


Deploying a single AI agent into production is an engineering exercise. Scaling AI agents across an organization is an operating model transformation.
Many companies successfully launch an isolated agent that accelerates code review, summarizes support tickets, or analyzes logs. Very few successfully scale agentic systems across engineering, product, DevOps, and operations in a coordinated, sustainable way.
Scaling is not about increasing token throughput. It is about integrating probabilistic reasoning into workflows without destabilizing reliability, cost control, and team alignment.
For CTOs, the strategic question becomes organizational. How do you design teams, processes, and engineering practices to support widespread agent adoption while preserving architectural discipline?
This cluster examines how AI agents scale across engineering organizations, how workflows must adapt, how teams must be structured, and how AI-first operating models emerge in modern SaaS environments.
AI – Powered Product Development Playbook
How AI-first startups build MVPs faster, ship quicker, & impress investors without big teams.
From Tool Adoption to Workflow Integration
The first stage of AI adoption typically looks like tool usage. Individual engineers experiment with agents for code suggestions. DevOps teams test log analysis automation. Support teams explore AI-assisted replies.
This phase is decentralized and informal. It generates enthusiasm but also fragmentation.
Scaling requires moving from tool usage to workflow integration.
Workflow integration means embedding agents into defined steps of the software development lifecycle. Instead of engineers occasionally consulting an AI tool, the agent becomes part of the process.
For example, in a structured workflow, every pull request may automatically trigger an AI review layer. Every CI failure may automatically pass through an agentic diagnostic stage before human triage. Every support ticket may first be analyzed and categorized by an AI agent before routing.
Scaling requires systemic embedding rather than ad hoc experimentation.
The AI-First Engineering Lifecycle
When agents are integrated properly, they span the entire engineering lifecycle.
During product planning, agents can synthesize user feedback, cluster feature requests, and generate structured requirement drafts.
During development, agents can assist with code scaffolding, documentation generation, and static analysis augmentation.
During testing, agents can generate edge-case scenarios and interpret test failures.
During deployment, agents can analyze CI/CD logs and identify potential rollback conditions.
During operations, agents can monitor anomaly patterns and propose remediation hypotheses.
The result is not replacement of engineers. It is compression of cognitive overhead.
An AI-first lifecycle treats reasoning systems as augmentation layers embedded at every stage.
Organizational Design in AI-Scaled Teams
Scaling AI agents requires structural alignment across teams.
Engineering must own architecture integrity, tool schema discipline, and observability maturity.
Security must oversee guardrail enforcement, permission auditing, and anomaly detection.
Product must define workflow boundaries and measure outcome quality.
Leadership must define autonomy thresholds and risk tolerance.
Without cross-functional ownership, AI scaling becomes fragmented.
Some organizations create dedicated AI reliability engineering roles. These engineers focus on prompt regression testing, tool interface auditing, and observability optimization. Others embed AI specialists within existing teams.
Regardless of structure, ownership must be explicit.
Managing Cultural Resistance and Skill Evolution
Scaling AI agents introduces cultural friction.
Engineers may fear skill erosion. Teams may resist automation perceived as oversight. Others may over-trust AI outputs.
CTOs must address both extremes.
AI agents are not substitutes for engineering judgment. They are reasoning accelerators.
Teams must evolve from execution-focused roles to oversight-focused roles. Engineers increasingly design workflows, validate outputs, and refine guardrails rather than manually performing repetitive tasks.
Training becomes essential. Engineers must understand probabilistic reasoning limitations, tool schema constraints, and governance boundaries.
Cultural scaling is as important as technical scaling.
Measuring Productivity Gains at Organizational Scale
Scaling AI agents requires measurable impact.
Productivity metrics must align with workflow outcomes rather than superficial indicators.
Reduction in pull request review time is meaningful if code quality remains stable. Decrease in incident resolution time is meaningful if reliability improves. Faster ticket categorization is meaningful if escalation accuracy remains high.
CTOs should track cycle time compression, intervention ratio reduction, and defect rate stability.
Avoid vanity metrics such as total prompts executed or lines of code generated.
Scaling success is measured by sustained delivery velocity without reliability degradation.
Avoiding Shadow AI and Fragmentation
When AI adoption is decentralized, shadow usage emerges. Engineers integrate external tools without governance oversight. Prompt libraries proliferate without version control. Tool permissions expand without auditing.
Scaling requires centralization of governance without stifling experimentation.
Organizations should establish approved agent frameworks, shared prompt repositories with versioning, standardized tool interfaces, and observability dashboards.
