

"We'll monitor the LLM" is on every production AI plan, and very few teams have monitoring that would actually catch their LLM producing confident wrong answers. That is the gap. Monitoring an LLM's output quality, not just its latency and cost, is genuinely hard, evaluating whether a fluent answer is correct is a different problem than reading a metrics dashboard, and it is exactly where the strategy glosses over the work. An engineering partner shortens the crossing by having built LLM output monitoring before.
LLM monitoring in production means watching the things that signal an LLM is failing: hallucination, quality degradation, drift, unsafe outputs, and cost, especially the output-quality signals traditional monitoring misses. Taking it from strategy to production is building the capability to detect a wrong-but-confident model in real traffic. A partner with production LLM monitoring experience knows what to build and what the strategy left out.
Energy Operator Built Real-Time Grid Signal Pipeline
A real-time grid pipeline playbook for Heads of Data Platform.
The Gap Between Strategy and Production
The strategy says monitor the LLM. Production is the system that actually detects LLM failures: capturing inputs and outputs, evaluating output quality (automated checks, sampled review, user feedback), detecting hallucination and drift, alerting on quality degradation, and connecting to a response. The gap is wide because LLM failures are semantic, a fluent wrong answer, not a crash, so monitoring them requires evaluating correctness, which is harder than infrastructure monitoring and is the part the strategy assumes away.
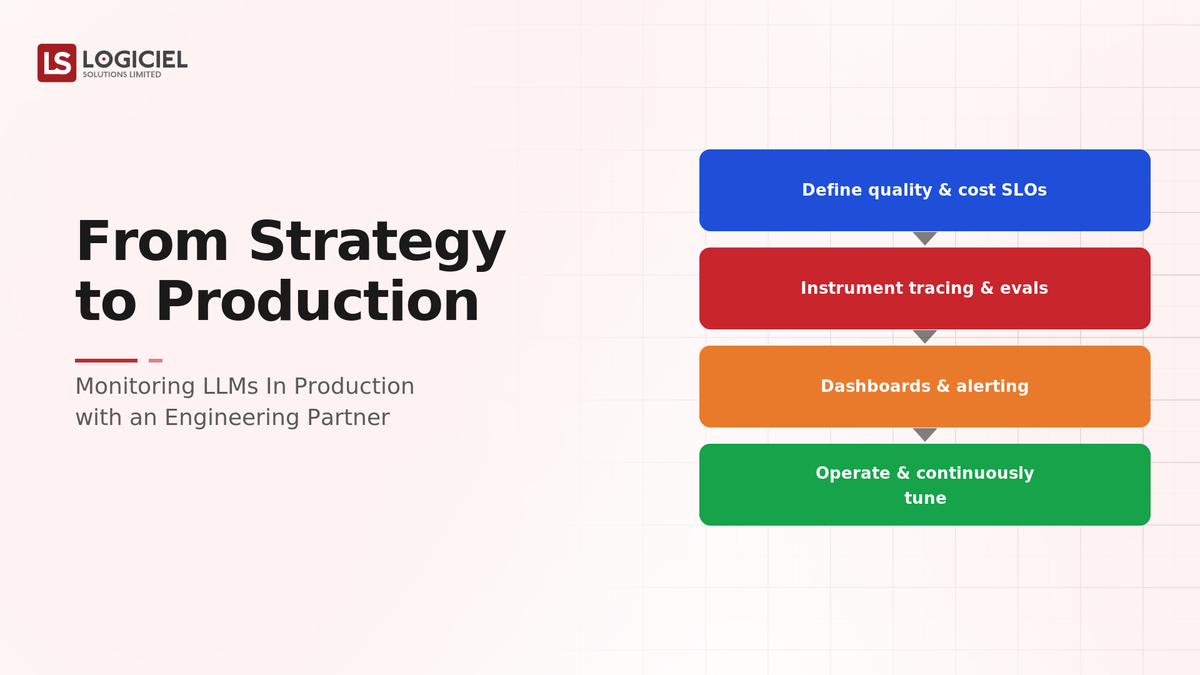
The Path From Strategy to Production
- Translate "monitor the LLM" into specific signals. Define what failure looks like for your LLM, hallucination, off-policy outputs, quality drop, and the signals that detect each. Vague intent becomes concrete monitoring.
- Instrument capture of inputs and outputs. You cannot evaluate output quality you did not record. Capture prompts and responses (with privacy care) as the foundation.
- Build output-quality evaluation. Combine automated checks, sampled human review, and user feedback to detect wrong or low-quality outputs, the hard, central capability.
- Add drift and safety monitoring. Watch for quality degrading over time and unsafe outputs, the failures that look healthy to infrastructure monitoring.
- Connect monitoring to response. Define what happens on detected degradation: adjust prompts, tighten guardrails, change or roll back the model.
- Transfer ownership. Leave the team able to run and evolve the LLM monitoring, not dependent on the partner.
Where an Engineering Partner Adds Value
A partner has built LLM output-quality monitoring before, so they know the signals that matter, how to evaluate fluent-but-wrong outputs, and what the strategy glossed over. They shorten the crossing from "we'll monitor it" to a system that catches real failures, scope the hard evaluation work honestly, and transfer the capability rather than creating a dependency.
Common Misconception
The misconception that leaves LLMs unmonitored: monitoring an LLM is like monitoring any other service.
