A clinical analytics dashboard shows yesterday's patient census as zero across every facility. The number is wrong, the upstream feed stalled at 2 a.m., and a care operations lead is asking why the morning staffing model ran on empty data. Your team is tracing the failure backward through six transformation steps while leadership waits.
This is more than an unusual incident. It is a failure of the concept of data reliability engineering.
A modern data reliability engineering practice is more than monitoring a few tables for nulls. It is a designed combination of data SLAs, freshness and quality checks, lineage, incident response, and ownership that lets the data platform fail loudly and recover predictably.
However, many teams ship pipelines before designing the reliability controls, and discover what they should have built when a bad number reaches a clinician.
If you are a Chief Data Officer and are responsible for the trustworthiness of data that drives clinical and operational decisions, the intent of this article is:
- Define what data reliability engineering actually is
- Walk through the controls that turn pipelines into dependable products
- Lay out how high-performing healthcare data teams operate reliability day to day
To do that, let's start with the basics.
What Got a CFO to Approve $2M in AI Spend
An AI business case template for CFOs who want ROI math before approving the next AI line item.
What Is Data Reliability Engineering? The Basic Definition
At a high level, data reliability engineering is the practice of applying software reliability discipline to data. You define what good looks like, measure it continuously, detect when it breaks, and recover with a documented process, the same way an SRE team treats uptime.
To compare:
If a software outage takes down a website everyone can see, a data outage silently poisons every report and model downstream. Both are failures; one is visible immediately, the other is discovered after decisions are already made.
Why Is Data Reliability Engineering Necessary?
Issues that Data Reliability Engineeringaddresses or resolves:
- Silent data failures that surface only after a wrong decision is made
- Pipelines with no owner, no SLA, and no defined recovery process
- Quality regressions that propagate through dozens of downstream consumers
Resolved Issues by Data Reliability Engineering
- Wraps pipelines in freshness, volume, and quality checks
- Adds lineage so failures can be traced and impact assessed
- Provides a structured incident process for data, not just systems
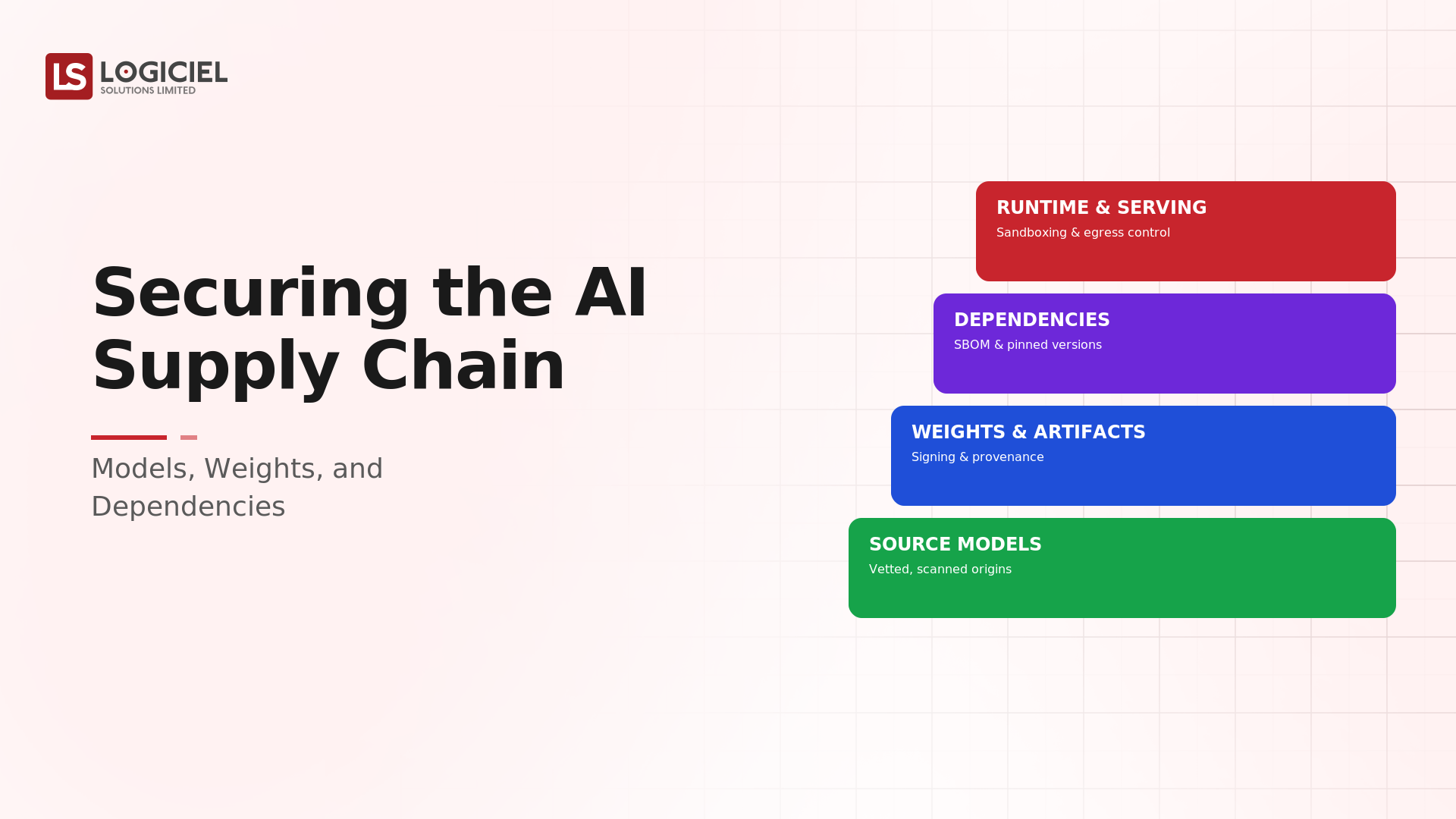
Core Components of Data Reliability Engineering
- Data SLAs and SLOs defining freshness, completeness, and accuracy targets
- Quality checks for schema, volume, distribution, and null rates
- Lineage and impact analysis across the pipeline graph
- Incident detection, alerting, and a documented response runbook
- Clear ownership for every dataset and pipeline
Modern Data Reliability Engineering Tools
- dbt tests and dbt Cloud for transformation-layer assertions