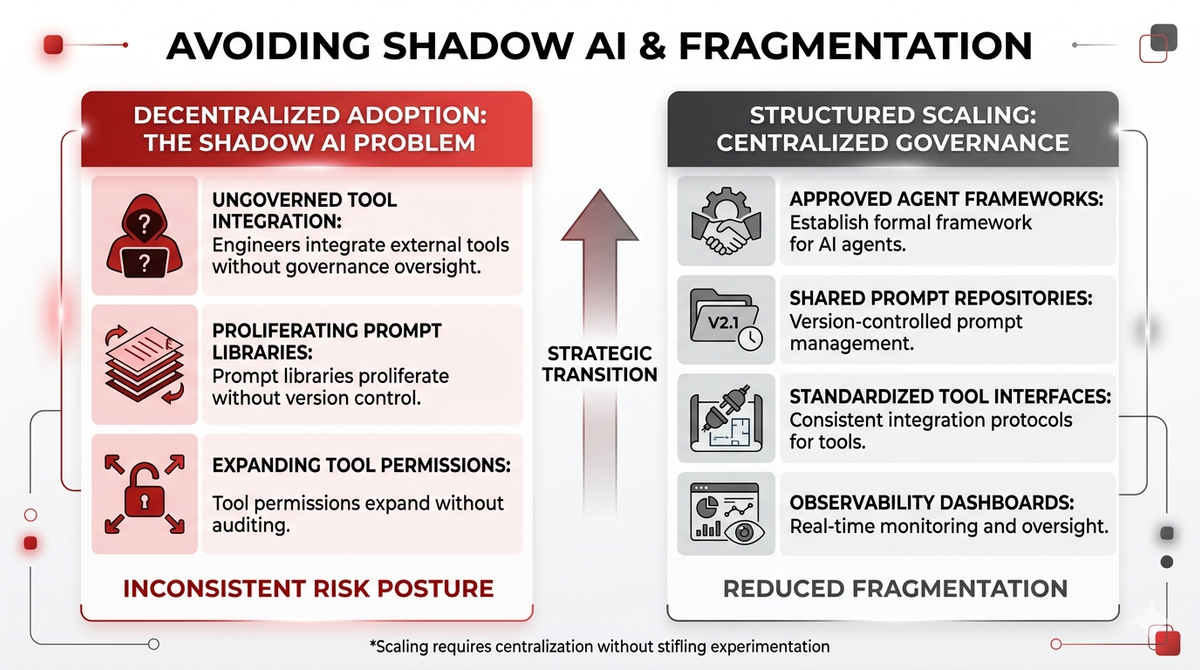
Shadow AI introduces inconsistent risk posture.
Structured scaling reduces fragmentation.
Multi-Team Coordination and Agent Reusability
As adoption increases, multiple teams may build similar agents independently.
For example, engineering builds a log analysis agent. Operations builds a monitoring summarization agent. Support builds a customer issue classifier.
Without coordination, redundancy increases and architectural inconsistencies emerge.
CTOs should promote reusable agent components.
Shared memory systems, standardized tool interfaces, and centralized orchestration frameworks reduce duplication.
Agent platforms should be treated as internal infrastructure rather than isolated team projects.
Managing Cost at Scale
Scaling AI agents across teams increases token consumption and compute load.
Cost governance must scale accordingly.
Per-workflow cost tracking should be implemented. Teams should understand economic impact of reflection loops and retrieval overhead.
Budget allocation models may include cost attribution by department or tenant.
Scaling without cost transparency leads to financial unpredictability.
Economic discipline ensures sustainability.
Observability and Scaling Confidence
Confidence in autonomy increases only with observability maturity.
As more workflows integrate agents, reasoning trace volume grows. Tool call logs expand. Behavioral anomaly detection becomes more complex.
Centralized observability platforms should aggregate agent metrics across teams.
Dashboards should display autonomous completion rates, intervention ratios, and cost trends at organizational level.
Scaling without observability leads to blind spots.
Visibility enables confidence.
Progressive Autonomy at Organizational Scale
Autonomy should not scale uniformly across all workflows.
Low-risk cognitive tasks may operate with high autonomy. High-risk financial or infrastructure operations should remain bounded or supervised.
Organizations should classify workflows by risk tier.
Tier one workflows may operate autonomously with monitoring.
Tier two workflows may require conditional autonomy with escalation triggers.
Tier three workflows may require human approval.
Scaling requires risk stratification rather than blanket autonomy.
Integration with Existing Engineering Toolchains
AI agents should integrate seamlessly with existing engineering ecosystems.
Version control systems, CI/CD pipelines, monitoring platforms, ticketing systems, and communication tools should expose structured APIs for agent interaction.
Integration reduces friction and encourages adoption.
Agents embedded within familiar workflows are more likely to be used consistently.
Scaling is not about adding new interfaces. It is about enhancing existing ones.
SaaS-Specific Scaling Considerations
For SaaS organizations, multi-tenant environments introduce complexity.
Agents operating across tenants must enforce strict data isolation.
Memory retrieval systems must segment by tenant identifier.
Cost attribution should reflect tenant-level usage.
Agents embedded in customer-facing workflows must maintain performance consistency across varying workloads.
Scaling across SaaS platforms requires strict isolation discipline.
Failure Modes at Organizational Scale
Scaling introduces new failure modes.
Tool schema inconsistencies across teams may cause execution errors.
Prompt divergence may lead to unpredictable behavior.
Overconfidence in agent outputs may reduce critical review in early phases.
Cost amplification may outpace perceived benefit.
Governance frameworks must address these risks proactively.
The AI-First Operating Model
As adoption matures, organizations transition toward AI-first operating models.
In this model, agents are embedded by default into engineering workflows. Documentation is structured to support retrieval. APIs are designed for machine interpretability. Observability includes reasoning metrics alongside system metrics.
AI becomes a structural layer rather than an optional enhancement.
This transition requires deliberate design.
Strategic Outlook for CTOs
Scaling AI agents across engineering organizations is not about deploying more models. It is about redesigning workflows, governance structures, and cultural expectations.
Agents compress cognitive overhead and increase delivery velocity when embedded properly.
They create fragmentation and instability when deployed without coordination.
CTOs must treat scaling as organizational transformation.
Architecture, governance, culture, cost control, and observability must evolve together.
The difference between isolated success and structural advantage lies in operating model maturity.
Closing Perspective
AI agents can transform engineering productivity. But transformation does not occur through experimentation alone.
Scaling requires structured integration into workflows, cross-functional governance alignment, economic discipline, and observability maturity.
Agents amplify the operating model they inhabit.
A disciplined organization becomes more efficient.
A fragmented organization becomes more chaotic.
For CTOs, scaling AI agents is less about technology and more about system design at the organizational level.
RAG & Vector Database Guide
Build the quiet infrastructure behind smarter, self-learning systems. A CTO’s guide to modern data engineering.