It is not. Other services fail by crashing or erroring; LLMs fail by producing fluent, confident, wrong outputs while every infrastructure metric looks fine. Monitoring an LLM requires evaluating output quality, a semantic problem, not reading latency and error graphs. Treating LLM monitoring as standard service monitoring means building something that watches the wrong thing and misses the failures that matter.
Key Takeaway: LLM monitoring's hard part is evaluating output quality, since LLMs fail by being confidently wrong while looking healthy. The strategy-to-production gap is building that evaluation, where a partner with experience helps most.
Where the Journey Goes Right
- "Monitor the LLM" translated into specific failure signals
- Output-quality evaluation built, plus drift and safety monitoring
- Monitoring connected to response, ownership transferred
Where It Goes Wrong
- Monitoring infrastructure while the model hallucinates
- Treating LLM monitoring as standard service monitoring
- Detecting nothing actionable, with no response path
Key Takeaway: LLM monitoring reaches production when output-quality evaluation is built and connected to response, not when "we'll monitor it" is assumed to mean infrastructure metrics.
What High-Performing Teams Do Differently
- Translate monitoring intent into specific failure signals.
- Capture inputs and outputs as the foundation.
- Build output-quality evaluation, the hard central capability.
- Add drift and safety monitoring and a response path.
- Use a partner's experience and transfer ownership.
Logiciel's value add is helping teams take LLM monitoring from strategy to production, translating intent into signals, building output-quality evaluation, drift and safety monitoring, and response, with the experience of having built LLM monitoring before.
Takeaway for High-Performing Teams: Respect the gap between "we'll monitor the LLM" and a system that catches confident wrong answers. The hard part is output-quality evaluation, so build that, connect it to response, and use a partner's experience to cross faster.
Adjacent Capabilities and Connected Work
LLM monitoring shares infrastructure with the model serving stack, the prompt and guardrail layer, and the incident process, and shares team capacity with applied ML, platform engineering, and product. The common scoping mistake is treating each adjacency as someone else's problem: the output capture is your problem, the quality evaluation is your problem, the response path is your problem. Pretending otherwise returns later as a hallucinating model users acted on. Own the adjacencies, partner with the teams that own them, share the timeline.
Conclusion
Taking LLM monitoring from strategy to production is closing the gap between "we'll monitor the LLM" and a system that actually detects confident wrong answers, built on capturing outputs, evaluating output quality, detecting drift and unsafe outputs, and connecting to response. The hard part, evaluating fluent-but-wrong outputs, is what the strategy glosses over, and an engineering partner with production LLM monitoring experience shortens the crossing.
Key Takeaways:
- LLMs fail by being confidently wrong while infrastructure looks healthy
- The hard part is output-quality evaluation, which the strategy assumes away
- A partner with LLM monitoring experience shortens the crossing and transfers ownership
CISO Redesigned Cloud Security Without Slowing Delivery
A cloud security architecture playbook for CISOs balancing security and engineering velocity.
What Logiciel Does Here
If "we'll monitor the LLM" is in your plan but you could not catch a confident wrong answer, build the real thing: output capture, quality evaluation, drift and safety monitoring, and response.
Learn More Here:
- A Practical Roadmap to Monitoring LLMs in Production
- AI Model Monitoring in Production: Drift, Decay, and What to Do About It
- Hallucination Mitigation: Concepts, Benefits, and Trade-offs
At Logiciel Solutions, we work with teams on taking LLM monitoring to production, output-quality evaluation, drift and safety monitoring, and response. Our reference patterns come from production LLM systems.
Explore taking LLM monitoring from strategy to production with an engineering partner.
Frequently Asked Questions
Why is monitoring an LLM harder than monitoring other services?
Because other services fail by crashing or erroring, which infrastructure monitoring catches, while LLMs fail by producing fluent, confident, wrong outputs while latency, errors, and cost all look fine. Monitoring an LLM requires evaluating output quality, a semantic problem, which is much harder than reading a metrics dashboard and is what the strategy tends to assume away.
What is the gap between strategy and production here?
The strategy says "monitor the LLM"; production is the system that actually detects LLM failures, capturing inputs and outputs, evaluating output quality, detecting hallucination and drift, alerting, and connecting to response. The gap is the output-quality evaluation work, which is hard and central, and which the strategy glosses over by assuming monitoring means infrastructure metrics.
How do you evaluate LLM output quality in production?
With a combination of automated quality checks, sampled human review, and user feedback signals (corrections, rejections), all built on capturing inputs and outputs first. These detect wrong or low-quality outputs that infrastructure metrics miss. Building this evaluation capability is the hard, central part of taking LLM monitoring to production.
What failures should LLM monitoring catch?
Hallucination (confident wrong answers), quality degradation and drift over time, and unsafe or off-policy outputs, all of which look healthy to infrastructure monitoring because there is no crash or error. Catching these, and connecting detection to a response (prompt changes, guardrails, model rollback), is what makes LLM monitoring actually protective.
Where does an engineering partner help?
A partner who has built LLM output-quality monitoring knows the signals that matter, how to evaluate fluent-but-wrong outputs, and what the strategy left out. They shorten the crossing from intent to a working system, scope the hard evaluation work honestly, and transfer the capability so the team can run and evolve the monitoring itself.