- Great Expectations and Soda for declarative data quality checks
- Monte Carlo, Bigeye, and Anomalo for data observability and anomaly detection
- OpenLineage and Marquez for lineage capture
- Airflow, Dagster, and Prefect for orchestration with built-in retries and SLAs
These tools reflect the maturation of data reliability from ad hoc null checks to production observability.
Other Core Issues They Will Solve
- Enable defensible reporting for regulators and auditors
- Provide impact analysis before a schema change ships
- Allow specialization across ingestion, transformation, and serving teams
In Summary: Data reliability engineering concepts turn a pipeline that sometimes works into a data product with a contract.
Importance of Data Reliability Engineering in 2026
Data engineering has moved from moving bytes to guaranteeing trust. Four reasons explain why it matters now.
1. Data now drives automated decisions, not just dashboards.
Staffing models, risk scores, and AI features act on data directly. A bad number is no longer a cosmetic dashboard issue. It is an automated decision made on a false premise.
2. The pipeline graph has grown too large to debug by hand.
Modern stacks have hundreds of interdependent tables. Without lineage and automated checks, tracing a failure is archaeology.
3. Regulators expect provenance.
In healthcare, the ability to show where a number came from and how it was transformed is a compliance requirement, not a nice-to-have.
4. AI features fail quietly on bad data.
Models trained or prompted on unreliable data degrade without an obvious error. Reliability at the data layer is now an AI quality control.
Traditional vs. Modern Data Reliability Engineering Concepts
- Manual null checks vs. declarative quality assertions in version control
- Tribal knowledge of pipelines vs. captured lineage and ownership
- Reactive firefighting vs. defined SLAs and incident runbooks
- Dashboard-era reporting vs. data products with measured contracts
In summary: Data reliability engineering concepts are the foundation of trustworthy automated decisions.
Details About the Core Components of Data Reliability Engineering: What Are You Designing?
Let's go through each layer.
1. SLA and SLO Layer
Where you define what good data means for each consumer.
SLA decisions:
- Freshness target per dataset, set by the consumer's need
- Completeness and accuracy thresholds
- Agreed consequence and escalation when an SLA is missed
2. Quality Check Layer
The assertions that run on data as it moves.
Quality check design:
- Schema and type checks at ingestion
- Volume and distribution checks to catch silent drops
- Null-rate and referential checks before serving
3. Lineage Layer
What depends on what, and how far a failure reaches.
Lineage choices:
- Column-level vs. table-level granularity
- Automated capture from the orchestration layer
- Impact analysis surfaced before schema changes
4. Detection and Alerting Layer
Where the platform notices a problem before a human does.
