There is a retrieval-augmented generation feature on your roadmap, and the team is debating whether to build the whole pipeline, chunking, embedding, a vector store, retrieval, or to use Amazon Bedrock Knowledge Bases and have most of it managed. The debate is happening in the abstract, without anyone having mapped the feature's actual retrieval needs against what the managed service does and does not do. The decision will be made on impression, and the limits will be discovered after commitment.
This is more than a build-versus-buy question. It is a decision about managed RAG made without knowing where the managed option's limits are.
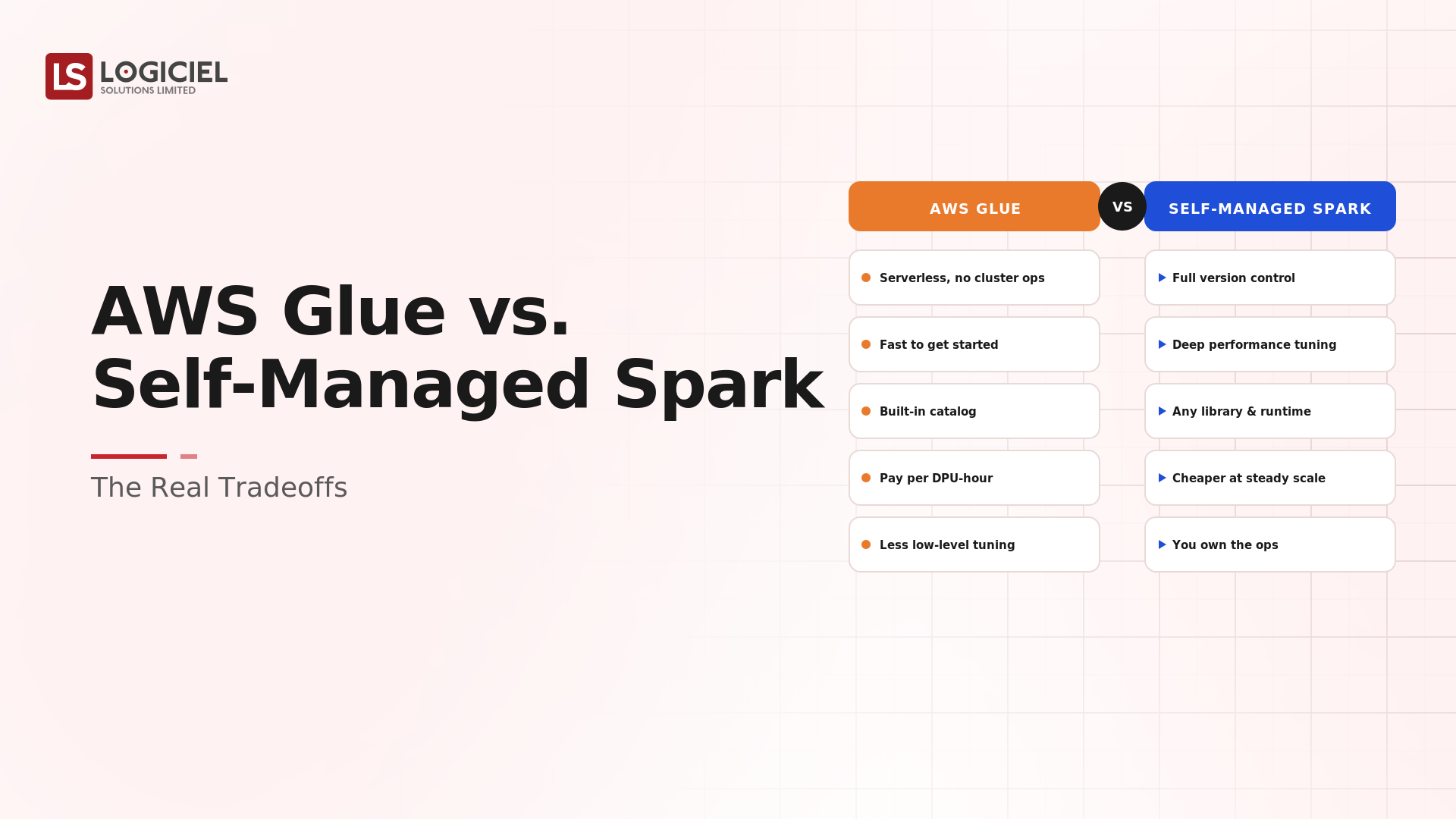
Bedrock Knowledge Bases provide managed RAG: they handle ingestion, chunking, embedding, vector storage, and retrieval, so you can add grounded generation without building the pipeline. That removes real effort, and it comes with limits, on chunking control, retrieval tuning, and customization, that matter for some use cases and not others. Knowing where those limits bind is the whole decision.
