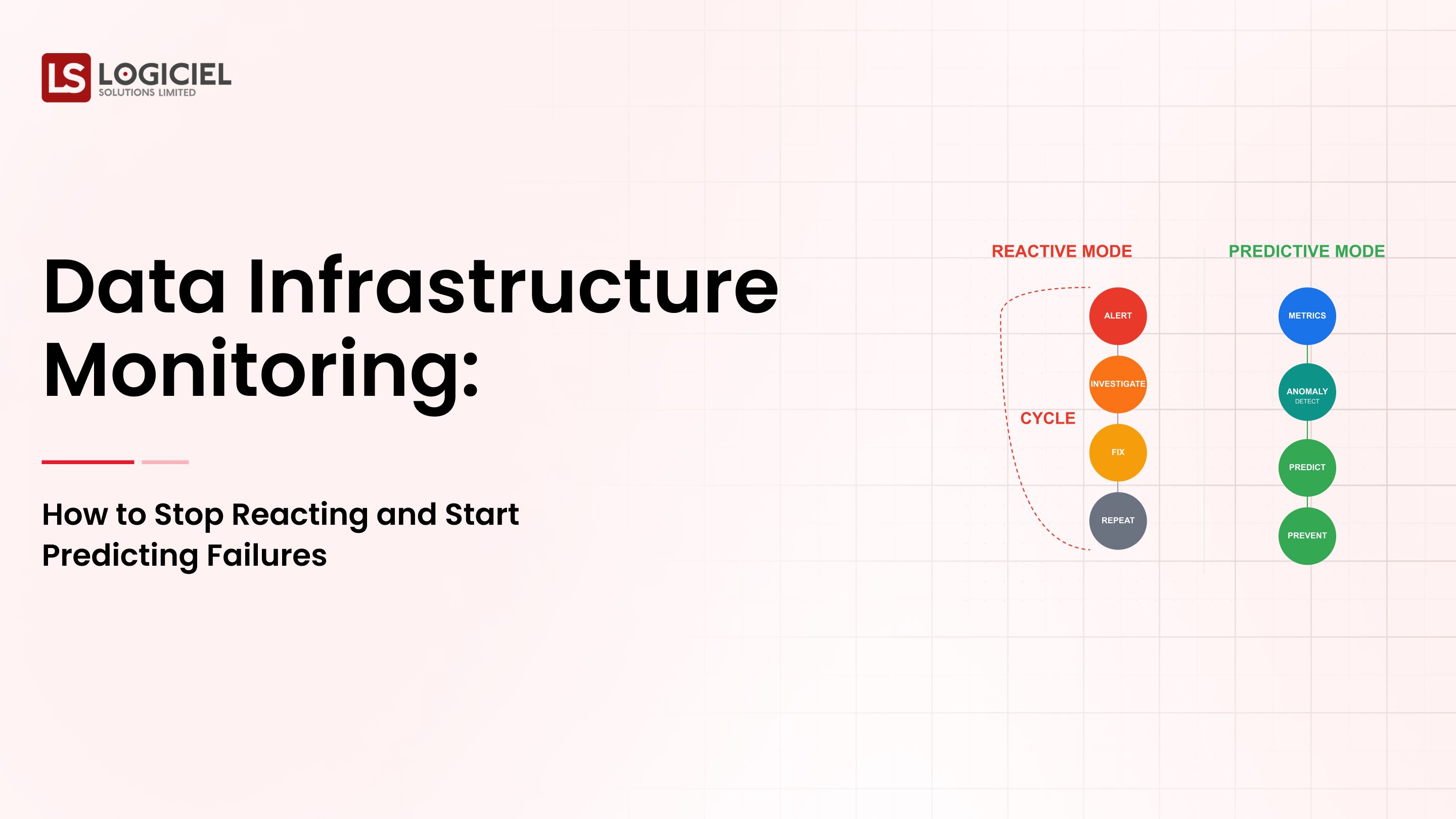
What is a data lake? Do I need to use one?
A data lake is a centralised storage solution that is designed to house huge amounts of information in its original format, and, unlike traditional systems, does not require you to define the data structure ahead of time prior to placing the data into storage.
The reason why this is an important question for the Data Engineering Team Lead is because of its impact on:
- Scalability of data
- Preparing for AI
- Cost structure
- Speed at which the team will produce results
Therefore, data lakes can no longer be considered just as storage, they serve as the basis for AI-centric modern data platforms.
its main advantages
Data lakes allow you to:
- Store all forms of data (structured, semi-structured, and unstructured)
- Process using schema-on-read
- Scale at low-cost
Why is Data Storage so Important?
At some point, all data storage solutions reach some limitations.
- Data warehouses may be too rigid.
- ETL processes may slow down innovation.
- AI teams may want to obtain data in its raw format (which you do not have).
This is where we have to get into Architecture vs. Optimization, and thus, we need to ask ourselves:
AI – Powered Product Development Playbook
How AI-first startups build MVPs faster, ship quicker, & impress investors without big teams.
This will be your comprehensive guide to:
- Understanding what a data lake is and how it operates
- Developing a solution for when you should consider a data lake
- Creating an architecture for developing a data lake
- Identifying best practices for your enterprise/business team
- Identifying common data lake pitfalls and how to avoid these
When are data lakes used?