Detection checks:
- Threshold and anomaly-based alerts
- Routing to the dataset owner, not a shared inbox
- Severity tied to downstream blast radius
5. Incident Response Layer
The documented process for recovery and communication.
Response in production:
- Runbook per critical pipeline with rollback and backfill steps
- Status communication to affected consumers
- Postmortem capturing root cause and the check that would have caught it
Benefits Gained from SLA Discipline and Quality Checks
- Failures surface loudly and early instead of in a board report
- Defensible provenance for regulator and audit review
- Faster recovery when a pipeline breaks
How It All Works Together
Data arrives at ingestion and passes schema checks. Transformation steps run dbt tests at each layer. Quality assertions verify volume and distribution before serving. Lineage records what depends on the dataset. When a check fails, detection routes an alert to the owner, who follows the runbook to roll back or backfill. The postmortem adds the missing check. The contract holds.
Common Misconception
Data reliability is just adding more monitoring.
Data reliability is a system of contracts, checks, lineage, and response. Monitoring is the visible part; the SLA and the runbook are what make a failure recoverable.
Key Takeaway: Each layer has a specific job. Teams that skip the SLA and the runbook ship dashboards that look fine until they are quietly wrong.
Real-World Data Reliability Engineering in Action
Let's take a look at how data reliability engineering operates with a real-world example.
We worked with a healthcare data organization consolidating clinical and operational feeds into one analytics platform, with these constraints:
- Census and staffing data must be correct by 6 a.m. every day
- Every reported number must be traceable to its source for audit
- Hard stop on serving a dataset that fails a quality gate
Step 1: Define SLAs With the Consumers
Sit with the people who use each dataset and write down the freshness and accuracy they actually need.
- SLA document per critical dataset
- Named consumer and named owner for each
- Agreed escalation when an SLA is missed
Step 2: Instrument Quality Checks at Each Layer
Add schema, volume, and distribution checks at ingestion, transformation, and serving. Fail closed on critical gates.
- dbt tests in version control
- Volume and null-rate gates before serving
- A failing critical gate blocks publication
Step 3: Capture Lineage and Impact
Wire lineage from the orchestration layer so any failure shows its downstream blast radius.
- Automated lineage capture
- Impact analysis on schema changes
- Ownership attached to every node
Step 4: Build Detection and Routing
Alerts go to the dataset owner with severity tied to blast radius, not to a shared channel nobody reads.
- Anomaly and threshold alerts
- Owner-routed, severity-tagged
- Daily review of the alert log in the first month
Step 5: Run Incidents Like an SRE Team
Each critical pipeline has a runbook. Failures get a postmortem and a new check.
- Per-pipeline runbook with rollback and backfill
- Consumer communication during incidents
- Postmortem that adds the missing assertion
Where It Works Well
- SLAs agreed with consumers and reviewed quarterly
- Quality gates that fail closed on critical datasets
- Lineage that makes impact analysis a query, not an investigation
Where It Does Not Work Well
- Checks that only warn and never block
- Alerts routed to a shared inbox with no owner
- Lineage maintained by hand and perpetually stale
Key Takeaway: The pipeline that survives in production is the one whose SLA and runbook were written before the first transformation shipped.
Common Pitfalls
i) Checks that warn but never block
A quality check that only logs a warning lets bad data flow downstream while everyone assumes the green dashboard means healthy.
- Fail closed on critical datasets
- Reserve warn-only for low-blast checks
- Document why any critical check is warn-only
ii) No dataset ownership
A dataset with no owner is a dataset with no SLA and no one to page. Ownership is the precondition for reliability.
iii) Lineage maintained by hand
Hand-drawn lineage diagrams are stale the day after they are drawn. Capture lineage from the orchestration layer or do not rely on it.
iv) No tested backfill
A backfill procedure you have never run is a procedure you do not have. Test it. Document the runtime and the blast radius.
Takeaway from these lessons: Most data incidents trace to missing contracts and ownership, not to clever bugs. Design the SLA and the runbook before the pipeline.
Data Reliability Engineering Best Practices: What High-Performing Teams Do Differently
1. Treat datasets as products with contracts
Every critical dataset has a named owner, a documented SLA, and consumers who agreed to it. The contract is the foundation of reliability.
2. Make quality checks declarative and versioned
Assertions live in version control next to the transformation code. Changes go through review. Drift is visible.