However, many teams either build a custom pipeline when the managed service would serve, or adopt the managed service and hit its limits mid-build, because they did not map the use case against the constraints first.
If you are an AI or platform leader building RAG on AWS, the intent of this article is:
- Define what Bedrock Knowledge Bases manage and what they do not
- Walk through where the managed service fits and where its limits bind
- Lay out how to decide for your use case
To do that, let's start with the basics.
CTO Consolidated Six Observability Tools Into One
An observability consolidation playbook for CTOs paying the observability tax.
What Are Bedrock Knowledge Bases? The Basic Definition
At a high level, Amazon Bedrock Knowledge Bases are a managed RAG capability that ingests your documents, chunks and embeds them, stores the vectors, and handles retrieval at query time, so a model can answer grounded in your data without you building the retrieval pipeline.
To compare:
If a custom RAG pipeline is assembling your own kitchen from individual appliances, Bedrock Knowledge Bases are a fitted kitchen that works out of the box. It saves enormous setup, and you accept its layout: where it shines is the common case, and where it limits you is the unusual requirement.
Why Is Knowing the Limits Necessary?
Issues that knowing the limits addresses or resolves:
- Avoiding building a custom pipeline when the managed one would serve
- Avoiding hitting the managed service's limits mid-build
- Matching the RAG approach to the use case's real needs
Resolved Issues by Knowing the Limits
- Captures the managed service's effort savings where it fits
- Identifies upfront the use cases that need a custom pipeline
- Replaces impression-based decisions with requirement-based ones
Core Components of the Decision
- What the managed service handles: ingestion, chunking, embedding, retrieval
- The limits: chunking control, retrieval tuning, customization
- The use case's retrieval requirements
- Effort saved versus control needed
- A hybrid where the managed service covers part
Modern RAG Options on AWS
- Bedrock Knowledge Bases for managed RAG
- Custom pipelines with your own vector store and retrieval
- OpenSearch and vector databases for custom retrieval
- Embedding models via Bedrock or elsewhere
- Hybrid approaches mixing managed and custom
These options span managed to fully custom; the choice follows the use case's retrieval needs.
Other Core Issues They Will Solve
- Provide grounded generation without pipeline-building effort
- Reduce time to a working RAG feature
- Offload retrieval operations to a managed service
Importance of the Decision in 2026
Choosing the right RAG approach matters more as grounded generation becomes standard. Four reasons explain why it matters now.
1. RAG is now a default pattern.
Grounding generation in enterprise data is the common way to make LLMs useful. The pipeline-versus-managed choice comes up constantly.
2. Managed RAG saves real effort.
Building chunking, embedding, vector storage, and retrieval is significant work. Bedrock Knowledge Bases remove most of it where they fit.
3. Retrieval quality depends on control.
Some use cases need fine control over chunking and retrieval to get quality answers. The managed service's limits bind exactly there.
4. Hitting limits mid-build is costly.
Adopting the managed service and discovering a binding limit halfway through forces a rebuild. Knowing the limits first avoids it.
Traditional vs. Modern RAG Decisions
- Build the whole pipeline by default vs. use managed where it fits
- Decide by impression vs. map use case against limits
- All-managed or all-custom vs. hybrid where appropriate
- Discover limits mid-build vs. know them upfront
In summary: A modern RAG decision maps the use case's retrieval needs against the managed service's limits, using managed where it fits and custom where the limits bind.

Details About the Decision Factors: What Are You Evaluating?
Let's go through each factor.
1. Managed Scope Layer
What the service handles.
Scope factors:
- Ingestion, chunking, embedding, vector storage, retrieval
- Out-of-the-box grounded generation
- Effort removed from the common case
2. Limits Layer
Where the service constrains.
Limits factors:
- Control over chunking strategy
- Retrieval tuning and ranking customization
- Customization of the pipeline's behavior
3. Use Case Layer
What the feature needs.
Use case factors:
- Retrieval quality requirements
- Whether default chunking and retrieval suffice
- Unusual data or query characteristics
4. Effort versus Control Layer
The core trade.
Trade factors:
- Effort saved by the managed service
- Control needed by the use case
- Where the balance falls
5. Hybrid Layer
Mixing managed and custom.
