workload's pattern, the team's capacity, and cost at real scale. The discipline that produces the right choice is the same discipline behind any tooling decision: characterize the workload, weigh the tradeoffs, and choose deliberately.
Key Takeaways:
- Glue is serverless and managed; self-managed Spark offers control and tuning
- Glue fits sporadic workloads; self-managed can be cheaper for steady, heavy ones
- Match the model to the workload pattern, operational capacity, and real-scale cost
Choosing well requires workload, operational, and cost discipline. When done correctly, it produces:
- Operational burden aligned with the team's capacity
- Cost matched to the workload pattern
- Control where the workload needs it
- A choice revisited as workloads change
Real Estate SaaS Reduced AWS Costs 38%
An AWS cost optimization playbook for FinOps Leads who need durable savings, not one-time wins.
What Logiciel Does Here
If you run Spark by habit, characterize your workloads, weigh the operational burden, and model cost at real scale to choose between Glue and self-managed Spark deliberately.
Learn More Here:
- AWS Data Pipelines: Glue, EMR, MSK, and When to Use Each
- AWS Data Platform Services
- Streaming vs. Micro-Batch: Choosing Your Latency Tier
At Logiciel Solutions, we work with data and platform leaders on Spark architecture, Glue adoption, and data processing cost. Our reference patterns come from production Spark workloads on AWS.
Explore the real tradeoffs between AWSGlue and self-managed Spark for your workloads.
Frequently Asked Questions
What is the difference between AWS Glue and self-managed Spark?
AWS Glue is a serverless, managed Spark service that runs jobs without you operating a cluster, while self-managed Spark, on EMR, EKS, or EC2, means running Spark yourself with full control over configuration, tuning, and the cluster lifecycle. Glue trades control for removed operational burden.
Is Glue always cheaper than self-managed Spark?
No. Glue's pay-per-use model fits sporadic, bursty workloads, but a well-run self-managed cluster can be cheaper for steady, heavy workloads. Cost depends on the workload pattern, so model it on your actual usage rather than assuming.
When should I choose self-managed Spark?
When the workload is steady and heavy enough that a well-run cluster is cheaper, or when you need control and tuning that Glue's managed model constrains, and your team has the operational capacity to run the cluster well.
When should I choose Glue?
When the workload is sporadic or bursty, when removing cluster operations is valuable because engineering time is scarce, and when Glue's managed model and constraints fit the workload. It removes provisioning, tuning, and patching burden.
What is the biggest mistake in choosing a Spark model?
Choosing by habit, running self-managed because that is how it has always been done, or adopting Glue assuming managed always wins. Both miss the tradeoff. Characterize the workload pattern, model cost at real scale, weigh operational capacity, and choose per workload.