

Drift is no longer an edge case. It is inevitable.
Most engineering leaders have seen machine learning models degrade over time due to:
- Changing user behavior
- Evolving data distributions
- External market shifts
But the real issue is not just the model. It is the data architecture.
Without systems that detect and adapt to drift, models continue running while dashboards appear healthy. The failure remains hidden until it impacts the business.
This guide explains how to design data architectures that detect, respond to, and adapt to drift, using practical system-level patterns.
Evaluation Differnitator Framework
Why great CTOs don’t just build they evaluate. Use this framework to spot bottlenecks and benchmark performance.
What is Drift?
Drift occurs when the statistical properties of data change over time, reducing model accuracy.
Types of Drift:
- Data Drift: Input data distribution changes
- Concept Drift: Relationship between input and output changes
- Prediction Drift: Model outputs shift unexpectedly
Common Causes:
- Changes in user behavior
- Seasonal trends
- External market factors
- Data pipeline issues
Key takeaway: Drift is unavoidable. The goal is to detect and respond early.
Why Traditional Architectures Fail
Most traditional systems were not designed for AI-driven environments.
Common limitations:
- Batch-only processing
- Static data pipelines
- Limited observability
- No feedback loops
Result:
- Drift goes undetected
- Model performance declines
- Business decisions degrade
Example: A recommendation model trained on last year’s data continues running without retraining. User behavior shifts, but no alert is triggered.
Key takeaway: Traditional systems optimize storage, not intelligence.
What is Modern Data Architecture?
Modern data architecture is designed for change, scalability, and real-time intelligence.
Core principles:
- Decoupled systems
- Scalable compute and storage
- Real-time + batch processing
- AI-first design
Typical components:
- Data ingestion pipelines
- Storage (data lake + warehouse)
- Processing engines
- Feature stores
- Model serving layer
- Monitoring and observability
Key takeaway: Modern systems are built to adapt, not remain static.
Architectural Principles to Prevent Drift
1. Continuous Data Monitoring
Track:
- Data distribution changes
- Feature values
- Anomalies
2. Feedback Loops
Capture:
- Model predictions
- Actual outcomes
- Performance metrics
3. Real-Time Processing
Enable:
- Streaming data ingestion
- Near real-time updates
- Faster response to drift
4. Version Everything
Maintain versions of:
- Data
- Models
- Features
Key takeaway: Observability and adaptability are the foundation of drift-resistant systems.
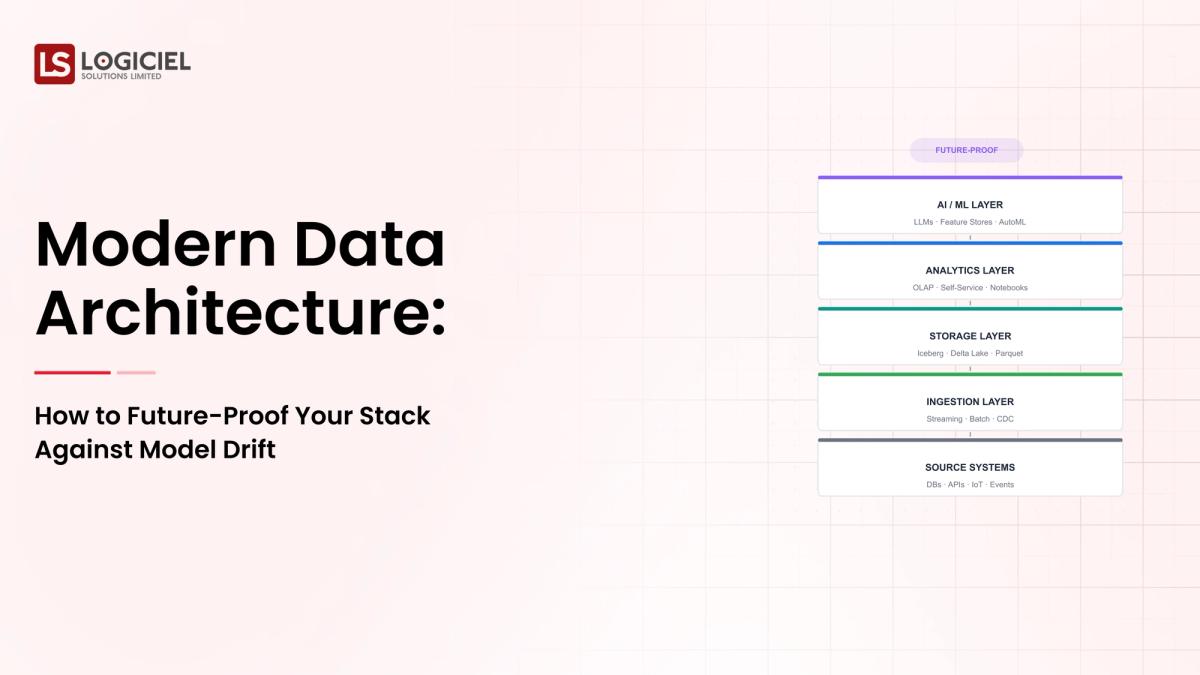
Layered Architecture for Drift-Resilient Systems
1. Data Ingestion Layer
- Supports batch and streaming data
- Validates data quality
- Handles schema evolution
2. Storage Layer
- Data lake for raw data
- Data warehouse for structured data
3. Processing Layer
- Batch and streaming transformations
- Feature engineering
4. Feature Store
- Stores reusable and real-time features
- Ensures consistency across models
5. Model Serving Layer
- Low-latency predictions
- Scalable deployment
6. Monitoring & Observability Layer
- Detects drift
- Tracks performance
- Monitors system health