Hybrid factors:
- Managed for the parts it fits
- Custom for the parts that need control
- A blended approach where it pays
Benefits Gained from Mapping Use Case to Limits
- The managed service used where it saves effort
- Custom pipelines reserved for use cases that need control
- Limits known upfront, avoiding a mid-build rebuild
How It All Works Together
You map the use case's retrieval requirements, how much retrieval quality depends on chunking strategy and retrieval tuning, against what Bedrock Knowledge Bases manage and where they limit. If default chunking and retrieval produce good answers for the use case, the managed service removes the pipeline-building effort and is the right choice. If the use case needs fine control over chunking, custom retrieval ranking, or unusual handling that the managed service constrains, a custom pipeline, or a hybrid using managed for part, fits better. Because the limits were mapped upfront, you adopt the managed service knowing it will hold, or build custom knowing why, rather than discovering a binding limit halfway through.
Common Misconception
Managed RAG like Bedrock Knowledge Bases can replace any custom retrieval pipeline.
Managed RAG handles the common case well and removes real effort, but it limits control over chunking, retrieval tuning, and customization. Use cases that depend on that control for retrieval quality need a custom or hybrid pipeline. The managed service fits many cases and binds on some.
Key Takeaway: Managed RAG is excellent where its defaults produce good answers and limiting where retrieval quality depends on control. Knowing which your use case is, before committing, is the whole decision.
Real-World Managed RAG Decision in Action
Let's take a look at how the decision operates with a real-world example.
We worked with a team deciding between Bedrock Knowledge Bases and a custom RAG pipeline, with these constraints:
- Use the managed service where it would save effort
- Identify upfront whether its limits would bind
- Avoid a mid-build rebuild
Step 1: Map the Retrieval Requirements
Understand what the feature needs.
- Retrieval quality requirements defined
- Dependence on chunking and tuning assessed
- Unusual data or query characteristics noted
Step 2: Map Against the Limits
Check where the managed service constrains.
- Chunking control needs versus managed defaults
- Retrieval tuning needs versus managed capabilities
- Customization needs assessed
Step 3: Weigh Effort versus Control
Find where the balance falls.
- Effort the managed service saves
- Control the use case requires
- The trade evaluated
Step 4: Choose Managed, Custom, or Hybrid
Match the approach to the use case.
- Managed where defaults suffice
- Custom where control is essential
- Hybrid where managed covers part
Step 5: Validate Retrieval Quality
Confirm the choice produces good answers.
- Retrieval quality evaluated on real queries
- Limits confirmed not to bind, or custom built
- Approach adjusted if quality falls short
Where It Works Well
- The managed service used where its defaults produce good answers
- Custom or hybrid where retrieval quality needs control
- Limits mapped upfront, avoiding a mid-build rebuild
Where It Does Not Work Well
- Building a custom pipeline when managed would serve
- Adopting managed and hitting a binding limit mid-build
- Deciding by impression without mapping the use case
Key Takeaway: The right RAG approach is the one matched to the use case's retrieval needs and the managed service's limits, known upfront, not the default custom build or the managed service adopted on impression.
Common Pitfalls
i) Building custom by default
Assembling a full pipeline when the managed service would serve wastes effort. Check whether managed defaults produce good answers first.
- Map the use case
- Test managed defaults
- Build custom only where needed
ii) Hitting limits mid-build
Adopting the managed service without mapping its limits leads to a binding constraint discovered halfway through. Map limits upfront.
iii) Deciding by impression
Choosing managed or custom on a general impression rather than the use case's retrieval needs leads to mismatch. Evaluate against requirements.
iv) Ignoring the hybrid option
It is not always all-or-nothing. A hybrid using managed for part and custom for the controlled part may fit best.
Takeaway from these lessons: Most RAG-approach regret traces to not mapping the use case against the limits, not to either option. Map requirements to limits and choose managed, custom, or hybrid.
Managed RAG Best Practices: What High-Performing Teams Do Differently
1. Map the use case against the limits first
Know where the managed service's limits on chunking, retrieval, and customization fall, and whether your use case needs control there.
2. Test managed defaults on real queries
Evaluate whether the managed service's default chunking and retrieval produce good answers for your data before building anything custom.
3. Reserve custom for use cases that need control
Build a custom pipeline where retrieval quality genuinely depends on chunking or tuning control the managed service constrains.
4. Consider a hybrid
Use the managed service for the parts it fits and custom for the parts that need control, rather than all-or-nothing.
5. Validate retrieval quality
Whatever the choice, evaluate retrieval quality on real queries, since that, not the architecture, is what determines a useful RAG feature.
Logiciel'svalue add is helping teams map RAG use cases against the managed service's limits, test retrieval quality, and choose managed, custom, or hybrid, so the approach fits the use case rather than being chosen on impression.