3. Fail closed on critical data
A dataset that fails its gate does not get served. A wrong number that never publishes is cheaper than one that reaches a clinician.
4. Capture lineage automatically
Lineage from the orchestration layer, not a wiki page. Impact analysis becomes a query you can run before any change.
5. Operate data like infrastructure
On-call rotation for critical pipelines, runbooks, tested backfills, quarterly SLA review. Treat the platform like a production system, not a reporting tool.
Logiciel'svalue add is helping teams define data SLAs, instrument quality gates, capture lineage, and stand up an incident process, so the platform ships as a dependable product rather than a stack of fragile pipelines.
Takeaway for High-Performing Teams: Focus on contracts, ownership, and incident discipline. Coverage without contracts is monitoring theater.
Signals You Are Designing Data Reliability Engineering Correctly
How do you know the data reliability engineering program is set up to succeed? Not in a board deck or a celebration, but in the daily evidence the team produces. Below are the signals that distinguish programs on the path from programs that look like progress.
- The team can describe the last three data incidents without flinching. People who actually run reliable data platforms will tell you what broke and what check they added. People who have only bought a tool will not.
- Every critical dataset has a named owner. Ask who owns the census table and you get a name, not a shrug.
- Recovery is boring. Backfills and rollbacks follow a runbook that has been tested, not improvised at 3 a.m.
- Quality checks block, not just warn. A failed gate stops publication, and the team can show you the last time it did.
- Lineage is queryable, not hand-drawn. The team can show downstream impact of a change in seconds.
Adjacent Capabilities and Connected Work
This work does not exist in isolation. Data Reliability Engineering depends on, and feeds into, several adjacent capabilities. Building one without thinking about the others is the most common scoping mistake.
In most enterprise programs, data reliability engineering shares infrastructure with the data platform, the orchestration layer, and the security and compliance review process. It shares team capacity with platform engineering, analytics engineering, and SRE. And it shares leadership attention with whatever the next analytics or AI initiative is on the roadmap. Naming these adjacencies upfront helps the program scope realistically and helps leadership see the work as a portfolio rather than a one-off project.
The most common mistake in adjacent-capability scoping is treating each adjacency as someone else's problem. The integration with the orchestration layer is your problem. The compliance review of data provenance is your problem. The on-call rotation that covers the pipelines you ship is your problem. Pretending otherwise pushes work to teams that did not plan for it, and the work returns to you later as a delay or a bad number in a clinical report. Own the adjacencies you depend on; partner with the teams that own them; share the timeline.
Conclusion
Data reliability engineering is what turns a data platform into something decisions can safely rest on. The discipline that makes data trustworthy is the same discipline that made systems dependable: define, measure, and operate.
Key Takeaways:
- Data reliability is a system of contracts, checks, lineage, and response, not just monitoring
- Every critical dataset needs an owner and an agreed SLA
- Fail closed on critical data, capture lineage automatically, and run incidents like an SRE team
Building effective data reliability requires contracts, checks, and incident discipline. When done correctly, it produces:
- Reporting and automation that survive audit and scale
- Bounded blast radius when a pipeline fails
- Reusable reliability patterns for the next dataset
- Defensible provenance in regulator and board conversations
Insurer Builds Fully Auditable Enterprise AI
An audit-readiness playbook for Chief Risk Officers in regulated insurance markets.
What Logiciel Does Here
If you are scoping a data reliability program, define SLAs with your consumers, instrument quality gates that fail closed, and capture lineage before adding another pipeline.
Learn More Here:
At Logiciel Solutions, we work with Chief Data Officers on data SLA design, quality instrumentation, and incident operating models. Our reference patterns come from production data platform deployments.
Explore how to make your data platform dependable.
Frequently Asked Questions
What is data reliability engineering?
The practice of applying software reliability discipline to data. You define SLAs, run continuous quality checks, capture lineage, detect failures, and recover through a documented incident process.
How is it different from data observability?
Observability is the detection and monitoring part. Data reliability engineering is the broader practice that adds contracts, ownership, and incident response around the observability signal.
What is a data SLA?
An agreement on freshness, completeness, and accuracy for a dataset, made with the consumers who depend on it, including the escalation when it is missed.
Should quality checks block or just warn?
Critical datasets should fail closed. A wrong number that never publishes is far cheaper than one that reaches a decision maker. Reserve warn-only for low-blast checks.
What is the biggest mistake in data reliability?
Shipping pipelines with no owner, no SLA, and no runbook, then discovering the gaps during an incident when a bad number has already driven a decision.