Key takeaway: Each layer should evolve independently without breaking the system.
Why Real-Time Systems Are Critical
Real-time capabilities allow:
- Early drift detection
- Faster response
- Higher model accuracy
Best practices:
- Use event-driven architectures
- Process data incrementally
- Monitor latency and throughput
Key takeaway: Real-time processing is essential for AI systems.
Choosing the Right Tools
Focus on:
- Scalability
- Reliability
- Integration

Tool categories:
- ETL/ELT platforms
- Streaming systems
- Data integration tools
Key takeaway: Tools should support your architecture—not define it.
Real-World Example: Retail Architecture
Use Case:
A retailer needs:
- Personalized recommendations
- Real-time inventory visibility
- Demand forecasting
Architecture:
- Data lake → raw events
- Data warehouse → analytics
- Feature store → ML features
- Streaming pipelines → real-time updates
Drift Management:
- Monitor user behavior changes
- Retrain models dynamically
- Update features continuously
Outcome:
- Better recommendations
- Faster decisions
- Reduced model degradation
Cloud Platforms for Modern Data Architecture
- AWS: Strong infrastructure ecosystem
- Google Cloud: Advanced AI and analytics
- Azure: Enterprise integration
Selection depends on:
- Workload type
- Team expertise
- Existing ecosystem
Key takeaway: Architecture matters more than platform choice.
What is Data Mesh?
A decentralized model where teams own their data as products.
Benefits:
- Scalability
- Faster development
- Clear ownership
Challenges:
- Governance
- Standardization
Key takeaway: Data mesh scales well but requires discipline.
Common Mistakes to Avoid
- Over-centralizing systems
- Using too many tools
- Lack of ownership
- Static pipelines
Key takeaway: Most failures are organizational, not technical.
Future of Data Architecture
Key trends:
- AI-first infrastructure
- Self-healing systems
- Unified platforms
- Data-centric AI
Key takeaway: Future systems will be adaptive and automated.
Conclusion
Drift is not a failure. It is a signal that your system is evolving.
The real question is whether your architecture can evolve with it.
Modern data systems are not built for stability—they are built for continuous change.
Logiciel POV
At Logiciel Solutions, we help engineering teams design AI-first data architectures that detect drift early, adapt in real time, and scale without complexity.
Our systems combine observability, automation, and intelligent pipelines to ensure your data and models stay reliable as conditions change.
Explore how we can help you build resilient, future-ready data systems.
AI Velocity Blueprint
Measure and multiply engineering velocity using AI-powered diagnostics and sprint-aligned teams.
Frequently Asked Questions
What is modern data architecture?
A scalable, modular system designed for analytics, real-time processing, and AI workloads.
What are its key components?
Ingestion, storage, processing, feature engineering, model serving, and monitoring.
Which cloud platforms are commonly used?
AWS, Google Cloud, and Azure are the most widely used.
How do you design a drift-resistant architecture?
Use modular systems, real-time pipelines, monitoring, and feedback loops.
What is the benefit of data mesh?
Improves scalability and ownership but requires strong governance.