Organisations use data lakes when they need:
- To be able to implement many different data use cases
- To support machine learning and AI workloads
- To be able to ingest large amounts of fast-moving data
Why woud we use data lakes in today's architecture?
- Organisations have traditionally built systems to generate reports
- Today's architecture needs to support predicting outcomes, automating decisions, and making intelligent decisions
Data lakes allow for the transition between the two.
4 significant influences of using data lakes
1) Explosion of data sources
Applications, sensors, APIs, and logs are generating large amounts of data.
2) Machine learning and artificial intelligence needs
ML and AI require large volumes of diverse data.
3) Cost efficiency
Object storage is much cheaper than warehouse storage.
4) Real-time analytics
Streaming pipelines require flexible storage.
How does a data lake function?
The data lake is built around a very simple but powerful concept:
Your data is stored first, it is processed later.
One of the main components of a data lake is the way you store all your data in a flat file structure (schema-on-read). You do not define the structure of your data until you request it through an analytics application.
Data lake architecture
Core Layers
- Data Ingestion Layer
- Batch Ingestion
- Stream Ingestion
- Data Storage Layer
- Object Storage
- Data Processing Layer
- Distributed Processing Engines
Access Layer
The "access layer" incorporates components such as "query engines" and "APIs" that provide an interface for users accessing the data in the data lake.
Data can be queried using various engines such as Spark or SQL based tools.
Core Components
- Storage (e.g. S3, ADLS/GCS)
- Compute (e.g. Spark, Databricks)
- Metadata layer
- Governance tools

Three-Zone Architecture
- Raw
- Processed
- Curated
This structure supports data quality, governance, and performance.
Overall: A data lake is not designed to replace a data warehouse. The trend is toward combining these into a "lake house".
How to Build a Data Lake
Phase 1 - Identify use cases
Analytics, AI/ML, storage.
Phase 2 - Cloud Platform Selection
AWS, Azure, GCS.
Phase 3 - Data Input Pipeline Design
Batch + streaming ingestion.
Phase 4 - Data Governance
Metadata, access, lineage.
Phase 5 - Enabling Data Querying
SPARK, PRESTO, ATHENA.
How do you build a Data Lake using Azure or AWS?
Azure
- ADSL
- ADF
- SYNAPSE
AWS
- S3
- GLUE
- ATHENA
Where to access and query data
- SQL engines
- APIs
- BI tools
How do you query data from your data lake?
- Distributed query engines
- Optimized partitioning
- Columnar formats
Capabilities
- Stream ingestion
- Low latency processing
- Real-time operations
Technologies
- Kafka
- Spark Streaming
- Flink
Security and governance features
- Data Encryption
- Role-Based Access Control
- Data Masking
Best Practices
- Zero Trust Model
- Audit Logs
- Centralized Identity
Cost Considerations
Factors
- Data volume
- Compute usage
- Data transfer
Optimization
- Multi-Tier Storage
- File Format Optimization
- Auto provisioning
Common Causes of Data Lake Failure
- Weak governance
- Poor data quality
- Lack of ownership
Disadvantages of Data Lakes
- Complexity
- Risk of data swamp
- High maintenance cost
Evolution
- Lakehouses
- Unified Platforms
Best Practice for Enterprise Data Lakes
- Treat Data as a Product
- Prioritize Governance
- Design for Performance
- Interoperability
Data Lake's Future
- Lakehouse growth
- AI-first platforms
- Unified analytics
What This Means For Engineering Departments
- Automation
- Governance
- AI integration
Conclusion: Transitioning Data Lakes From Storage Layer to Strategic Asset
The Data Lake Has Evolved From A Repository, To Now Being A Strategic Asset In The Modern Data World.
Data Engineering Leads must build systems that are:
- Scalable
- AI-ready
- Governed
At Logiciel Solutions, We Assist Engineering Teams To Design & Build AI Based Data Platforms by providing An Agile, Reliable, Scalable Data Lake To Full Scale Analytic Ecosystems Delivering Measurable Outcomes.
When Considering Your Next Data Architecture Change, You Cannot Afford To Make A Mistake When Designing Your Data Lake.
AI Velocity Blueprint
Measure and multiply engineering velocity using AI-powered diagnostics and sprint-aligned teams.
Frequently Asked Questions
What Is A Data Lake And How Does It Work?
A Data Lake Is A Centralized Storage System, That Stores Raw (Unprocessed) Data From Different Data Sources, In Its Original Format. A Data Lake Works By Ingesting Large Amounts of Data From Various Data Sources, Allowing The User To Process And Query The Data At Any Time.
Why Is A Data Lake Important?
Data Lakes Provide One Environment That Enables Large-Scale Storage Of Data Using Scalability, Supports AI Based workloads, Allows Flexible Processing Of Data.
How To Build A Data Lake?
Define Use Cases; Select Platform; Design Pipeline; Implement Governance; Enable Querying.
What Are The Best Cloud Platforms For Building A Data Lake?
AWS, Azure, Google Cloud.
What Are The Disadvantages Of A Data Lake?
Complexity, governance issues, risk of poor data management.