Takeaway for High-Performing Teams: Focus on mapping the use case against the limits. Bedrock Knowledge Bases save real effort where their defaults produce good answers, and bind where retrieval quality needs control; knowing which, upfront, is the decision.
Signals You Are Deciding on Managed RAG Correctly
How do you know the choice is sound? Not in whether you used the managed service, but in the fit to the use case. Below are the signals that distinguish a mapped decision from an impression.
The limits were mapped. The team can state where the managed service's limits fall and whether the use case needs control there.
Defaults were tested. The team evaluated the managed service's default retrieval quality on real queries before committing.
The approach matches the need. The team uses managed where defaults suffice and custom or hybrid where control is essential.
No mid-build surprise. The team adopted the managed service knowing it would hold, or built custom knowing why, rather than hitting a limit halfway.
Retrieval quality is validated. The team evaluates answer quality on real queries, since that determines a useful feature.
Adjacent Capabilities and Connected Work
This work does not exist in isolation. The managed RAG decision depends on, and feeds into, several adjacent capabilities. Building one without thinking about the others is the most common scoping mistake.
In most enterprise programs, RAG shares infrastructure with the data and document pipeline, the model runtime, and the evaluation process. It shares team capacity with applied ML, data engineering, and the product teams using the feature. And it shares leadership attention with whatever the next AI initiative is on the roadmap. Naming these adjacencies upfront helps the program scope realistically and helps leadership see the work as a portfolio rather than a one-off project.
The most common mistake in adjacent-capability scoping is treating each adjacency as someone else's problem. The document pipeline feeding the knowledge base is your problem. The evaluation of retrieval quality is your problem. The data governance over the source documents is your problem. Pretending otherwise pushes work to teams that did not plan for it, and the work returns to you later as poor retrieval quality. Own the adjacencies you depend on; partner with the teams that own them; share the timeline.
Conclusion
Bedrock Knowledge Bases provide managed RAG that saves real effort where their defaults fit and limit control where some use cases need it. The discipline that produces the right choice is the same discipline behind any managed-versus-custom decision: map the requirements against the limits, and choose where the balance falls.
Key Takeaways:
- Bedrock Knowledge Bases manage ingestion, chunking, embedding, and retrieval
- They limit control over chunking, retrieval tuning, and customization
- Map the use case against the limits and choose managed, custom, or hybrid
Deciding on managed RAG well requires requirement, limit, and quality discipline. When done correctly, it produces:
- The managed service used where it saves effort
- Custom pipelines reserved for use cases needing control
- Limits known upfront, avoiding a mid-build rebuild
- Validated retrieval quality on real queries
Energy Platform Replatformed to Multi-Region Cloud
A migration playbook for VPs of Infrastructure responsible for resilience and regulatory geography.
What Logiciel Does Here
If you are choosing between managed and custom RAG, map your use case's retrieval needs against Bedrock Knowledge Bases' limits, test default quality on real queries, and choose managed, custom, or hybrid deliberately.
Learn More Here:
- RAG (Retrieval-Augmented Generation) Implementation
- RAG on AWS: A Production Architecture from Ingest to Response
- Embeddings at Scale: Storage, Refresh, and Versioning
At Logiciel Solutions, we work with AI and platform leaders on RAG architecture, Bedrock adoption, and retrieval quality. Our reference patterns come from production RAG systems.
Explore where Bedrock Knowledge Bases fit and where their limits mean building custom RAG.
Frequently Asked Questions
What do Bedrock Knowledge Bases do?
They provide managed RAG: ingesting your documents, chunking and embedding them, storing the vectors, and handling retrieval at query time, so a model can answer grounded in your data without you building the retrieval pipeline yourself.
What are the limits of Bedrock Knowledge Bases?
They constrain control over chunking strategy, retrieval tuning and ranking, and pipeline customization. Use cases whose retrieval quality depends on that control may find the managed defaults insufficient and need a custom or hybrid pipeline.
When should I build a custom RAG pipeline instead?
When retrieval quality genuinely depends on fine control over chunking, custom retrieval ranking, or unusual data and query handling that the managed service constrains. Map your use case against the limits to see whether they bind before committing.
Can I use a hybrid approach?
Yes. You can use Bedrock Knowledge Bases for the parts they fit and a custom pipeline for the parts that need control, rather than choosing all-managed or all-custom. A hybrid often captures the effort savings while retaining control where it matters.
What is the biggest mistake in choosing a RAG approach?
Deciding by impression rather than mapping the use case's retrieval needs against the managed service's limits. This leads either to building custom unnecessarily or to adopting the managed service and hitting a binding limit mid-build. Map requirements to limits and validate retrieval quality on real queries.